AMD‘s Radeon graphics architectures have seen little change in recent years compared to the competition, as from GCN launched in 2012 we moved to RDNA in 2019, which has had a recent revamp with RDNA. But what has really been the evolution of AMD GPUs? Read on to learn about the architecture changes from GCN to RDNA 2.
While NVIDIA has had many different GPU architectures in recent years, AMD is traditionally more conservative, maintaining the same GPU architecture with minor tweaks for years. We saw it with GCN, which was the AMD GPU architecture for several generations and we are seeing it with RDNA, where the roadmaps already indicate the existence of a future RDNA 3 with fewer changes than those that we are going to see in NVIDIA Lovelace. and Hopper.


But we are not going to look to the future like Prometheus, but to be more of Epimetheus and look both to the past and to the present and we are going to do it in the case of AMD to really know how the different architectures of AMD have evolved. The comparison is not therefore at the level of generations, nor between graphics cards among themselves, but to understand how the evolution from GCN to RDNA 2 has gone.
The evolution from GCN to RDNA
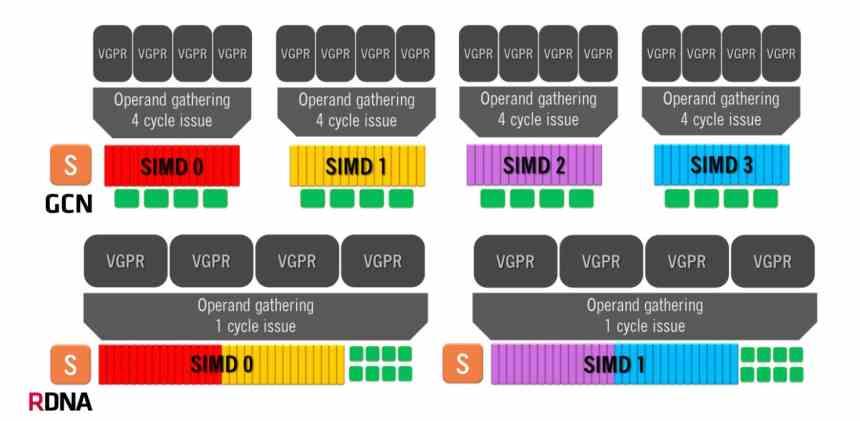
The Graphics Compute Next architecture makes use of a Compute Unit composed of 4 SIMD groups of 16 ALUs each, which handles waves of 64 elements. This means that in the best case scenario, where one instruction is solved per cycle, the GCN architecture is going to take 4 clock cycles per 64-element wave.
On the other hand, RDNA architectures have a different operation, since we have two groups of 32 ALUs and the size of the waves has gone from 64 elements to 32 elements. The same size that NVIDIA uses in its GPUs, so now the minimum time per wave is 1 single cycle because we have all 32 execution units running in parallel. Although the average number of instructions solved is still 64, it is a much more efficient organization.
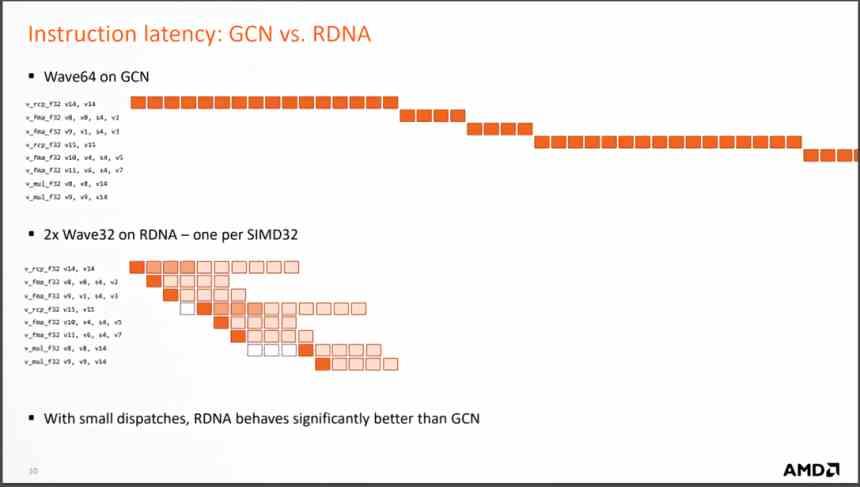
But the most important change is the change when executing the instructions that arrive from each wave, since RDNA solves them in much fewer cycles, which means that the average number of instructions per cycle that are solved is much larger. and with it the average CPI increases.
What does this translate to? Well, since far fewer Compute Units are required to achieve the same performance, fewer Compute Units mean a smaller GPU to achieve the same performance. Actually AMD started doing the RDNA design as soon as they saw a GTX 1080 with “just” 40 SM sweeping the floor with the AMD Vega 64 Compute Units. That was the point at which they saw how the GCN architecture did not give more of itself.
Evolution of the cache system

