A lot has changed in terms of the architecture of NVIDIA GPUs in the last two decades, but an important turning point was when those in green launched Tesla architecture, back in 2006. In this article we are going to take a look Back to see how the NVIDIA architecture has evolved from Tesla to Turing , the current architecture (in the absence of the arrival of Ampere), and more specifically how its SM (Stream Multiprocessors) have done it.
In this article we are going to review how the NVIDIA architecture has evolved from Tesla to Turing, so it is a good time to get into the background and see what was particular about each of these architectures, which you can find summarized in the following table .

| Year | Architecture | Serie | Die | Lithographic process | Most representative graph |
|---|---|---|---|---|---|
| 2006 | Tesla | GeForce 8 | G80 | 90nm | 8800 GTX |
| 2010 | Fermi | GeForce 400 | GF100 | 40nm | GTX 480 |
| 2012 | Kepler | GeForce 600 | GK104 | 28 nm | GTX 680 |
| 2014 | Maxwell | GeForce 900 | GM204 | 28 nm | GTX 980 Ti |
| 2016 | Pascal | GeForce 10 | GP102 | 16nm | GTX 1080 Ti |
| 2018 | Turing | GeForce 20 | TU102 | 12nm | RTX 2080 Ti |
The stalemate: the pre-NVIDIA Tesla era
Until Tesla’s arrival in 2006, NVIDIA’s GPU design was correlated to the logical states of its rendering API. The GeForce 7900 GTX , powered by die G71, was manufactured in three sections (one dedicated to vertex processing (8 units), another to generate fragments (24 units) and another to join these (16 units)) .
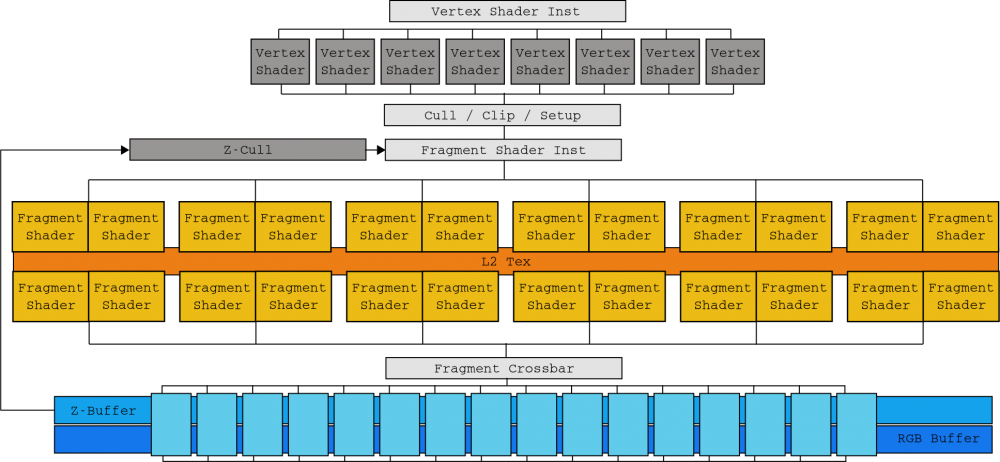
This correlation forced designers and engineers to have to imagine the location of the bottlenecks in order to balance each layer properly. Added to this was the arrival of DirectX 10 with geometry shading, so NVIDIA engineers found themselves between a rock and a hard place to balance the die without knowing when and in what way the next stage of graphical APIs.
It was time to change the way you design your architecture .
NVIDIA Tesla architecture
NVIDIA solved the problem of increasing complexity with its Tesla architecture, the first “unified”, in 2006. With its die G80 there was no longer any distinction between layers. Stream Multiprocessors (SM) replaced all previous drives thanks to their ability to execute vertex processing, shard generation, and shard join without distinction in a single kernel. Thus, in addition, the load is automatically balanced by exchanging the “cores” executed by each SM depending on the needs of each moment.
