We all know and have worked with file systems like NTFS in Windows, or EXT4 in Linux, however, there are other file systems with different characteristics, operation and performance. Today in this article we are going to talk in detail about the ZFS file system , the best file system for NAS servers where the integrity of the files is one of the most important aspects, without forgetting the protection of data against ransomware. or malfunction of one of the disks. Are you ready to know everything about ZFS?
What is ZFS and what features does it have?
ZFS is a file system that was originally developed by Sun Microsystems for its Solaris operating system, the source code was released in 2005 as part of the OpenSolaris operating system, but this made ZFS usable in other operating systems and environments. At first there were problems with ZFS rights, so it was decided to make different “ports” to adapt it to different operating systems without having licensing problems. In 2013 OpenZFS was launched under the Umbrella project umbrella, in such a way that ZFS could be used without problems in operating systems such as Linux and FreeBSD among others. From this moment, we can find the ZFS file system in FreeBSD, NetBSD, Linux such as Debian or Ubuntu among others.
![]()
The ZFS file system is used natively on FreeBSD-based operating systems, such as the popular FreeNAS or XigmaNAS, two operating systems that are specifically geared for NAS servers. The manufacturer QNAP with its Linux-based QTS operating system, has been using EXT4 for many years, but has recently launched a new operating system called QuTS Hero that allows the ZFS file system to be used for mass storage, thanks to this decision, we will be able to We benefit from a large number of improvements in the integrity of files and their protection against possible writing errors.
Before we begin to explain the main features of ZFS, let’s talk about its “limits”. ZFS has been designed in such a way that we never have limitations in real life. ZFS allows to create 2 48 snapshots natively, and also allows to create up to 2 48 number of files in the file system. Other limits are 16 exabytes for the maximum size of a file system, and even 16 exabytes for the maximum size of a file. The maximum storage capacity of a «pool» is 3 × 10 23 petabytes, so we will have more than enough space if we need it, in addition, we can have up to 2 64 disks in a zpool, and 2 64 zpools in a system .
Virtual storage spaces
In ZFS there are what are called “virtual storage spaces”, or also known as vdevs, which are basically the storage device, that is, the hard drives or SSDs for storage. With ZFS we do not have the typical RAID that we find in file systems like EXT4, the typical RAID 0, RAID 1 or RAID 5 among others, they also exist here, but in a different way.
A «pool» can be of various types, depending on what we want in terms of speed, storage space and data integrity in case one or more disks fail:
- Stripe : all the disks are placed in a «pool» and the capacities of the different disks are added together. In the event of a disk failure, we will lose all information. This type of pool is like RAID 0 but it allows to incorporate multiple disks in it.
- Mirror : all the disks get into a «pool» and are replicated, the maximum capacity of the pool will be the same as the smallest capacity of one of the disks. All the disks in the mirror are replicated, therefore, we will only lose information if all the disks in the mirror are broken. This type of pool is like a RAID 1, but it allows to incorporate multiple disks in it.
- RAID Z1 : all the disks get into the pool. Assuming that all the disks have the same capacity, the capacity of all but one of the disks is added (if we have 3 4TB disks, the effective storage space would be 8TB). It allows one of the disks to be broken, and the information is intact. Operation is like a RAID 5 that we all know. A RAID Z1 must have 3, 5 or 9 disks in each vdev, therefore, we can have in a vdev a total of 9 disks and that, if one fails, we do not have data loss, in case of a second disk failure, we will lose all the information.
- RAID Z2 : all the disks get into the pool. Assuming that all the disks have the same capacity, add the capacity of all the disks except that of two disks (if we have 4 4TB disks, the effective storage space would be 8TB). It allows two of the disks to be broken, and the information remains intact. The operation is similar to a RAID 6 that we all know. A Z2 RAID must have 4, 6 or 10 disks in each vdev, therefore, we can have a total of 10 disks in one vdev and that, if two fail, we will not have data loss, in the event of a third disk failure, we will lose all the information.
- RAID Z3 : all the disks get into the pool. Assuming that all the disks have the same capacity, the capacity of all the disks except the one of three is added (if we have 5 4TB disks, the effective storage space would be 8TB). It allows three of the disks to be broken, and the information remains intact. A Z3 RAID must have 5, 7 or 11 disks in each vdev, therefore, we can have in a vdev a total of 1 disks and that, if three fail, we do not have data loss, in case of a fourth disk failure, we will lose all the information.
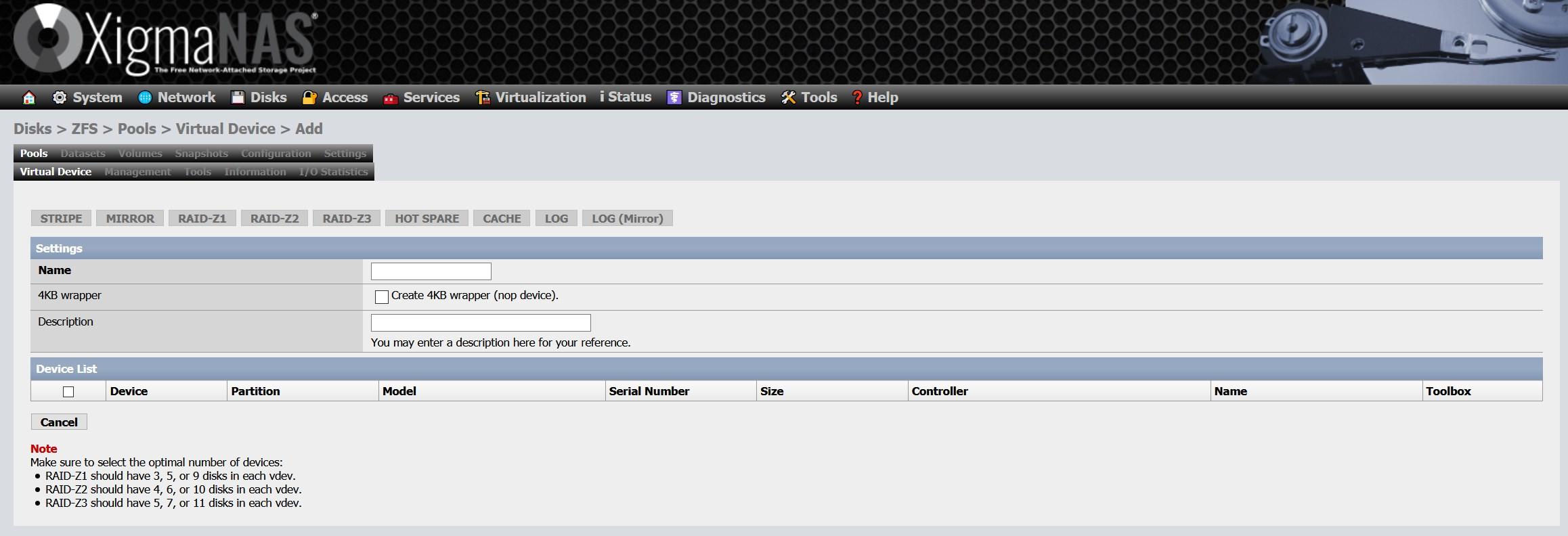
Other configurations that we can perform with ZFS, is to define a disk as « Hot Spare «, or also known as «Spare», so that, in the event of a disk failure, this backup disk automatically comes into operation and begins the process of resilvering (regeneration of data using this new disk that we have just added to the pool). We also have the possibility of defining a disk as « cache «, which is basically to activate the L2ARC and have a higher performance, this is ideal if we use it with a fast SSD, in such a way that we increase the overall performance of the system, if you are going to Using a normal HDD, you won’t notice any improvement and might even worsen performance. Finally, we also have the possibility to define a disk as ” LOG ” (SLOG ZFS Intent Log) to store the write logs that should have occurred, this is helpful in case of a power outage.
Light file systems (dataset)
Datasets are really the ZFS file systems, it is what is inside a ZFS storage space. In order to create a dataset, it is an essential requirement to have previously created a «pool», otherwise it cannot be created. There are two different types of dataset:
- Filesystem : it is the type of dataset by default, it is the one used to store files, folders, etc. The mount point can be set directly, without editing the typical fstab of Linux systems.
- ZVOL : it is a dataset that represents a device by blocks, we can also find it in the different operating systems as «Volume». This dataset allows you to create a device in blocks, and later format it with file systems such as EXT4.
Some of the most important features of a dataset (filesystem) are that it allows you to configure quotas, reserved disk quota, permission management with advanced access control lists (ACL), and even allows very advanced features such as the following:
- Deduplication (dedup) : Deduplication is a technique of eliminating duplicate copies of repeated data. It could not be called “compressing”, but it is true that, if we perform deduplication, the final size of a data set is clearly smaller. This technique is used to optimize data storage on disk. ZFS does the deduplication natively, therefore it is very efficient, but for it to work properly it needs a lot of RAM: for every 1TB of deduplicated dataset, it takes about 16GB of RAM . Considering that storage space (hard drives) is much cheaper today than RAM, it is advisable not to use deduplication, unless you know what you are doing.
