Computer systems can be classified by the way in which the organization of their RAM memory is designed, and therefore in two different groups: UMA system and NUMA systems. We explain the basic differences between these ways of organizing a system according to memory organization and what are the advantages and disadvantages of each type.
When designing a system, one of the first things that is placed on the design table is the way the RAM will be organized, as this will not only indicate what the system architecture will be like, but also its performance, its manufacturing cost and its expandability.

RAM memory organization: UMA
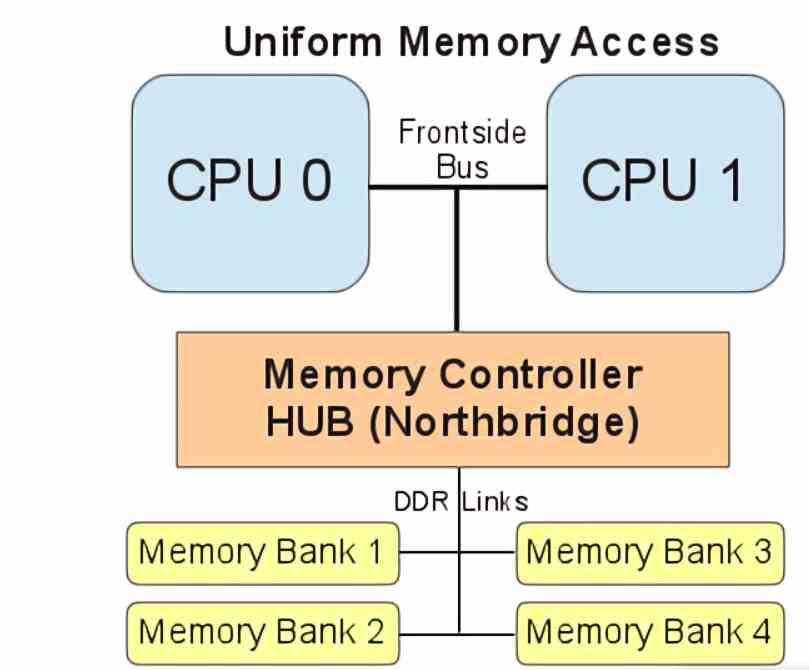
UMA is the acronym for Uniform Memory Access and refers to all systems where RAM is a single shared well in terms of access by the CPU and the rest of the system’s processors. This type of configuration is used especially in SoCs today, where the different components share access to memory.
The UMA system is also the one used in video game consoles, in general it is the memory system used in every system where its components are mounted on a common board, where the routing of two different types of memory wells are a complication on the pathways and communication lines that traverse the plate.
It is therefore the easiest way to build a memory system in any type of computer, but it brings with it a series of problems such as the fact that sharing memory access ends up creating a contention effect, in which it is created a “waiting list” to access data, which can only be alleviated with the use of RAM memory types with various access channels.
RAM memory organization: NUMA
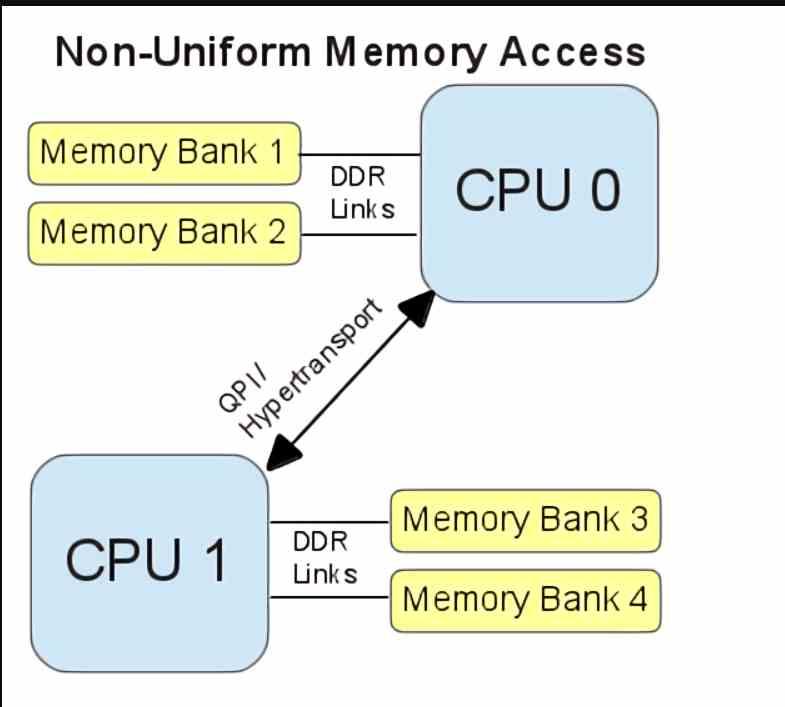
The NUMA or Non-Uniform Memory Access memory organization. Refers to systems in which several different memory wells are used in the same system. This is the case of the PC where, for example, we can see how graphics cards have their own memory different from the main RAM of the system.