Thus, the Shader Units are now the “cores” (no longer SIMD compatible) that are capable of handling an integer or float32 instruction by themselves (SMs receive threads in groups of 32 called warps). Ideally, all threads in a warp will execute the same statement at the same time only with different data (hence the name SIMT). The multi-threaded (MT) instruction unit is responsible for enabling and disabling threads on each warp in the event that the instruction pointers (IP) converge or differ.
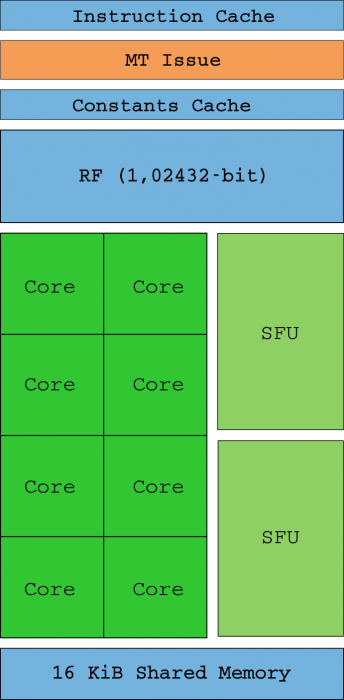
Two SFU units (you can see them in the diagram above) are in charge of helping with complex mathematical calculations such as inverse square roots, sines, cosines, exp and rcp. These units are also capable of executing one instruction for each clock cycle, but since there are only two, the execution speed is divided by four for each of them (that is, there is one SFU for every four cores). There is no hardware support for float64 calculations, and these are done by software, significantly reducing performance.
An SM works at its maximum potential when memory latency can be eliminated by always having programmable warps in the execution queue, but also when the thread of a warp has no divergences (that’s what the control flow is for, which maintains them always in the same path of instructions). The log file ( 4KB RF ) is where the thread states are stored, and threads that consume too much execution queue reduce how many of them can be kept in that log, also reducing performance.
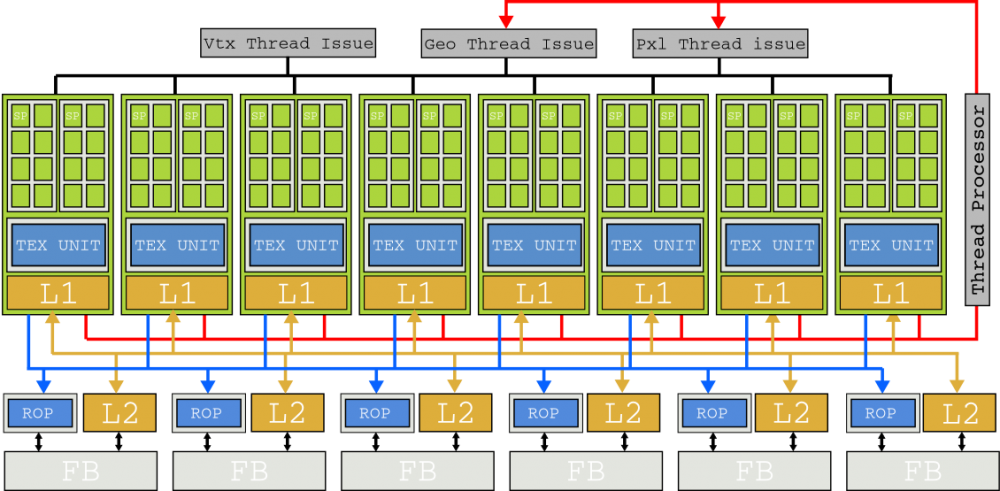
The “flagship” die of this NVIDIA Tesla architecture was the G90 based on a 90 nanometer lithographic process, presented with the famous GeForce 8800 GTX. Two SMs are grouped into a texture processor cluster (TPC) along with a texture unit and Tex L1 cache. With 8 TPCs, the G80 had 128 cores generating 345.6 GFLOPs of gross power. The GeForce 8800 GTX was immensely popular in those days.