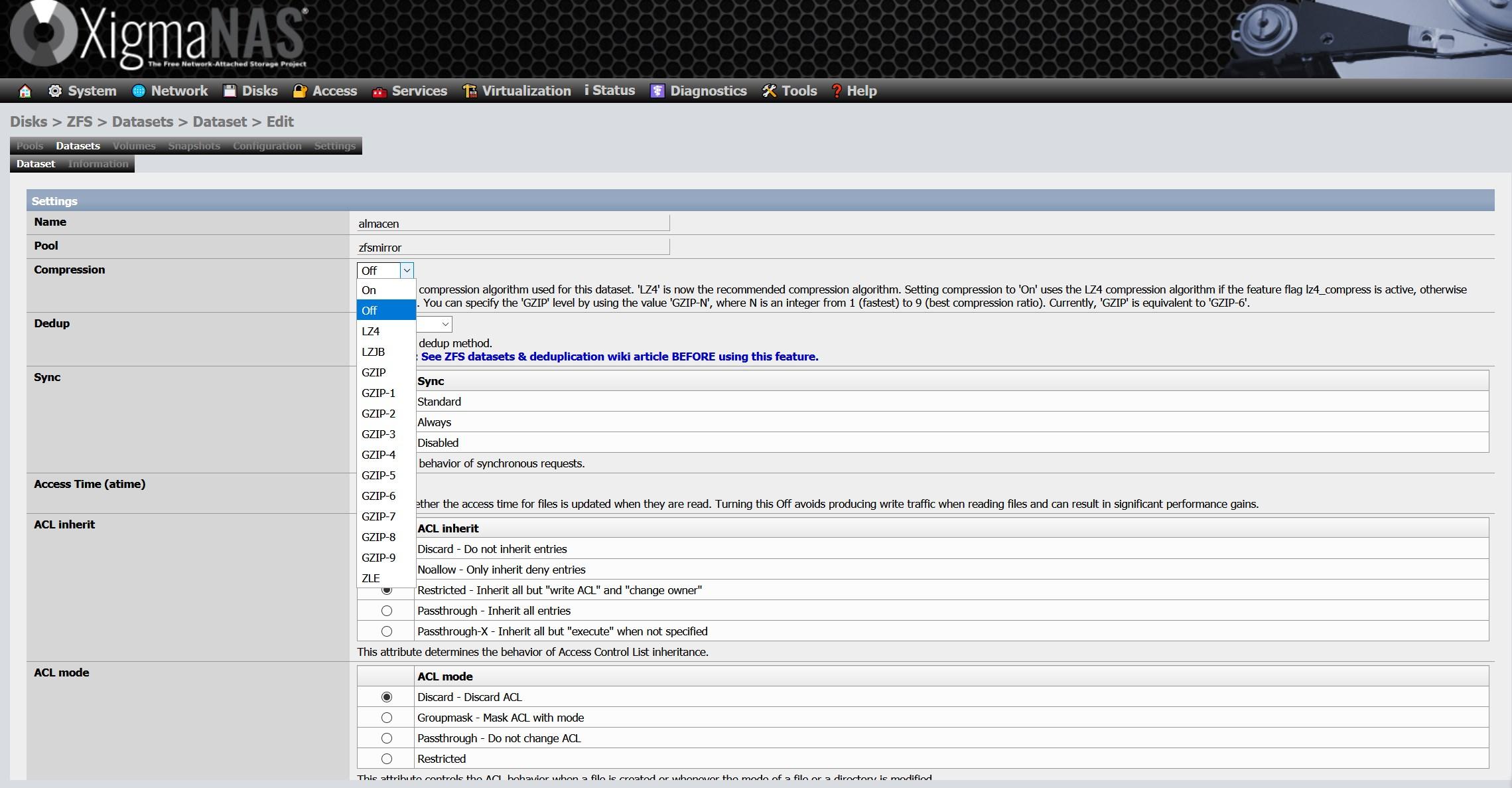
- Compression : ZFS natively allows different compression algorithms to be used, with the aim of saving storage space in the dataset, and therefore in the pool. The LZ4 compression algorithm is currently the standard and the most recommended in most situations, others such as LBJB, and even GZIP with different compression levels can also be used. However, very soon we will see ZSTD which is a new compression algorithm for ZFS. ZSTD is a modern, high-performance general compression algorithm, created by the same person as LZ4, its goal is to provide compression levels similar to GZIP, but with better performance. Another interesting feature of ZSTD is that it allows you to select different compression / performance levels to suit the needs of administrators.
- Snapshots : Snapshots allow us to save a “photo” of the state of the file system at a certain moment, with the aim of protecting the information if we suffer the attack of a ransomware, or that we directly delete a file when we shouldn’t have. done. Although manufacturers like QNAP or Synology have snapshots and use EXT4, ZFS snapshots are native, making their operation much more efficient. ZFS allows us to view the data in these snapshots without reversing them, reversing all changes, and even “cloning” these snapshots that we have taken. This “clones” allow you to have two independent file systems that are created by sharing a common set of blocks. The number of snapshots we can take with ZFS is 2 48 , that is, it could be said that we have unlimited snapshots.
ZFS does not overwrite data due to the Copy-on-write model that we will talk about later, therefore taking a snapshot simply means not releasing the blocks used by old versions. Snapshots are taken very quickly and are really efficient from the point of view of space, they don’t take up anything unless you modify a data from which the snapshot has been made. That is, there is no duplication of data, the snapshot data and those in production are shared, only when modifying it is when the occupation begins to increase.
Self-healing
One of the most important features of ZFS is self-repair, we have previously discussed that there are «mirror» type pools and also RAID-Z, with single, double or triple parity. A very important aspect is that ZFS does not have the “write-hole” defect, this can occur when a power failure occurs during writing, this makes it impossible to determine which data blocks or parity blocks have been written on the discs and which ones are not. In this catastrophic error situation, the parity data does not match the rest of the data in the storage space, in addition, it is not possible to know which data is incorrect: the parity data, or the block data.
All data in ZFS has been hashed prior to writing to the pool, the hashing algorithm could be configured when creating the dataset. Once the data has been written, the hash is checked to verify that it has been written correctly and there have been no problems writing. ZFS makes it easy to check the integrity of the data using this hashed data. If the data does not correspond to the hash, what is done is to look in the mirror or calculate the data through the parity system (RAID-Z) to proceed with its verification at the hash level. If the hash data is the same, we proceed with the correction of the data in the block. All of this is done fully automatically.
Copy-on-write
ZFS uses a copy-on-write architecture, thanks to this, we avoid the problems derived from the write-hole that we have previously explained. CoW is one of the main features of ZFS. The operation consists in that all the pointers to blocks of a filesystem contain a checksum, which is verified when reading the block. Blocks containing active data are never overwritten, what is done is to reserve a new block, and the modified data is written to it directly. To make it faster and more efficient, several updates are usually added to later carry out the transactions, and even a ZIL (ZFS Intent Log) is used.
The downside of this is that it produces high fragmentation in pools, and there is currently no possibility of defragmentation. If your pool is made up of SSDs, you will not notice too much the loss of performance due to the very nature of SSDs, but if you use HDD you may notice it. In our case, we have a fragmentation of more than 25% after several years of use:
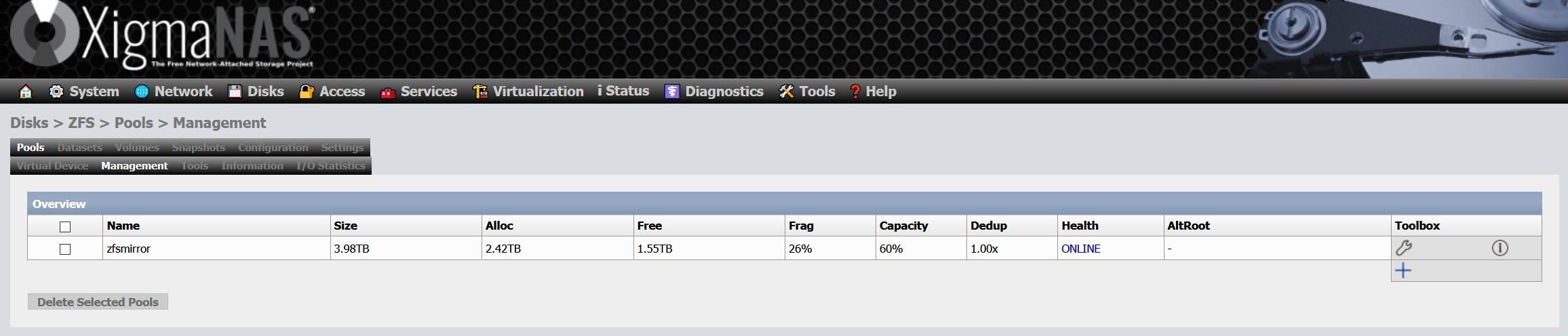
The only way to defragment the pool is by copying the data to another medium, removing the pool and creating it again. That is, there is no way to defragment a pool in ZFS, at least for now.
Dynamic Striping
ZFS distributes the data we write dynamically to all virtual devices (vdev), in order to maximize performance. The decision of where to place the data is made at the time of writing. This greatly improves mirror and RAID-Z pools, and also effectively eliminates the write-hole problem we’ve seen previously. Another interesting feature is that ZFS uses blocks of variable size up to 128K, the administrator can configure the maximum block size used, ideal to adapt to the needs of what is going to write to the pool, but it can adapt automatically. In the case of using compression, these variable block sizes are used to make it much more space efficient.
How to install and launch ZFS
ZFS is installed on FreeBSD-based operating systems, such as XigmaNAS or FreeNAS. The default file system in these operating systems is UFS, but we have the option of using ZFS as the system file system. However, the most recommended is to use ZFS as the file system of the storage set where we are going to have each and every one of our files, this is where we can truly get the most out of it. In these NAS-oriented operating systems, we will not have to execute any command because everything is done with the graphical user interface, without having to touch anything else. Other operating systems like Debian, Ubuntu, Linux Mint and others, we will need to install ZFS manually.
Next, we are going to teach you how to configure and start up ZFS on a XigmaNAS operating system (based on FreeBSD), the procedure is similar to FreeNAS since we are using the same file system. We will also teach you how to install it on operating systems such as Debian, although here we will have to do everything through the command console.
ZFS configuration and startup in XigmaNAS
For the realization of this tutorial we have used VMware to virtualize XigmaNAS, and we have created a total of 6 virtual disks. The first 20GB virtual disk capacity is to install the operating system itself, and it is in UFS format that is native to FreeBSD. The other 5 disks with 100GB each, are oriented to the storage space for the ZFS file system, and will be formatted as ZFS.
Step 1: Format the disks in ZFS format to add them to a pool
The first step is to format the disks in ZFS format to add them to a pool. To do this, we go to « Disks / Administration «.
Within this menu, we go to the “HDD Options” tab and click on “Import Disks – Import”, to import all the disks we have configured on the server.
We will see all the disks without format, because we just added them, but we will also see the disk of the operating system in UFS format.
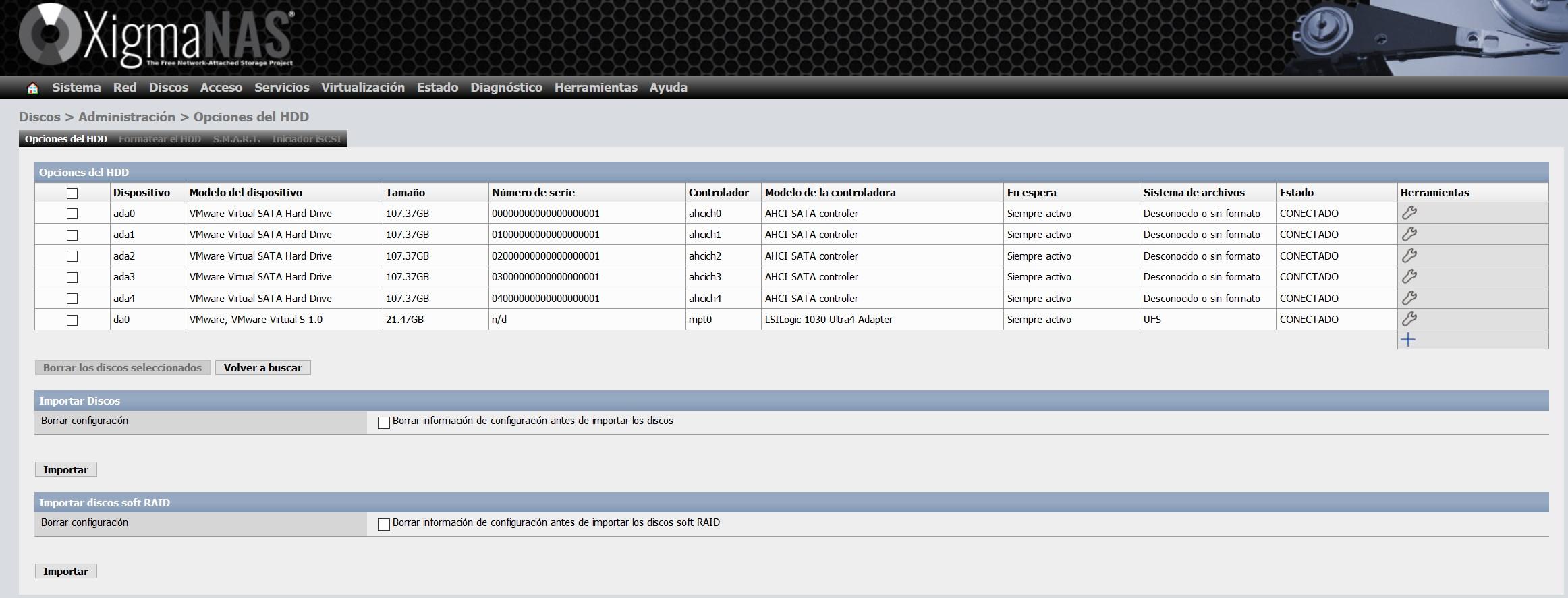
In the ” Format HDD ” tab we select all the disks, and we select ” File system: ZFS storage in the device pool (Pool) “.
