It is the result of controversy, cannon fodder for users little related to the pure enjoyment of the technology that both companies provide and yet it is a fact that has been maintained since the Radeon X800. NVIDIA took command of graphics cards in late 2005 and has reigned with an iron fist for 15 years since then, but what is stopping AMD from launching a GPU that outperforms its rival?
There are several key factors that NVIDIA has always been clear about when launching new GPUs to the market and that AMD has begun to understand for just over two years.

These factors are not really relevant beyond the architectures themselves, but they have interesting connotations that leave a clear message that promises to change the current graphics card landscape.
Architecture
We start from the basis that we understand the nature of a GPU as such, that is, they are fantastic “giant calculators” of FP operations, therefore they are great for parallel operations. The vast majority of calculations are made by FPU units and unlike CPUs, these units as such are not programmable by software designers, but rather are all a bit more abstract and totally dependent on the driver that supports them.
This leaves AMD and NVIDIA to optimize their products as few devices on a PC have. At the same time, this is just the beginning of the problem with the main argument of this article, and that is that NVIDIA allocates such a huge amount of resources that its development group is referred to internally as the “NVIDIA Army”.

The number of software developers they have is far superior to AMD and here is part of the superiority of their GPUs. It must be understood that in the architectures and from precisely the end of 2005, the graphics cards have the same units to work: ALUs / FPU TMUs and ROPs (apart from the corresponding caches and clear VRAM) and only Turing has imposed the new RT Cores and Tensor Cores for different tasks.
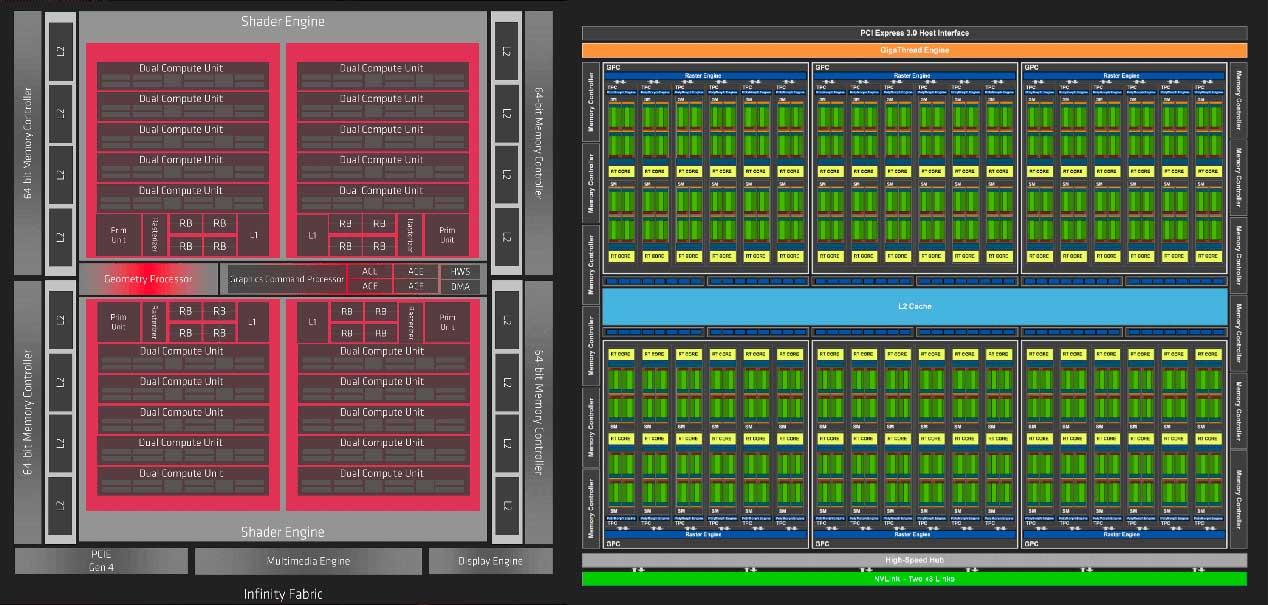
This again assumes that software optimization coupled with architectural improvements make a bigger difference to each generation if you don’t advance faster than the rival. To be specific, Navi as architecture includes two Shader Engines blocks that AMD in turn divides into the famous Asynchronous Compute Engines (ACE) , where each one has 5 WGP and two CUs.
For pure comparison, NVIDIA in Turing has 6 GPCs with 6 TPCs in each and two SMs for each block. This simple vision of the structure of each architecture makes us see that the parallelization of those of Huang is much higher and more configurable than that of AMD, which has much more powerful blocks altogether, but which at the same time imply being less energy efficient than your rival’s option.
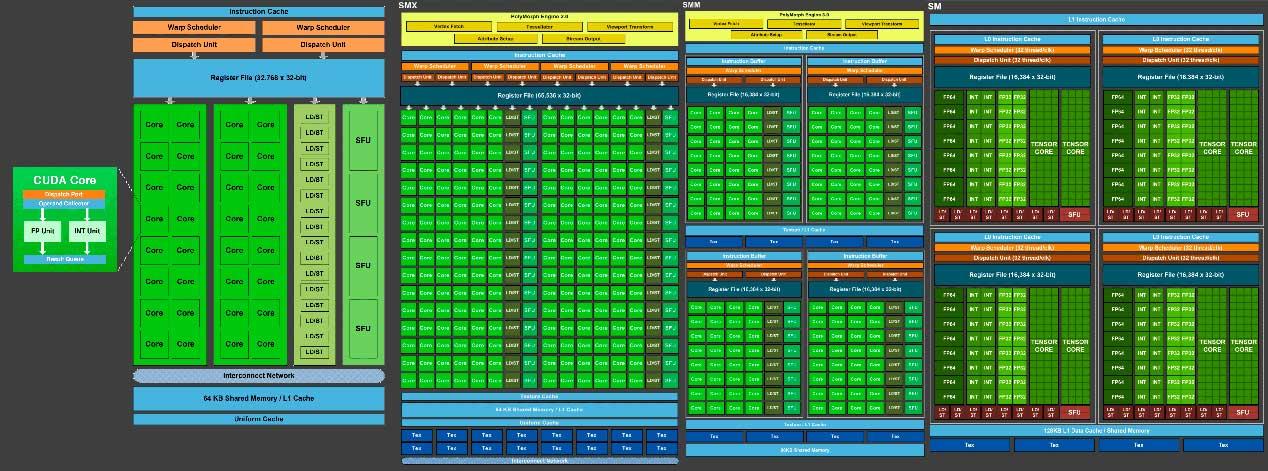
Finally, it must be understood that there is a radical difference in the approach of the operation of both architectures, which comes from the past by simple evolution of the same: NVIDIA works with scalar execution units, AMD for its part uses units that work with vectors.