With the Tesla architecture, NVIDIA also introduced the CUDA (Compute Unified Devide Architecture) programming language in C, a superset of C99, which was a welcome relief for GPGPU enthusiasts who welcomed an alternative to cheat the GPU with GLSL shaders and textures.
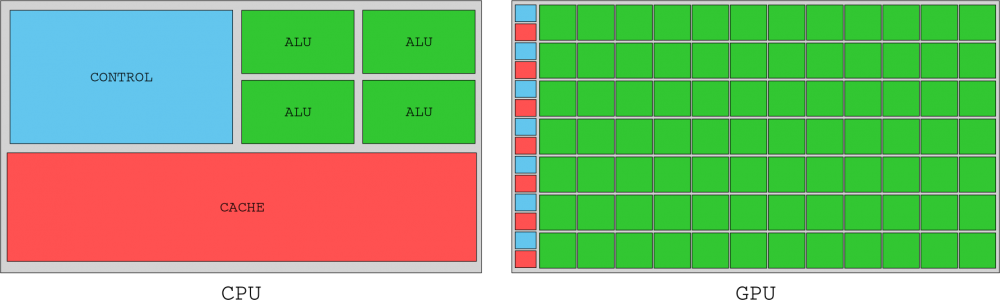
Although this section focused broadly on SMs, they were only half the system. SMs need to be fed with instructions and data residing in the graphics memory of the GPU, so to avoid stagnation, GPUs don’t avoid memory “trips” with lots of cache memory like processors (CPUs) do, rather, they clutter the memory bus for I / O requests from the thousands of threads it manages. For this, high memory performance was implemented in the G80 chip through six bidirectional DRAM memory channels.
Fermi architecture
Tesla was a very risky move but one that turned out to be very good, and it was so successful that it became the foundation of NVIDIA architectures for the next two decades. In 2010, NVIDIA launched the GF100 die based on the new Fermi architecture, with numerous new features inside.
The execution model still revolves around 32-wire warps programmed into an SM, and it was only thanks to its 40nm lithography (vs. Tesla’s 90nm) that NVIDIA quadrupled pretty much everything. An SM can now program two media-warps (16 threads) simultaneously thanks to two sets of 16 CUDA cores. With each core executing one instruction per clock cycle, a single SM was able to execute one warp instruction per cycle (and this is 4 times the capacity of Tesla SMs).

The SFU count was also strengthened, though less because it “just” multiplied by two, with four units in total. Hardware support was also added for float64 calculations, which Tesla lacked, carried out by two combined CUDA cores. The GF100 could do integer multiplication in a single clock cycle thanks to a 32-bit ALU (vs. 24-bit in Tesla) and has higher float32 precision.
From a programming perspective, Fermi’s unified memory system allowed CUDA C to be augmented with C ++ features like virtual objects and methods.
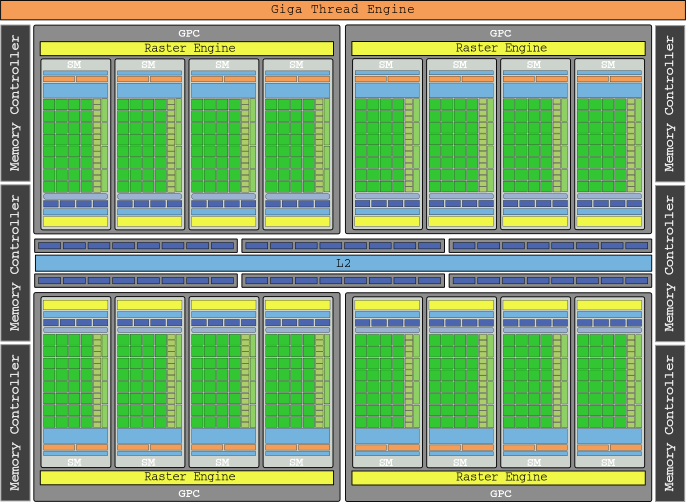
With texture units now part of SMs, the concept of TPC disappeared, replaced by graphics processor clusters (GPCs) that feature four SMs. Last but not least, a “Polymorph” engine was added to handle object vertexes, view transformation, and tessellation. The graphics flagship of this generation was the GTX 480, which with its 512 cores had 1,345 GFLOPs of gross power.