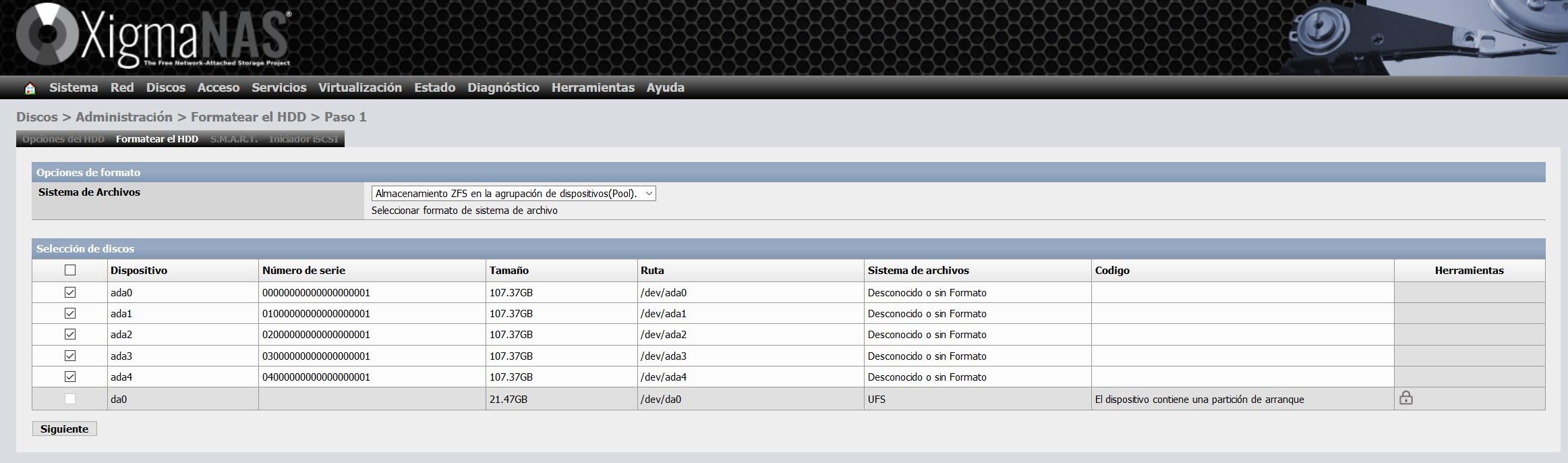
In the configuration wizard to format it, we can give you a volume label, as you can see below:
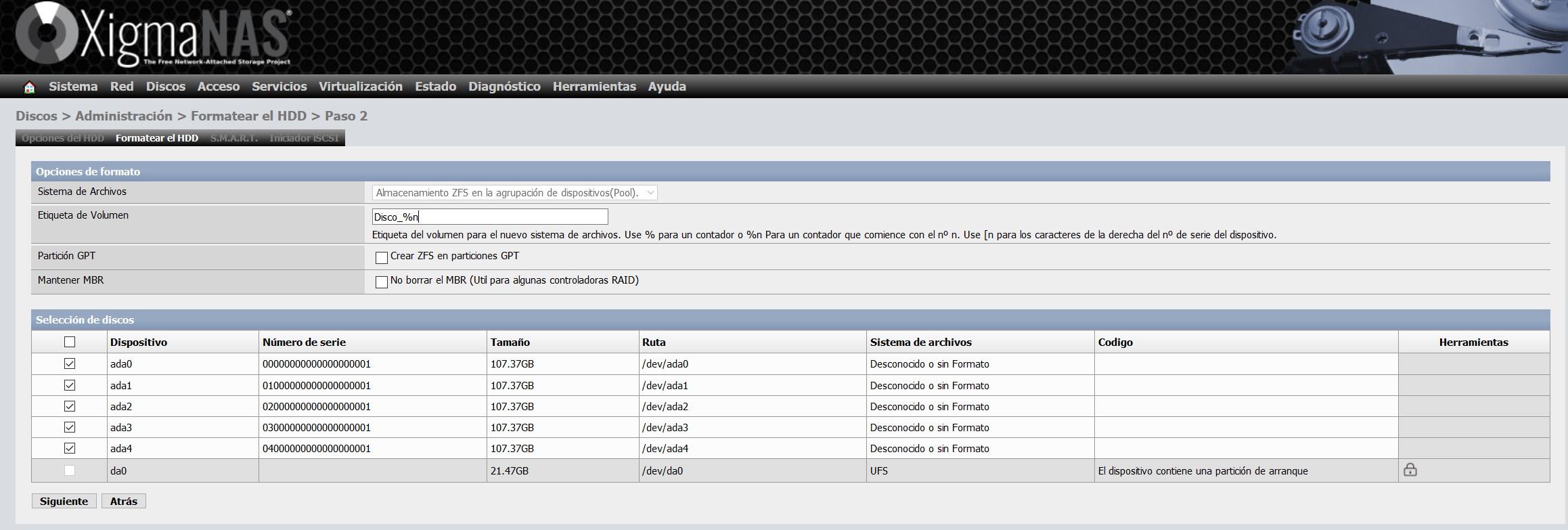
Click on next and we will have formatted all the disks in ZFS format, ready to add them to a ZFS pool.
Step 2: Create the vdev ZFS virtual appliance
Now we have to go to «Disks / ZFS» and we will access the «Device groups (pools)» section in the «Virtual device» part. In this section we click on the “+” we have on the right side.

Here what we will have to do is select all the disks that we want to incorporate the vdev, depending on the number of disks that we add, we will have the possibility of configuring a «Stripe», «Mirror» and the different RAIDZ. We have chosen the five discs, therefore, we can create the five types.
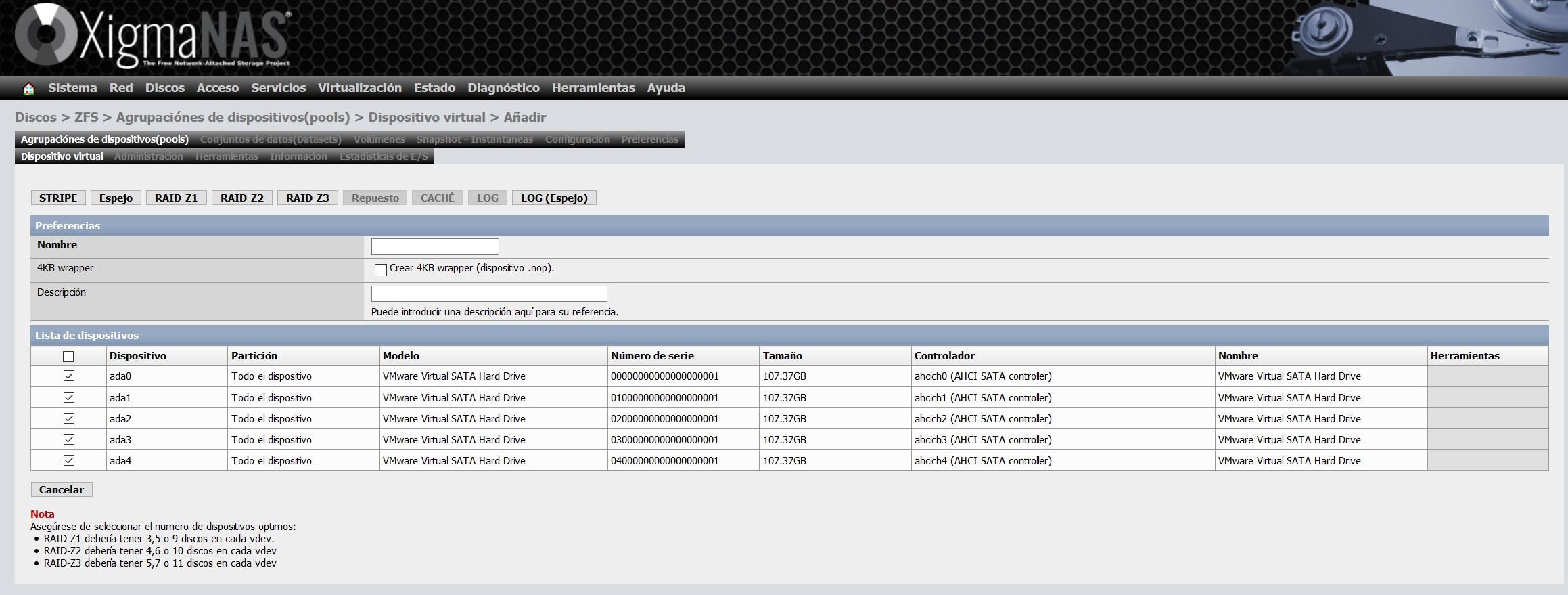
We have chosen the option of “Mirror”, or also known as “Mirror”. With this option we will have on the five discs exactly the same information.