To understand the evolution from one graphic architecture to another, it is important to know the cache system and how it has evolved from one generation to another.
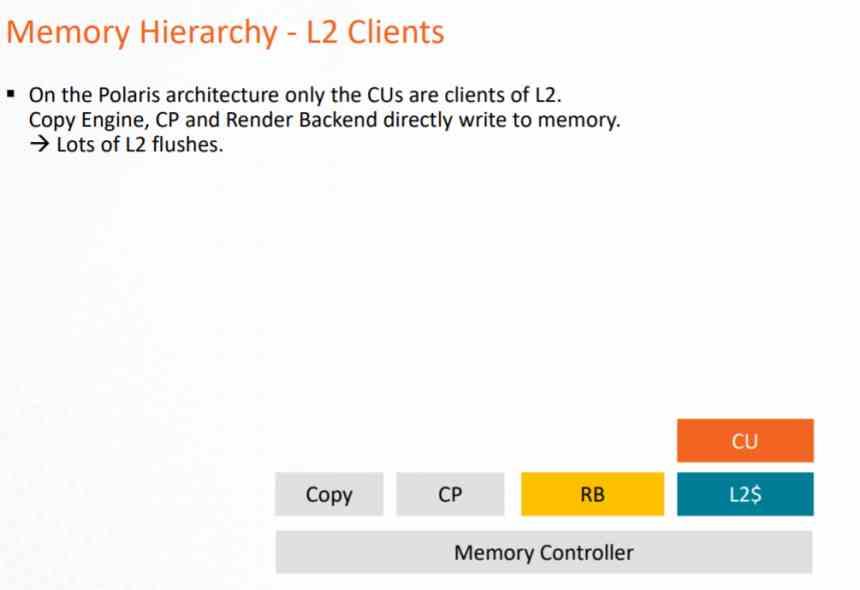
In the GCN architecture, the cache system could only be used by the computing pipeline, since the Pixel Shaders when executed export to the ROPS and these directly on the VRAM, which supposes a very large load on the VRAM and a consumption of very large energy.

This problem was solved at the end of the life of this architecture with AMD Vega, where both the ROPS and the raster unit communicated to the L2 cache in order to reduce the load on the data bus towards the VRAM. But especially to apply the DSBR or Tiled Caching, which consists of adopting the Tile Rendering, but partially and that NVIDIA had already adopted in Maxwell.

In RDNA the main change was to make everything become L2 client, but adding an intermediate cache that is L1, in this way the nomenclature changed.
- The L1 cache included in Compute Units becomes the L0 cache, with the same functionality.
- An L1 cache is added, which is intermediate between the L0 cache and the L2 cache.
- All GPU elements now go through the L2 cache.
All write operations are performed on the L2 cache directly, while the L1 cache is read-only. This is done to avoid implementing a more complex coherence system on the GPU that would occupy a large number of transistors. Since thanks to the read-only L1 cache you can grant the data to several clients within the GPU at the same time.
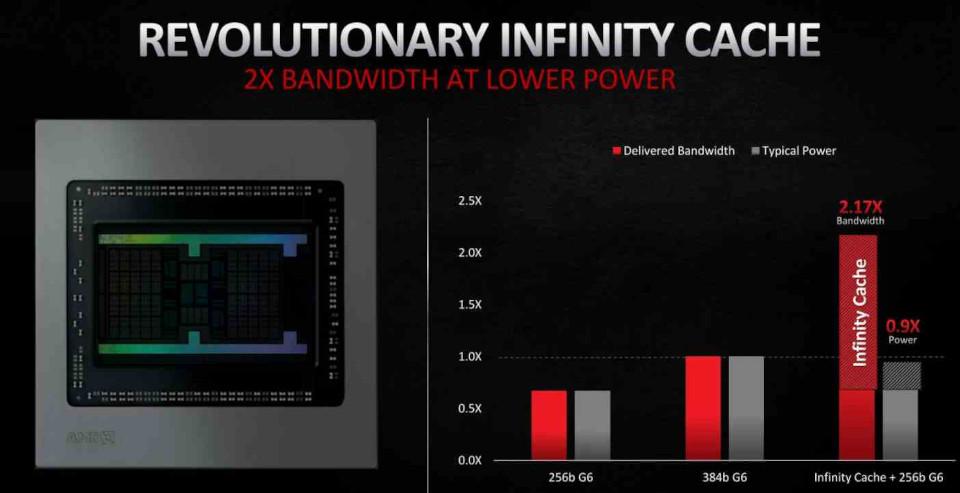
In RDNA 2 the most important inclusion has been in the form of the Infinity Cache, which acts not as a conventional L3 cache but as a Victim Cache, adopting the cache lines discarded by the L2 cache, in this way it is avoided that this data fall into the VRAM, which facilitates its recovery and, as we will see later, it reduces the energy cost of certain operations, which makes it a key element for improvements in RDNA 2.
The location of the data is important with regard to energy consumption. Since the greater the distance that a piece of data has to travel, then the greater the energy consumption. That is where the Infinity Cache comes in, which allows you to operate with the data with a much lower consumption.
RDNA 2, a minor evolution

RDNA 2, on the other hand, is a slightly improved version of RDNA and not a less radical change, so AMD would have returned to the strategy of launching continuous improvements on the same architecture. AMD is said to have released RDNA during the second half of 2019 as a temporary solution while they finished polishing RDNA 2 which is the already finished version of the architecture and fully compatible with DirectX 12 Ultimate.
If we speak in terms of computation, RDNA 2 does not have any advantage over RDNA and the improvements have been made rather in elements other than the part in charge of executing the shaders.
- The texture unit has been improved and a ray intersection unit has been added for Ray Tracing.
- ROPS and raster units have been improved to support Variable Rate Shading.
- The GPU now supports higher clock speeds.
- Inclusion of the Infinity Cache to reduce the energy consumption of certain instructions.
One of the keys to being able to achieve a higher clock speed in a processor is to super-segment the pipeline, but this is something that cannot be done in the shader unit of a GPU in the same way as in a CPU. For what AMD has done internally is to measure the energy consumption of each instruction that the Compute Unit can perform. Since there are instructions that consume less energy, they can be executed at a higher clock speed, this allows reaching higher peak speeds at the time to execute them.