NVIDIA Kepler architecture
In 2012 came the NVIDIA Kepler architecture, with which the energy efficiency of its die was drastically improved by lowering its clock speed and unifying the central clock with that of the card (they used to have a frequency of twice), thus solving the problem of Previous generation GTX 480 (they got very hot and had a very high consumption).
These changes should have resulted in lower performance, but thanks to the implementation of the 28nm lithographic process and the elimination of the hardware programmer in favor of a software one, NVIDIA was able to not only add more SM, but also improve its design. .

The “next-generation streaming multiprocessor,” known as the SMX, turned out to be a monster where almost everything had doubled or even tripled. With four warp programmers capable of processing an entire warp in one clock cycle (compared to Fermi’s two-halved design), the SMX now contains 196 cores. Each programmer has a double dispatch to execute a second instruction in a warp if it is independent of the instruction currently executed, although this double programming was not always feasible.
This approach made programming logic more complicated, but with up to six warp instructions per clock, an SMX Kepler provides twice the performance of a Fermi SM.
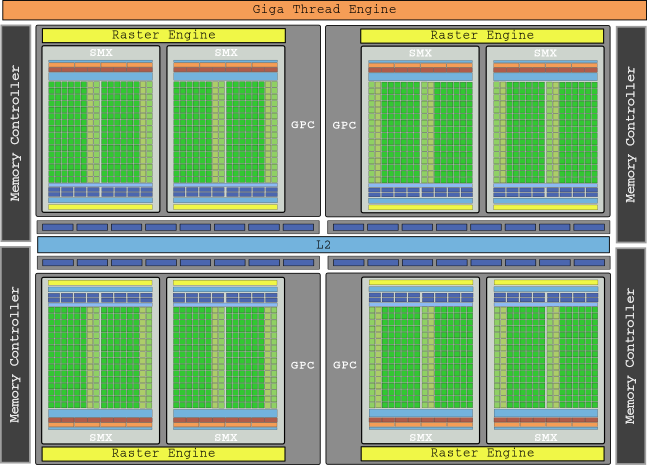
The flagship graphics of this generation was the GeForce GTX 680 with its die GK104 and 8 SMX, which contained the incredible amount of 1536 cores and provided a total of up to 3,250 GFLOPs of gross power.
NVIDIA Maxwell architecture
In 2014 came the NVIDIA Maxwell architecture, its 10th generation GPUs. As they explained in their technical documentation, the heart of these GPUs was “extreme energy efficiency and exceptional performance per watt consumed”, and that is that NVIDIA oriented this generation to limited power systems such as mini PCs and laptops.
The main decision was to abandon Kepler’s approach to the SMX and return to Fermi’s philosophy of working with warps media. Thus, for the first time in its history, the SMM features fewer cores than its predecessor with “only” 128 cores. Having the number of cores adjusted to the size of the warp improved the structure of the die, which resulted in a great saving of occupied space and consumed energy.