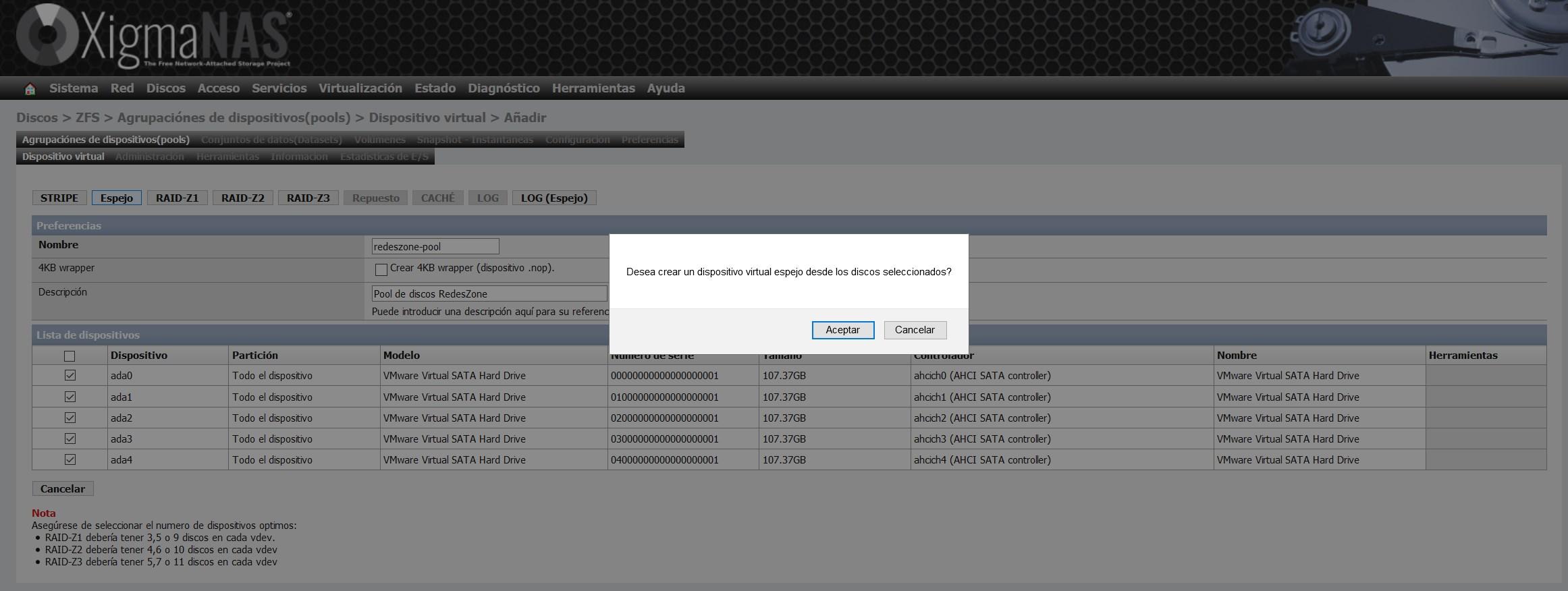
Once we have created the virtual device, it will appear in the list of virtual devices, as you can see here:
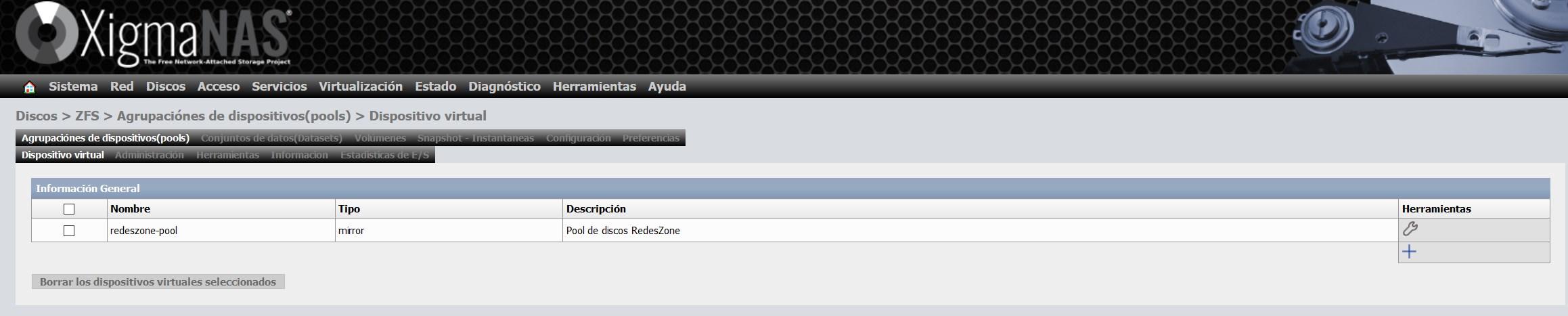
Step 3: Set up the pool and give it a name
Once we have created the vdev, we must go to «Administration», and click on «+» to format this vdev and be able to use it later with a Dataset or Volume.

We have to give it a name, and we can also define the mount point that we want, the default mount point is / mnt.
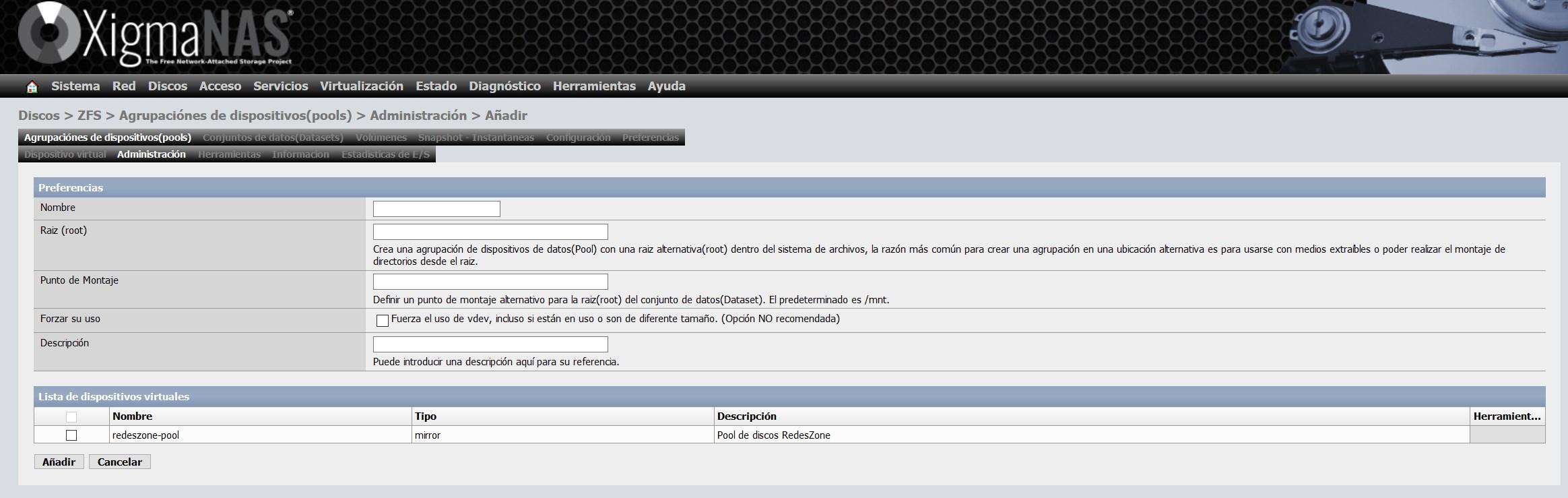
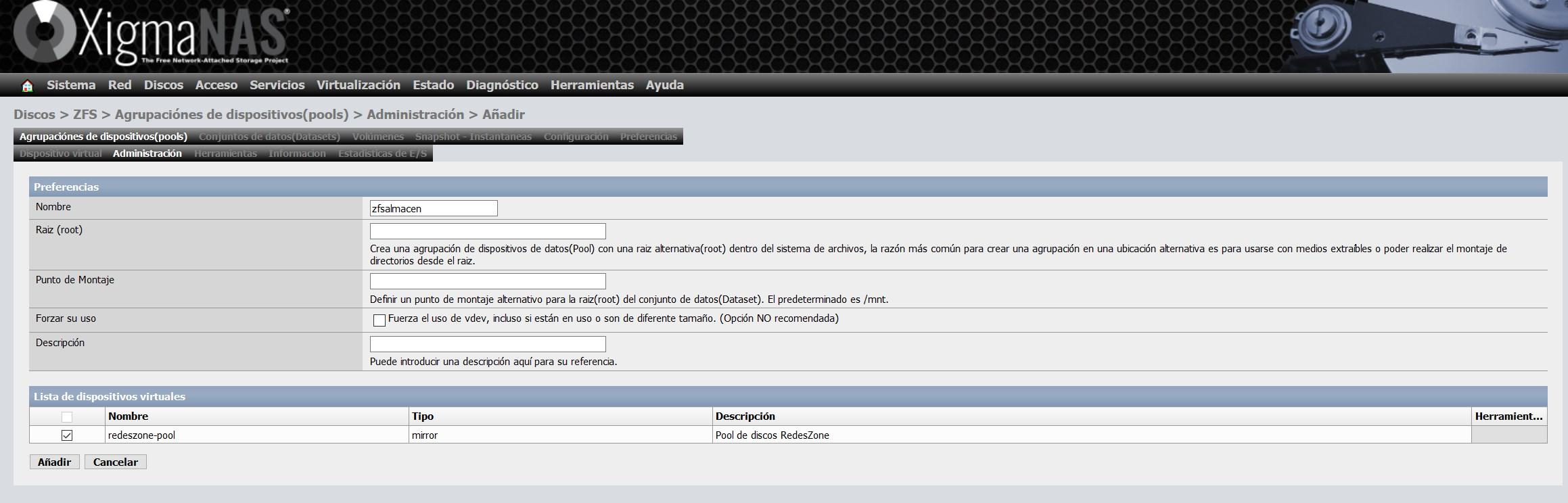
We are going to give it the name of zfsalmacen and we choose the vdev that we have created previously, as you can see here:
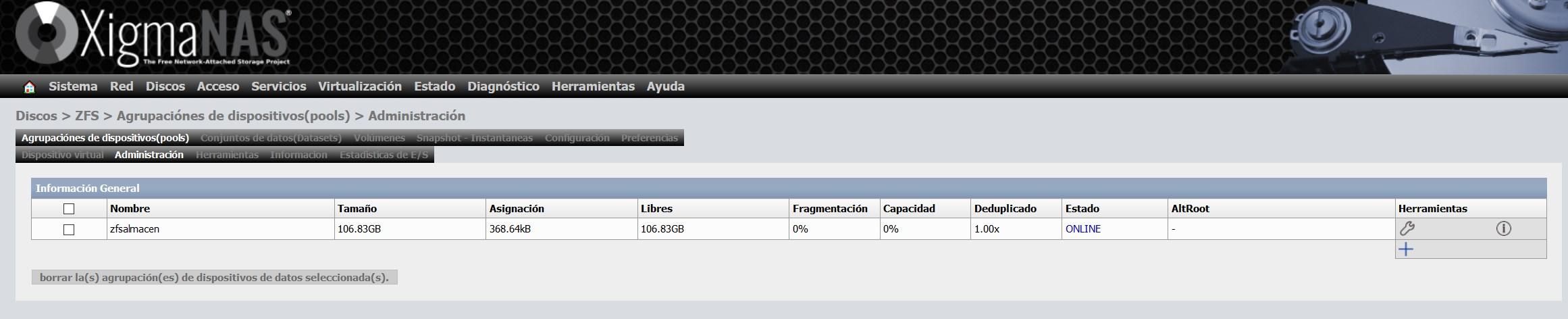
Once we have created it, the total size, free size, fragmentation etc. will appear.