NUMA systems do not suffer from the contention problem in memory access of UMA systems, but actually in order to communicate the different components of the system with each other, it results in a very complex system. The reason for this is that each of the components need to have access mechanisms to the main RAM memory for communication with the CPU, for example GPUs have DMA units that allow them to access the main RAM of the system and make copies of certain data from RAM to VRAM.
This type of memory organization is used when we want to create a system with expansion capabilities, for them it is necessary to create what are called expansion ports, which are used for the communication of the system CPU with the RAM memory systems of the system. each component that are part of the system.
Addressing vs. physical organization

One of the ideals in PC is the totally coherent memory system, in which the addressing of the different components in it is common in all of them. This means that if we modify the address, say, for example, F4. Then all the components when going to the memory address F4 any other component of the PC would have to refer to the same memory address.
One might think from the outset that since UMA systems have their memory always shared at the physical level then it will be the same at the addressing level, since we are talking about the same memory pool at the physical level. The reality is quite different, since it is necessary for the different components to be coherent in terms of memory, which means that taking the previous example if we write the value 30 in the address F4 then all the components know that there is a value 30 there.
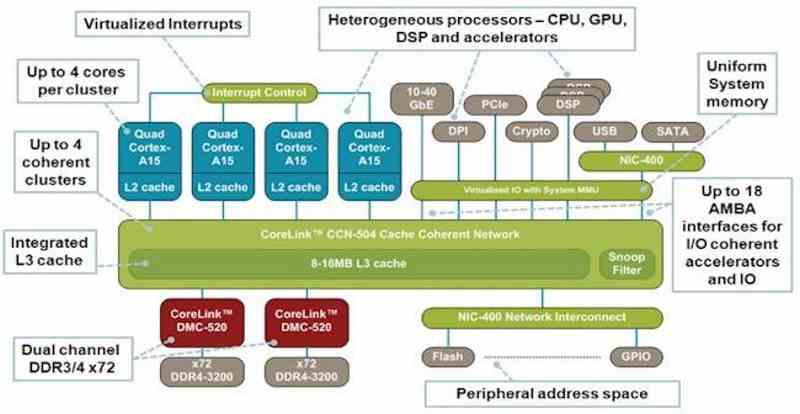
The way to get all the components of an SoC to be totally coherent is therefore not to use the same memory controller, but to add a last cache level just before said controller, which would be beyond the CPU, the GPU. and other components and would be seen by all of them as a last level of cache.
The fact of adding a last level cache before the memory controller is typical of PostPC systems, since all of them were designed for SoCs from the beginning, there are no programs that make copies of data from one space to another. In PC, however, this is not common and although Intel and AMD have been launching SoCs for years where all the components are unified in a single chip, access to the different elements within the SoC is not and parts of the RAM are isolated exclusively for a specific component. For example, when we have an integrated graphic and we are assigning an amount of memory to said graphic, what we are doing is telling the CPU that its space cannot touch it, since it is out of its allocation.