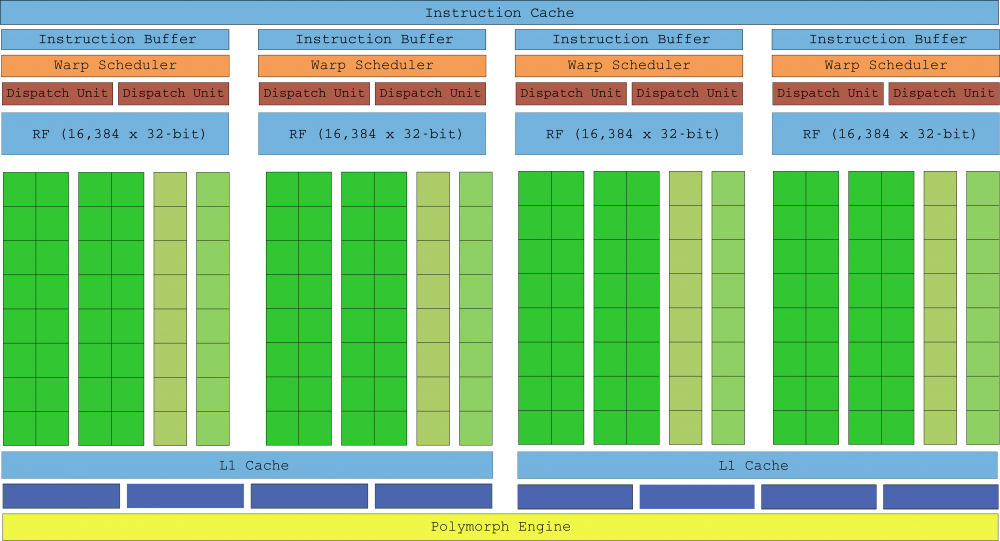
The second generation of Maxwell significantly improved performance while maintaining the energy efficiency of the first generation. With the lithographic process still stagnant at 28nm, NVIDIA engineers could not rely on miniaturization of transistors to improve performance, yet fewer cores per SMM reduced their size, allowing them to fit more SMMs. on the same day. Maxwell Gen 2 contains twice the SMM as Kepler with only 25% more area in its die.
In the list of enhancements we should also mention a more simplified scheduling logic that reduced the redundant recalculation of scheduling decisions, which reduced computation latency to provide better warps occupancy. The memory clock was also increased by 15% on average.
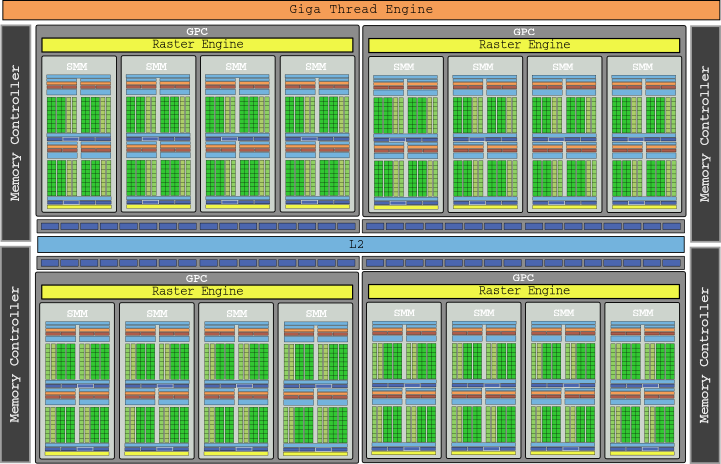
The diagram of the GM200 chip that we see above is almost beginning to hurt the eye, right? It is the die that incorporated the GTX 980 Ti, with 3072 cores in 24 SMM and that provided a gross power of 6,060 GLOPs.
NVIDIA Pascal architecture
In 2016 the next generation, NVIDIA Pascal, arrived, and the technical documentation looked almost like a carbon copy of Maxwell’s SMMs. But just because there are no changes to the SMs doesn’t mean there were no improvements, and in fact the 16nm process used in these chips substantially improved performance by being able to put more SMs on the same chip.
Other important improvements to highlight were the GDDR5X memory system, a novelty that provided transfer speeds of up to 10 Gbps thanks to eight memory controllers, with its 256-bit interface providing 43% more bandwidth than the previous generation .