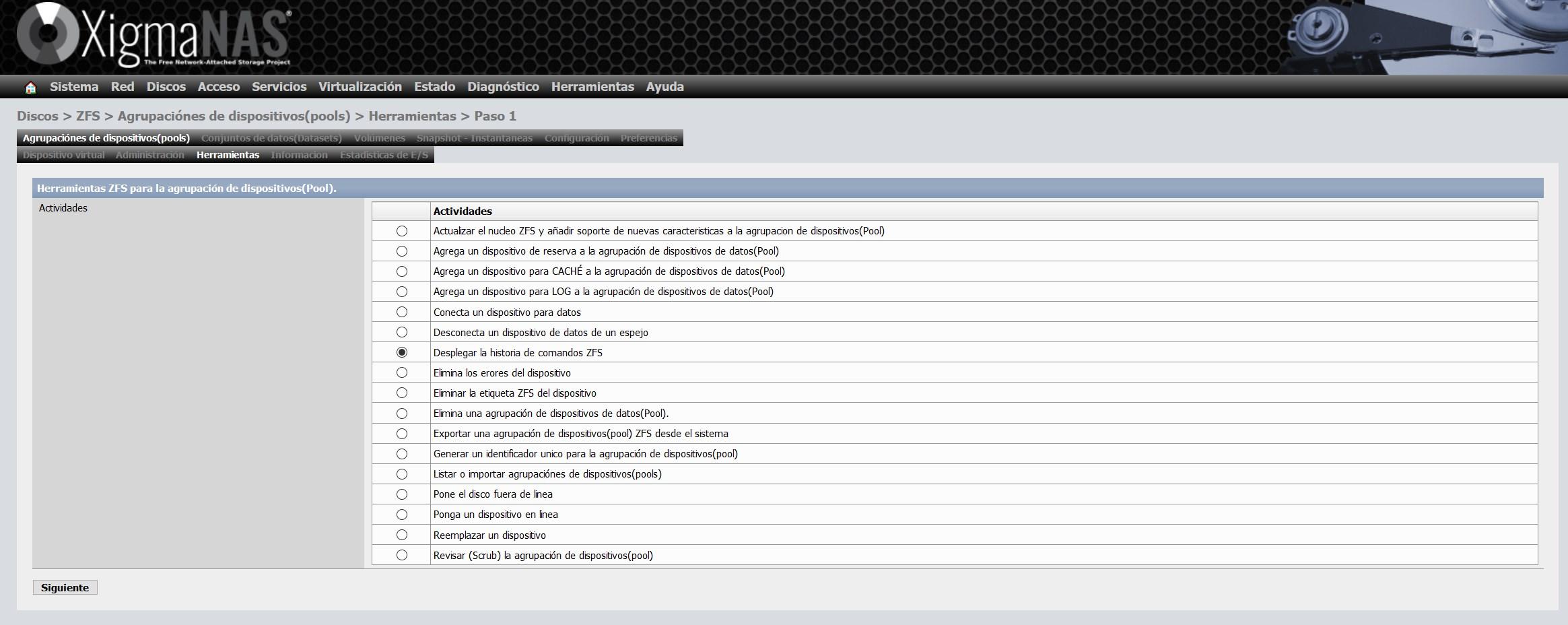
A very important section of XigmaNAS is the “Tools” section, here we will have different configuration wizards to carry out different actions, all this we can do manually using commands, but with this graphical user interface we can do it in a couple of clicks. What allows us to perform XigmaNAS is all of the following:
- Update the ZFS kernel and add support for new features to the device pool (Pool)
- Add a backup device to the data device pool (Pool)
- Add a device for CACHÉ to the pool of data devices
- Add a device for LOG to the data device pool (Pool)
- Connect a device for data
- Disconnect a data device from a mirror
- Deploy ZFS command history
- Eliminate device errors
- Remove ZFS tag from device
- Deletes a pool of data devices (Pool).
- Export a ZFS pool of devices from the system
- Generate a unique identifier for the device pool
- List or import device groupings (pools)
- Puts the disc offline
- Put a device online
- Replace a device
- Scrub the device pool
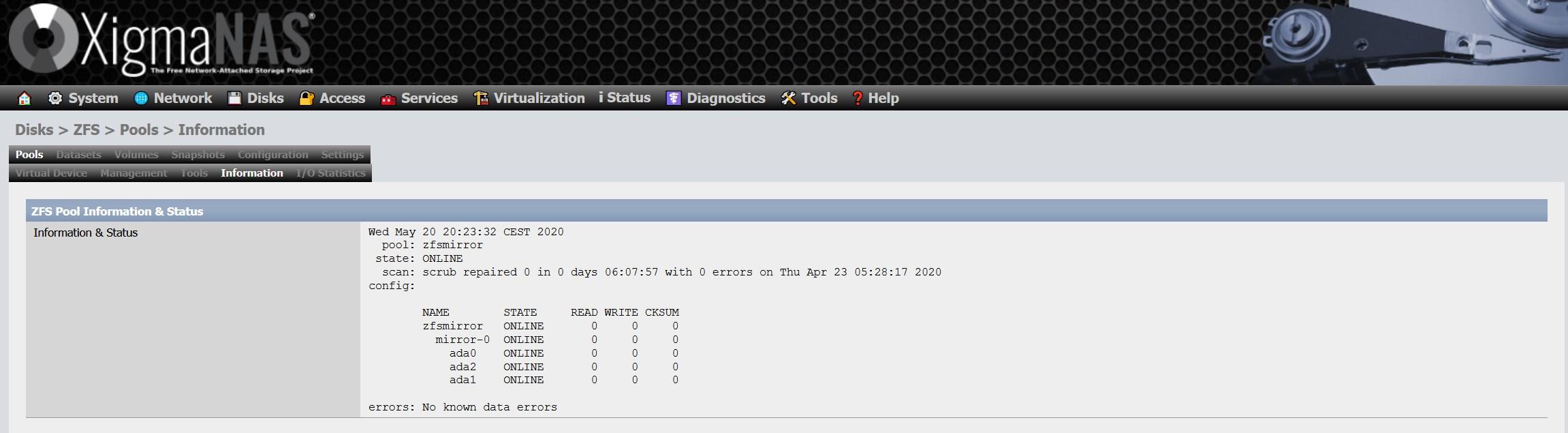
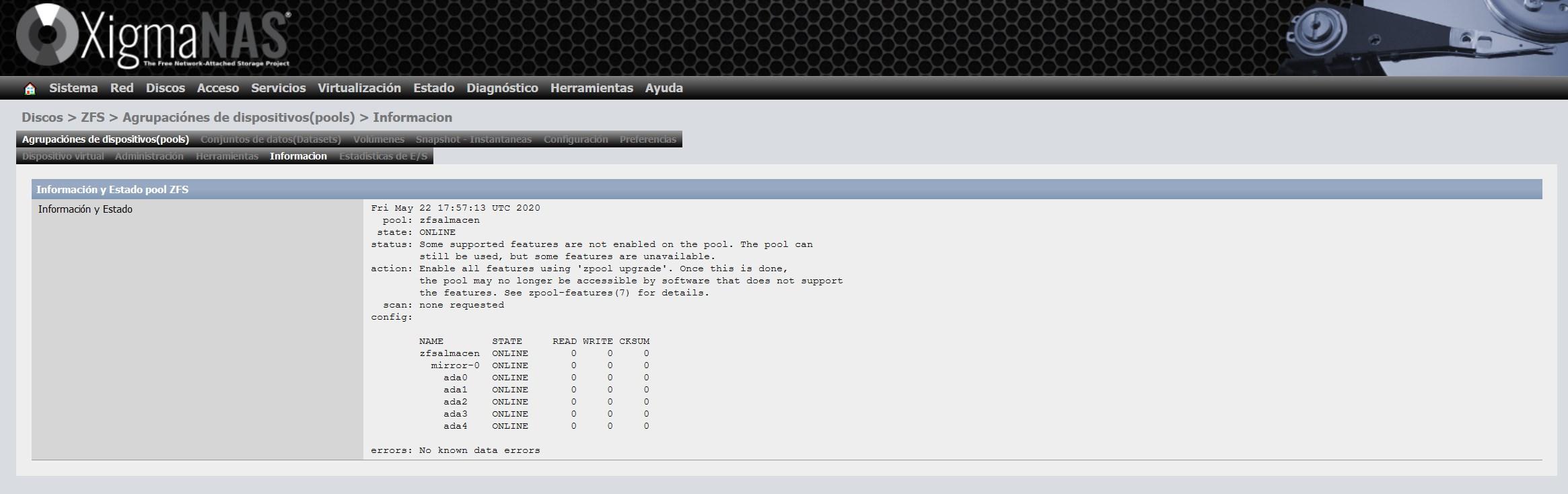
In the “Information” section we can see the general status of the ZFS, the type of vdev chosen and also all the disks we have in the pool. An important detail is that it is possible that we do not have the ZFS updated to the latest version on the disks themselves, if we get that warning, we will have to carry out an update that is very simple.
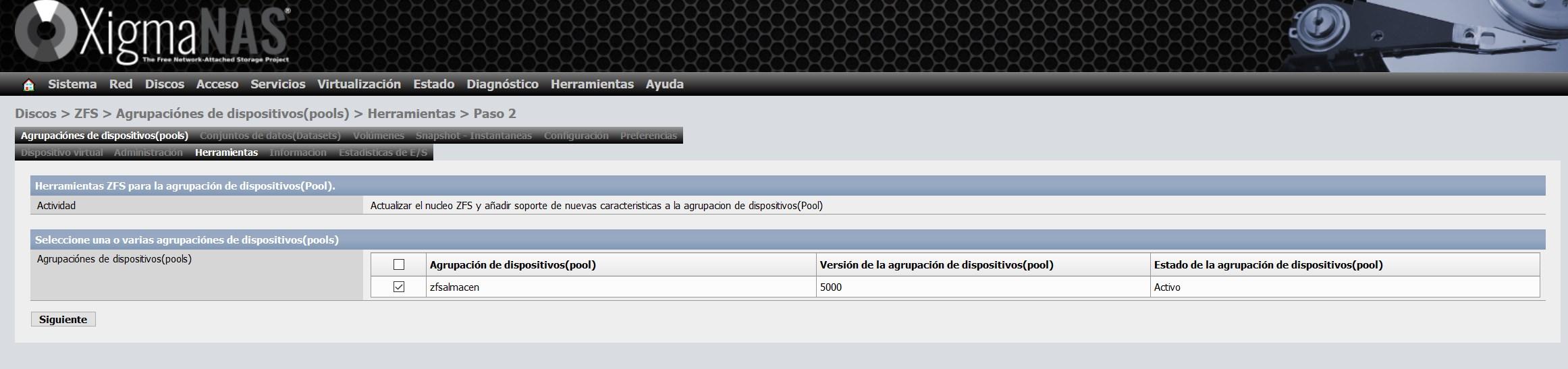
To update it, we go to the “tools” section and select the option “Update the ZFS kernel and add support for new features to the device pool (Pool)” and continue with the wizard to update it
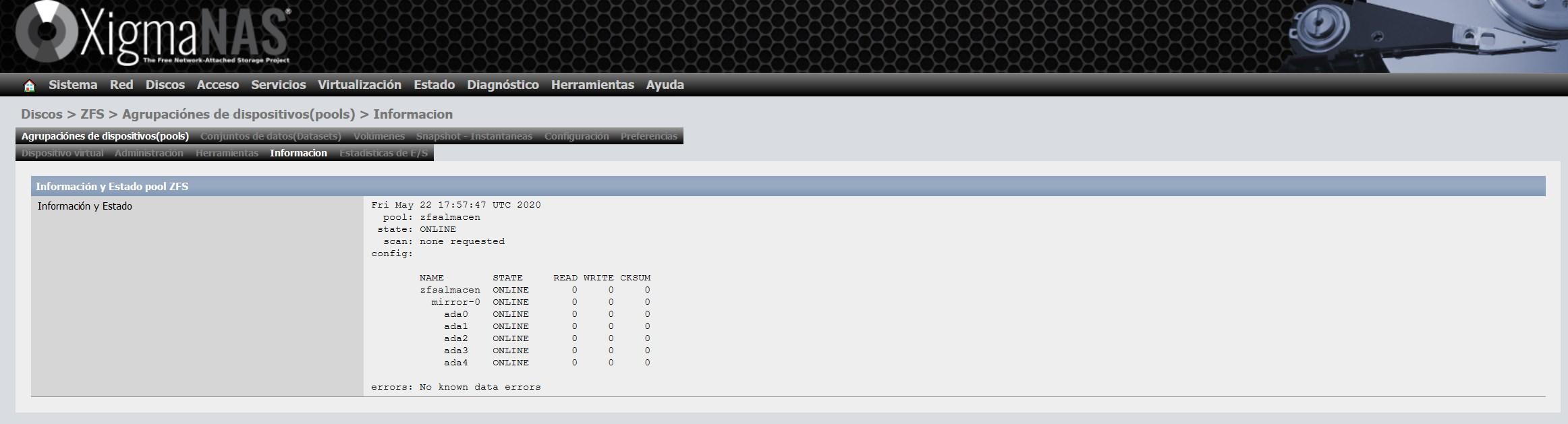
As soon as we have updated it, we will not get any notice, as you can see here:
Step 4: Create the dataset or volume
Creating a dataset is really simple, we go to «Dataset (dataset)» and click on the «+» key:

Within the dataset configuration, we have to choose a name, and also the pool where we want to create the dataset. We only have one pool created, so there is no loss. This is where we can configure real-time compression, deduplication, synchronization, ACLs, and many more advanced parameters.