What does this imply? A totally different optimization to work by developers and at the same time for its opacity, it is a wall that AMD tries to break down offering units that are simpler to program and with better resources.
Consumption
Another problem that AMD has had for years, and that even with a lithographic process much more advanced than that of its rival, it does not manage to be ahead. Again, everything is an architecture and optimization problem.
NVIDIA is capable of deactivating any group of TPCs and even entire GPCs in milliseconds, varying the workload to a great extent and that together with various technologies such as Tiled or high-level color compression make their units work more efficiently and therefore they manage to boost performance by consuming less energy.
Optimization is key and here NVIDIA by the operation of its units manages to do more than AMD in the same clock cycle. You should not look at this so much from the point of view of performance (which is obviously better) but from consumption.
A scalar unit allows one floating instruction and one integer at the same time and per clock cycle. The reorganization of the architecture in NVIDIA allows a programmer to work with vector operations in a simpler way than in AMD, especially now that Turing has three different well differentiated engines within each SM.
This allows rasterization to be better focused on these motors, be it INT32 , FP32 or Tensor Cores , allowing, if not necessary, to deactivate complete GPCs or any of these motors, saving consumption and being more efficient at work. .
Prices

It is a determining factor when we talk about which GPU is “better”. For NVIDIA, the strategy of high prices offering innovative technologies has worked this time, but the reality is that both Ray Tracing and DLSS have not been as big a step visually as was intended, and they have not been free from controversy or problems.
Offering a lower product at a lower price does not make it better per se, you have to know how to position it in an attractive way. The sections of consumption and architecture lead directly to it and make AMD be seen as the most affordable option by price to a greater number of users.
Navi surprised NVIDIA at this point, as the architectural improvements have been profound and it has been a significant leap that made Huang’s launch a new series of cards to cover gaps. But the reality around the world is that the user values the technologies, performance and consumption that NVIDIA offers at a higher price. It is not for nothing that it owns more than 60% of the world market, so we are in the position of those who may choose to pay something more for an NVIDIA GPU to take advantage of its new technologies and those who simply do not want to go through that ring for different reasons.
In any case, for more than 15 years AMD has normally been in tow in this section. NVIDIA sets prices with its new GPUs and AMD fills in the gaps with its GPUs.