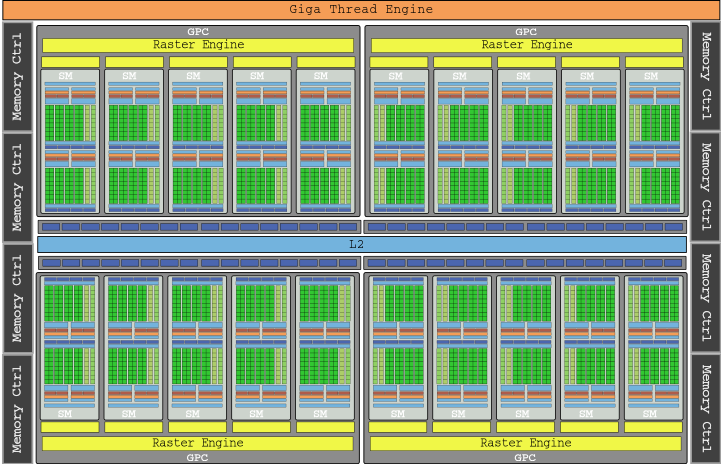
The graphics flagship of the Pascal generation was the GTX 1080 Ti, with its die GP102 that you can see in the image above and its 28 SM, packing a total of 3584 cores for a gross power of 11,340 GLOPs (we are already at 11.3 TFLOPs).
NVIDIA Turing Architecture
Launched in 2018, Turing Architecture was the “biggest architectural leap in more than a decade” (in NVIDIA’s words). Not only were SM Turing added, but dedicated Ray Tracing hardware was first introduced, with Tensor Cores and RayTracing cores. This design assumes that the die was “fragmented” again, in the style of layers of the pre-Tesla era that we told you about at the beginning.
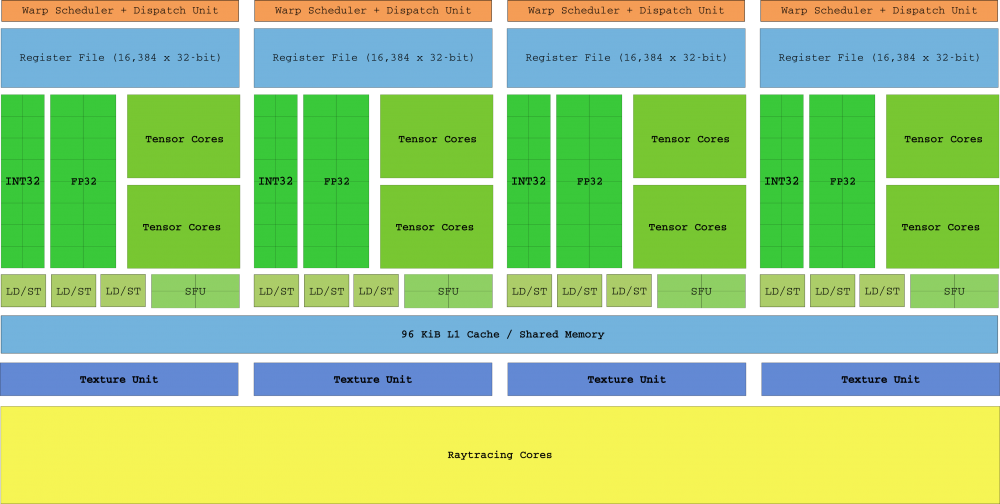
In addition to the new kernels, Turing added three main features: First, the CUDA kernel is now scalable and capable of executing both integer and floating-point instructions in parallel (this will remind many of the “revolutionary” Intel Pentium architecture back there. the year 1996). Second, the new GDDR6 memory system backed by 16 controllers, which can now reach 14 Gbps, and finally the threads that no longer share instruction pointers in warps.
Thanks to the independent thread programming introduced in Volta (which we do not include here since it is a non-user-focused architecture), each thread has its own IP and, as a result, SMs are free to program threads in a warp without the need for wait for them to converge as soon as possible.

The top of the range graphics of this generation is the RTX 2080 Ti, with its TU102 die and 68 TSM containing 4352 cores, with a gross power of 13.45 TFLOPs. We do not put his complete block diagram as in the previous ones because in order for it to fit on the screen, it would have to be shrunk so much that it would be a blur.
And what comes next?
As you well know, the next NVIDIA architecture is called Ampere, and it will surely arrive with the manufacturing node at 7 nm from TSMC. We will update this article as soon as all data is available.