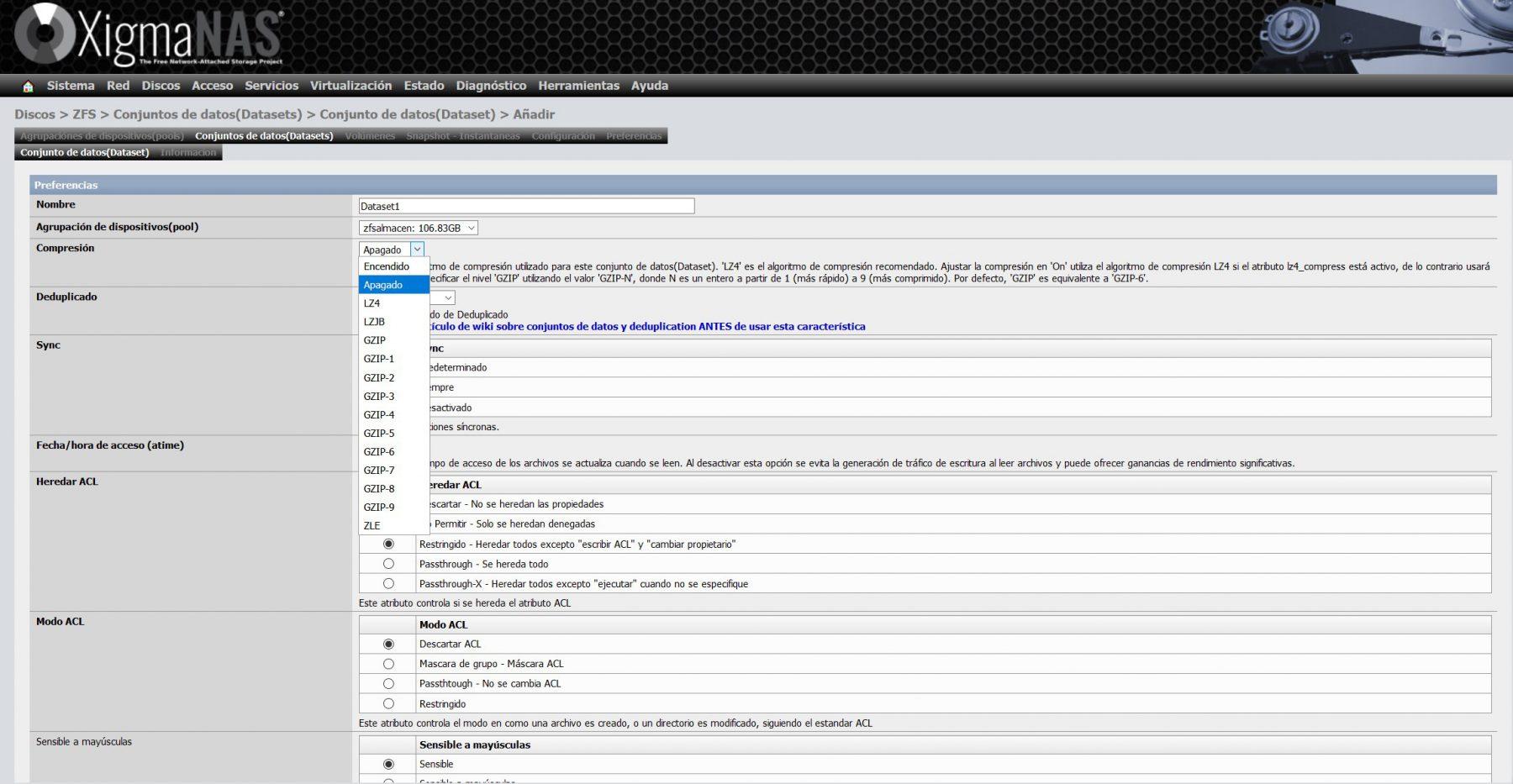
We must remember that, if we select the deduplication option, it will consume a large amount of RAM, XigmaNAS itself warns us of this on its wiki.
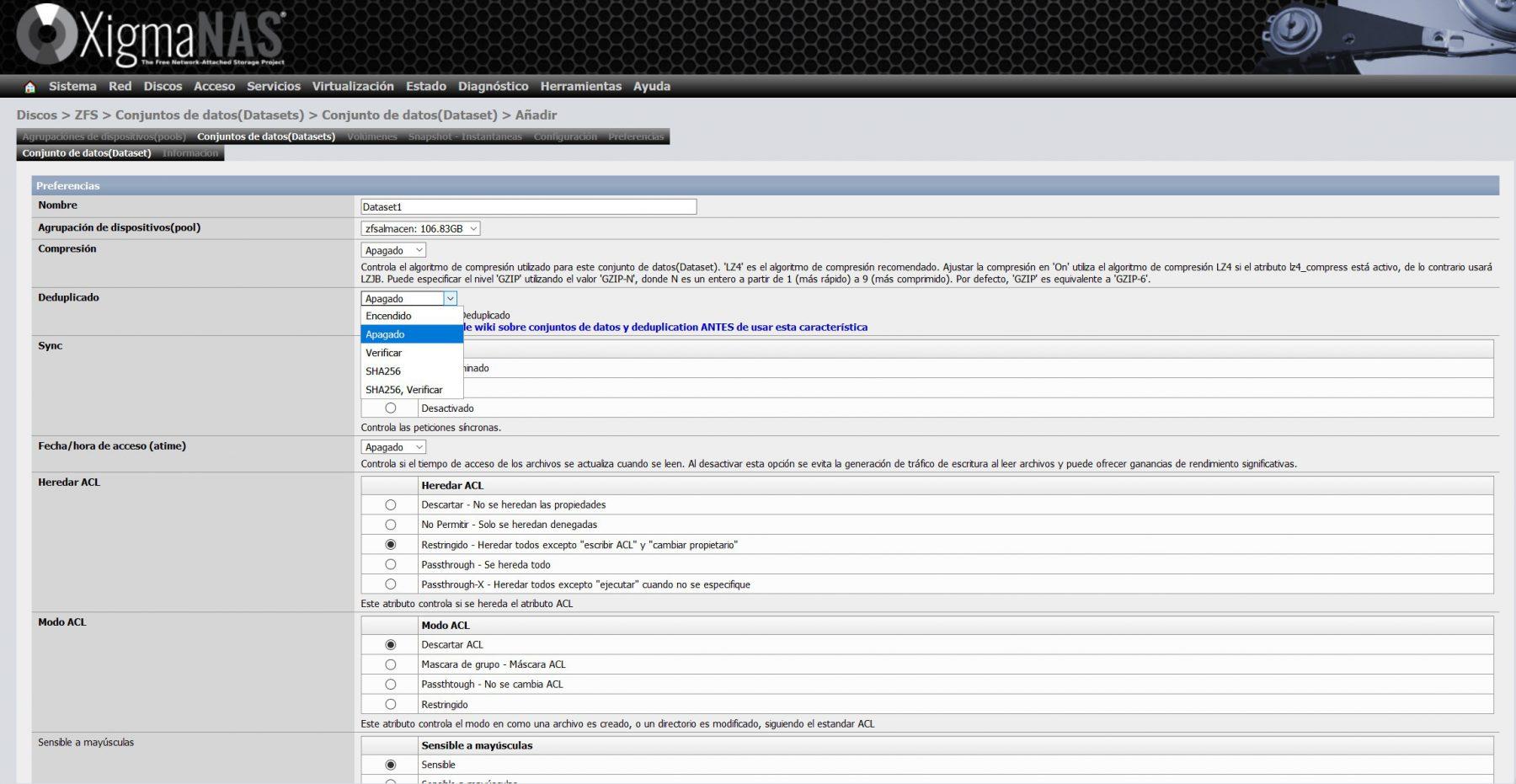
The rest of the available configuration options are the following:
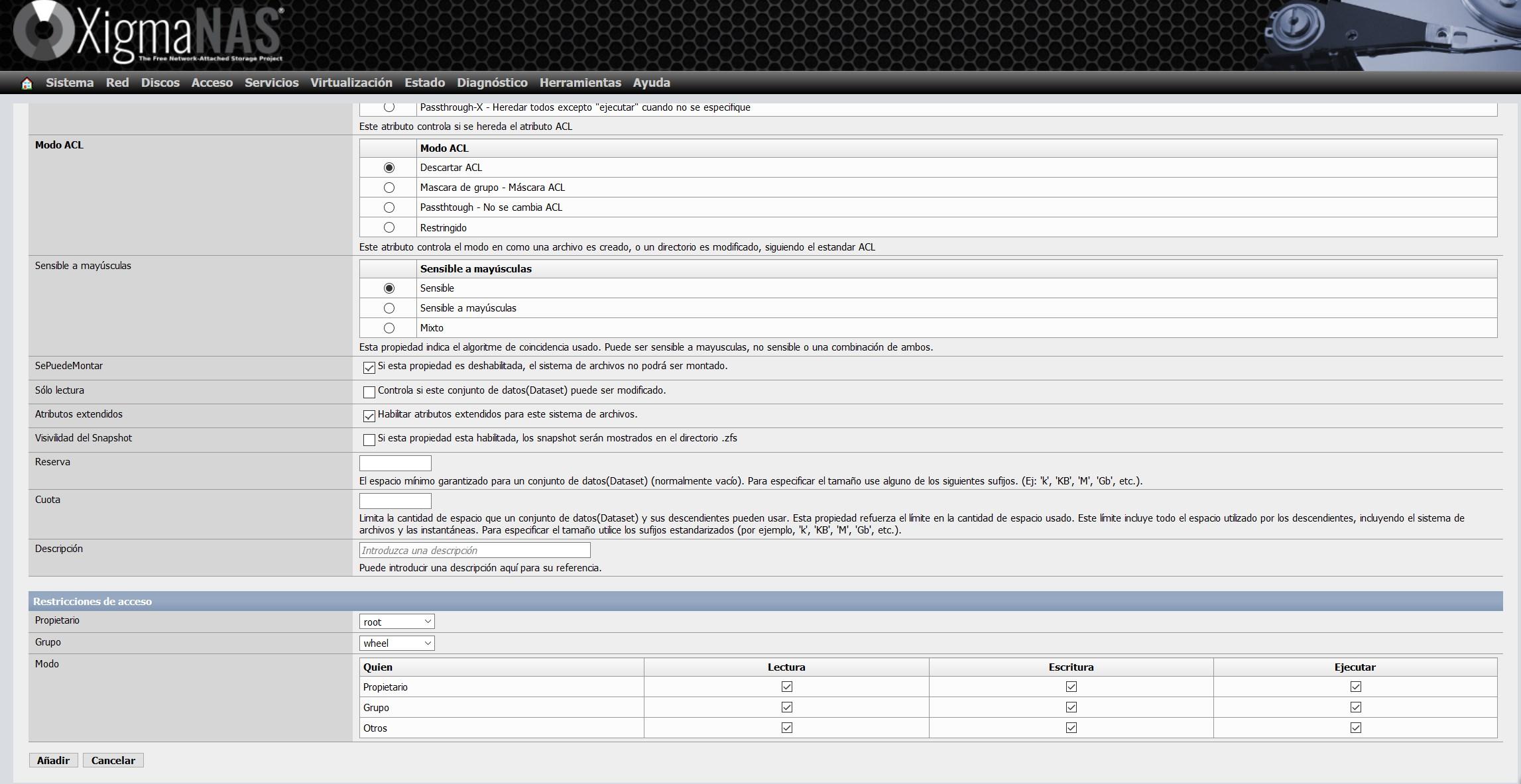
Once the dataset has been created, it will appear this way in the «zfsalmacen» pool that we have created previously.

We must not forget that we can also create block devices, the so-called volumes in ZFS:

Other ZFS options
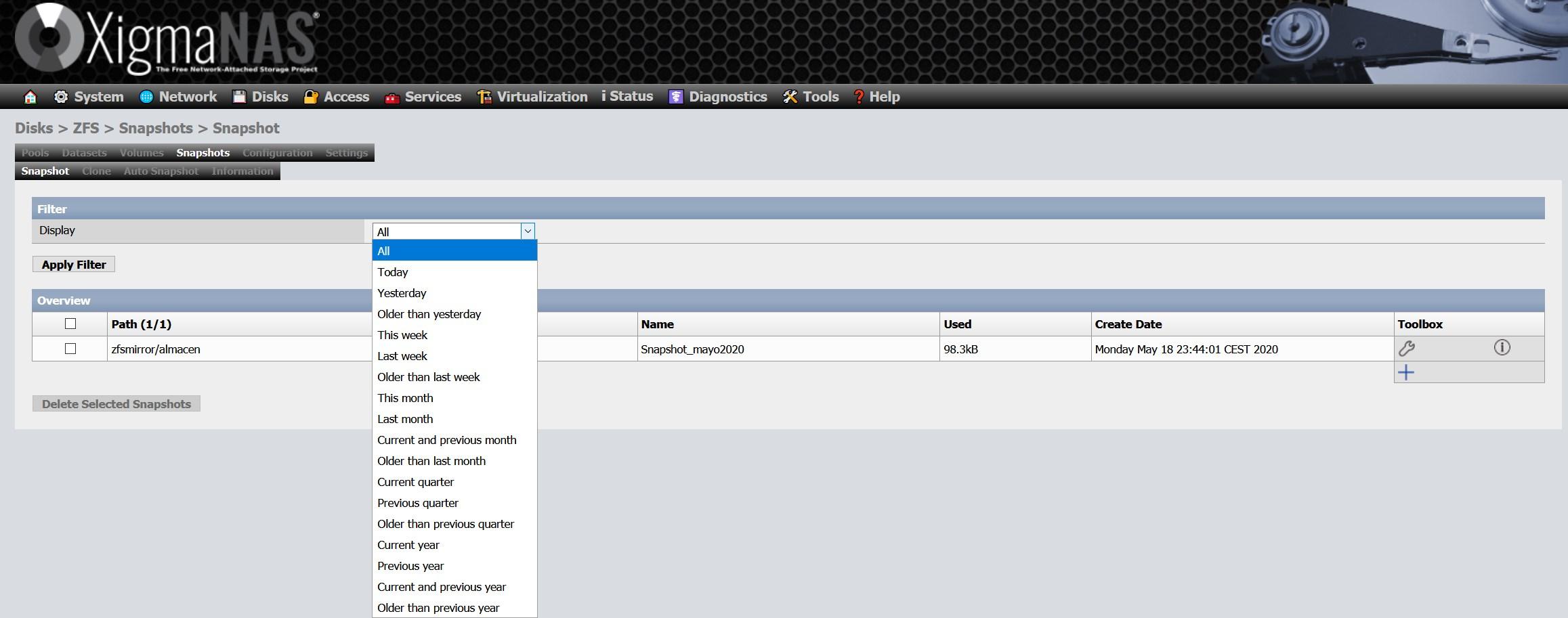
Other available options are snapshots or snapshots, we can create millions of snapshots, either scheduled or manually. To configure a snapshot, simply click on the “+” to add a new one:
We select what we want to make a snapshot of, we can do it to the entire pool, or only to one or more datasets that we have within the pool:
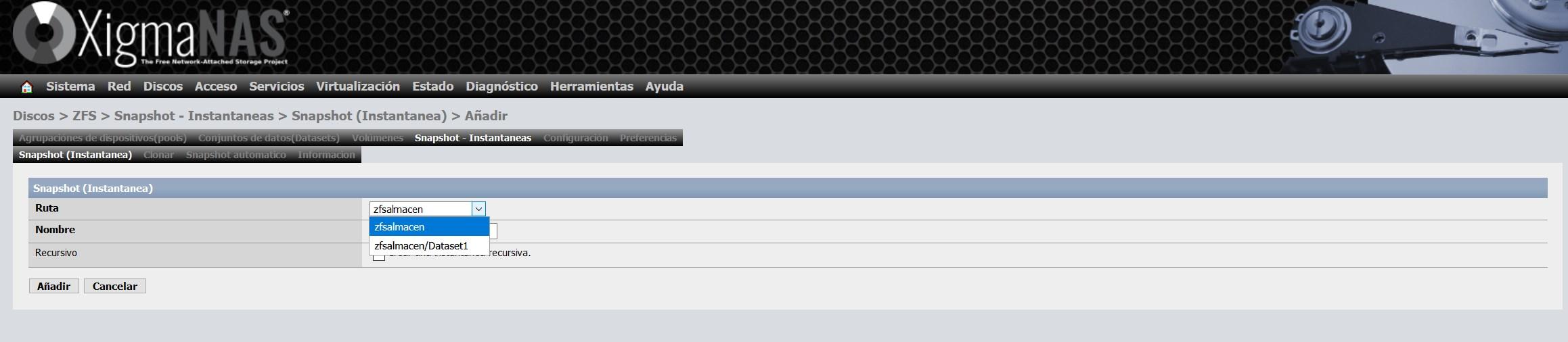
Once the snapshot is created, we will see something like this:
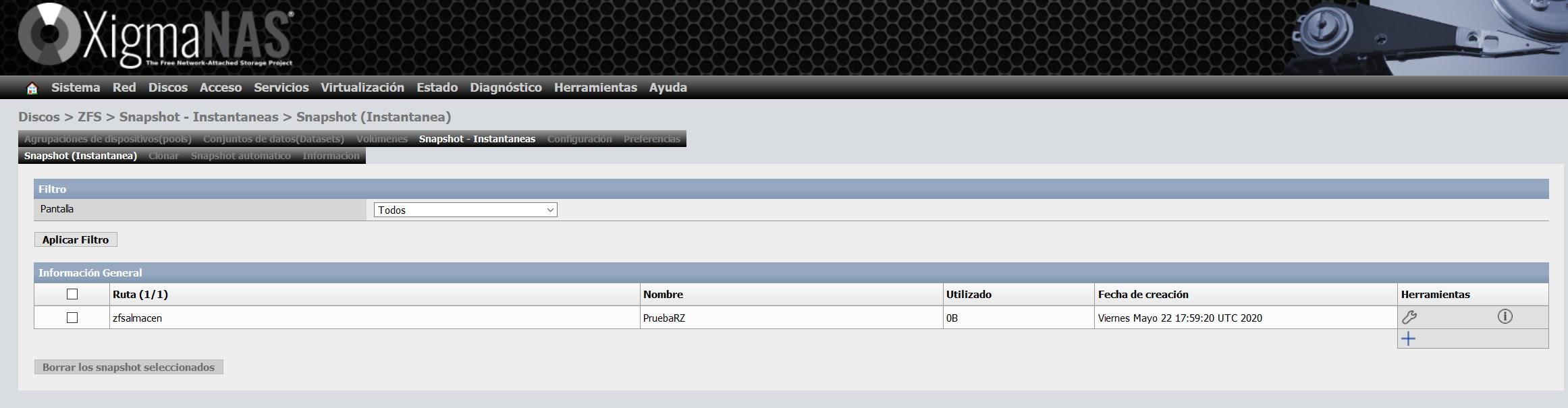
The most important thing is the column of “used”, since it is the space that this snapshot occupies, and it is because modifications have been made or data has been deleted. Because snapshots are native to ZFS, the efficiency is really impressive.
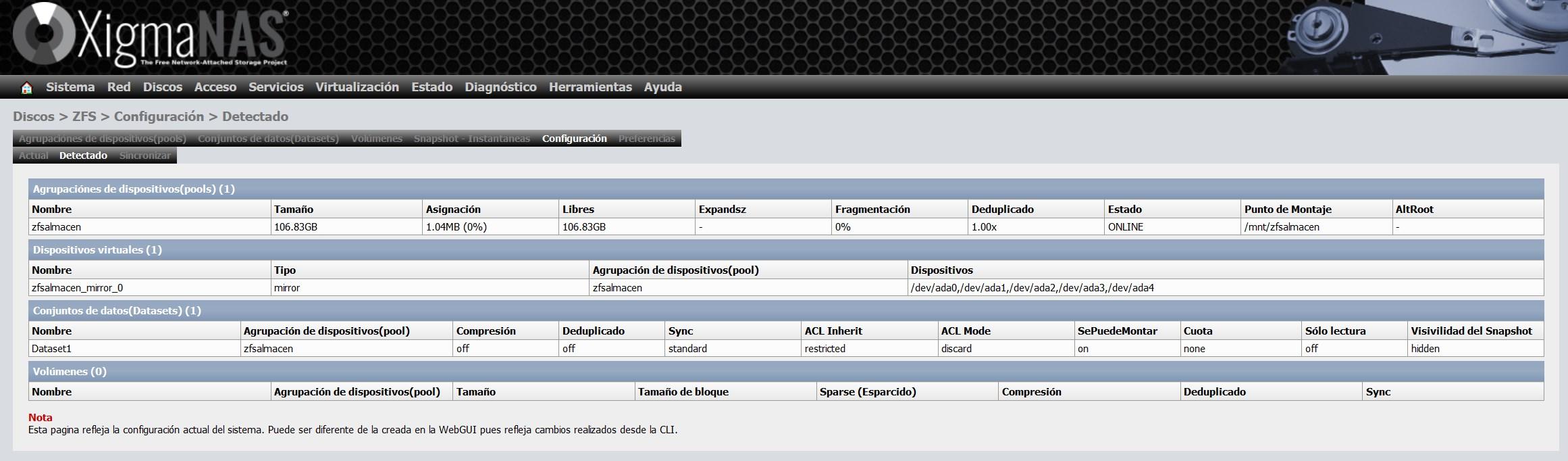
In the “Configuration” section we will have a summary of everything we have configured so far, we will be able to see the virtual devices, the pools, and also the datasets and volumes created.
In the main menu of the operating system, we can see that we have the pool «zfsalmacen», and it will indicate the total, occupied and available space.
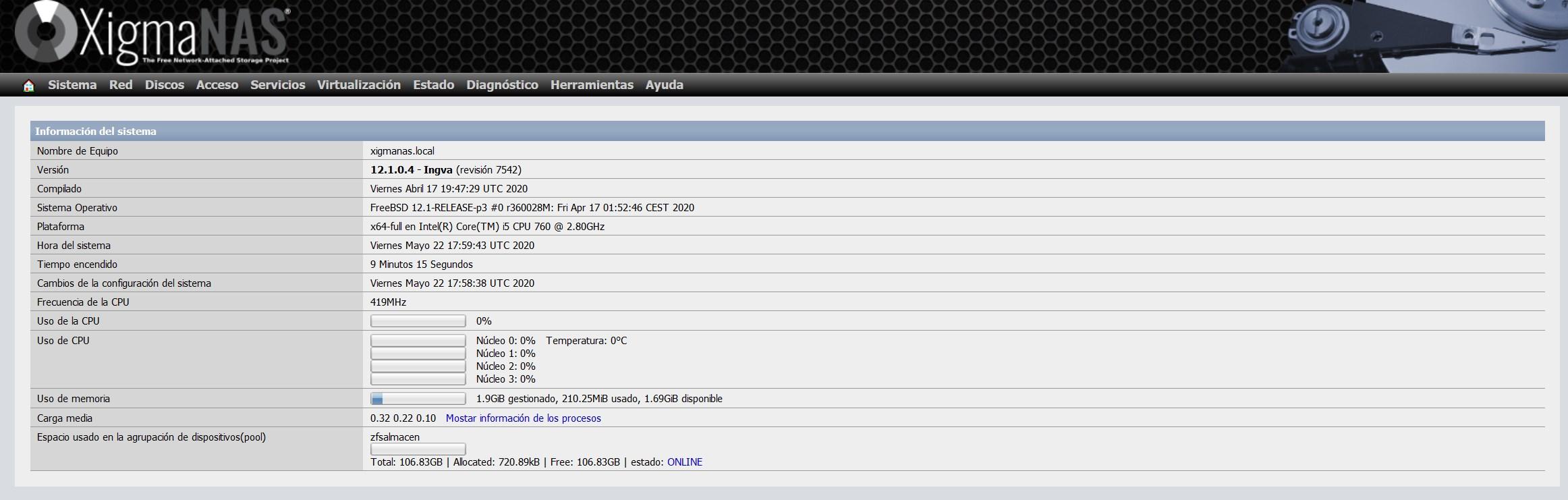
As you have seen, ZFS is a very advanced file system and allows us great configurability. In the event of a disk failure, it is enough to put it offline, add a new one, add it to the pool and perform a scrub to review the entire pool and regenerate the data.
Setting up and starting up ZFS on Debian and others
Although ZFS is an advanced file system, due to some problems with the license of use, many Linux distributions do not support it by default , so the startup can be somewhat tedious on many systems having to install and configure the system files manually.
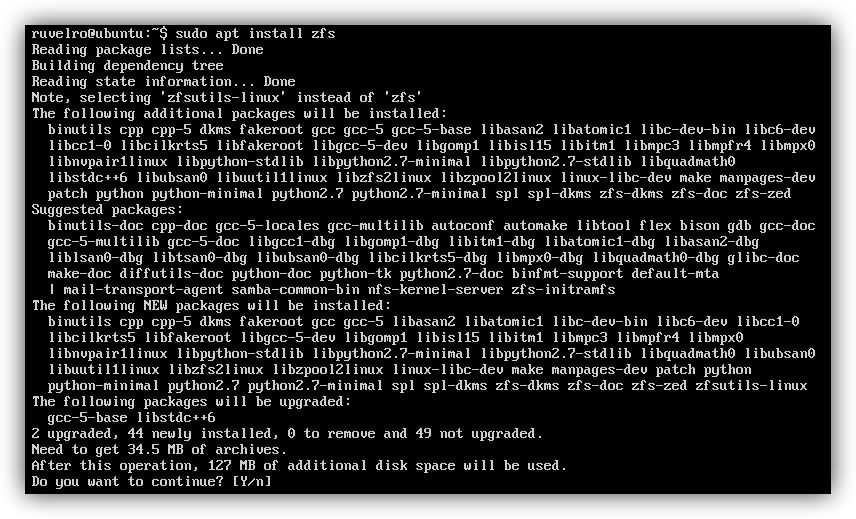
If we want to use this file system in our operating system, we can download it completely free of charge from its main website . In addition, the main repositories also have pre-compiled packages, so, for example, if we want to install it in Ubuntu, we only have to download it from the official repositories with apt, which, along with the rest of the necessary packages, will be installed completely automatically.
sudo apt install zfs
When managing disks, this file system uses the concept of « pool «. A ZFS pool can consist of one or more physical hard drives. For example, if we have 3 hard disks and we want to take advantage of their capacity as a single ( stripe ) with this file system, we will have to configure a pool that includes the 3 disks with the following command:
sudo zpool create pool-redeszone /dev/sdb /dev/sdc /dev/sdd
If we only have one disk, we will simply put on a disk and we will have a single disk stripe.
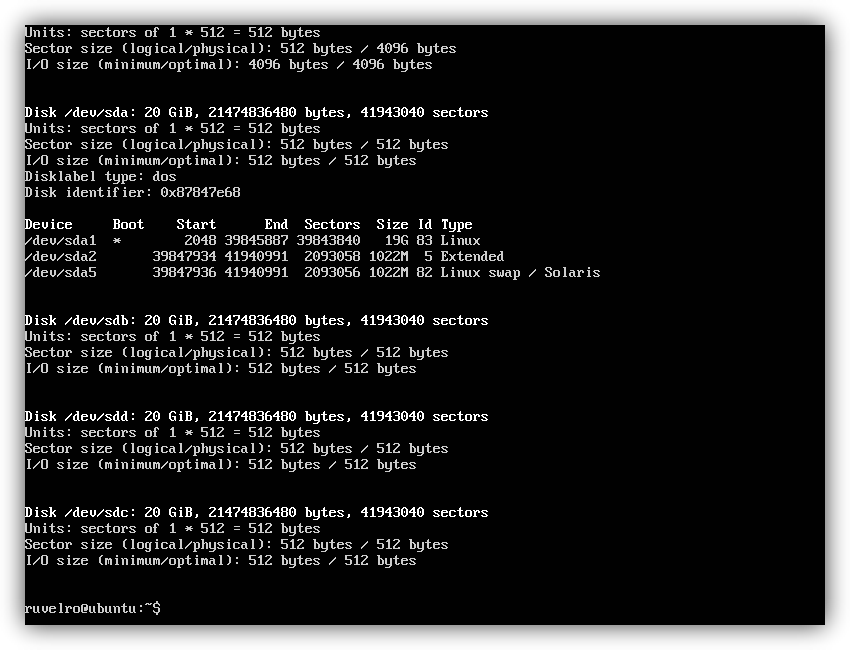
We can change ” pool-redeszone ” by the name we want to give the pool. We must also change the “sdb”, “sdc” and “sdd” that we have in our system, by the corresponding letter of each disk that we want to add. We can see all the connected disks with the command:
sudo fdisk -l
 In case you want to configure a mirror with the same disks, we must add the «mirror» parameter, remaining as follows:
In case you want to configure a mirror with the same disks, we must add the «mirror» parameter, remaining as follows:
sudo zpool create pool-redeszone mirror /dev/sdb /dev/sdc /dev/sdd
If we want to configure a RAIDZ, it would be like this (minimum 3 disks are needed):
sudo zpool create pool-redeszone raidz /dev/sdb /dev/sdc /dev/sdd
If we want to configure a RAIDZ2, it would be like this (minimum 4 disks are needed):
sudo zpool create pool-redeszone raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
If we want to configure a RAIDZ3, it would be like this (minimum 5 disks are needed):
sudo zpool create pool-redeszone raidz3 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
By default, Linux will mount the disk pool at the root of the / operating system, so if we want to access it and its data, we must go to the / pool-redeszone / directory.
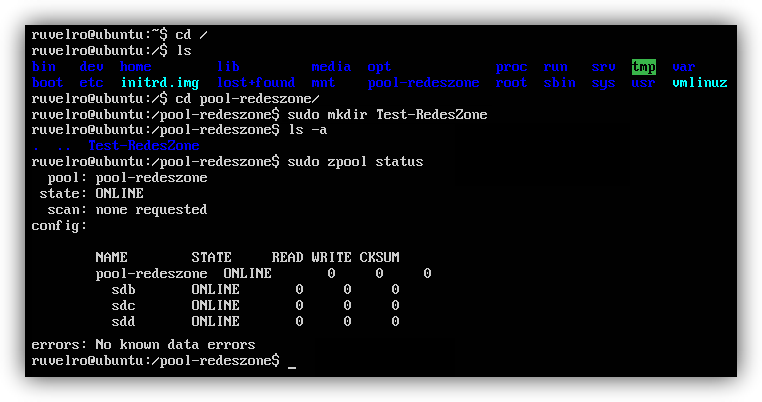
If we want to know the status of our disk pool , we can do it by typing in the terminal:
sudo zpool status
 In case you want to add disks to the pool, you do it with the command:
In case you want to add disks to the pool, you do it with the command:
sudo zpool add pool-redeszone /dev/sdx
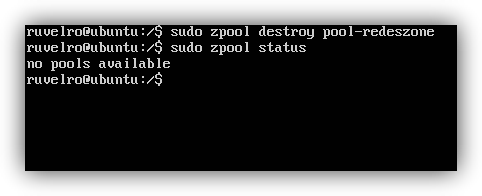
And even destroy the pool (with the corresponding loss of all data) with the command:
sudo zpool destroy pool-redeszone
Other interesting options are ZFS snapshots, we can create a snapshot like this:
zfs snapshot pool-redeszone/datos@2020-05-22
And we could also delete the created snapshot in the following way:
zfs destroy pool-redeszone/datos@2020-05-22
As we can see, it is an advanced file system for advanced users, but once you learn the basic commands and how it works, its administration and maintenance is very easy. In case you want to add a disk for cache or for LOG as we have explained before, it could also be done, adding “cache” and “log” followed by the disks to choose. We recommend that you access the official website of OpenZFS where you will find a large series of resources to install and use this advanced file system.