The RTX 3000 came out a few months ago replacing the RTX 2000, but how do both architectures compare and what are the changes from one generation to the other, is it as spectacular a leap as NVIDIA sells or are they rather small changes? We explain the differences between the Turing and Ampere architectures.
Is it worth the exchange of an RTX 2000 for an equivalent in the RTX 3000? From our point of view, if you want maximum performance, yes, but at the same time we believe that it is important to demystify both generations of GPUs, so we are going to compare them.

How are Turing and Ampere the same in architecture?

There are a number of elements where there have been no changes from one generation to the next, so there have been no internal changes and they still work the same in Ampere compared to Turing.
The list of items that have not been modified is opened by the command processors in the middle of both GPUs. Which is the part in charge of reading the command lists from the main RAM and organizing the rest of the GPU elements. Followed by the fixed function units for rendering via rasterization: raster units, tessellation, textures and the ROPS.
The internal memory structure has not changed either, that is, the cache hierarchy which remains the same in Ampere and has not changed with respect to Turing, since it remains the same in both architectures, the only element of the memory hierarchy being the GDDR6X memory interface used by GPUs based on the NVIDIA GA102 chip such as the RTX 3080.
In which elements are Turing and Ampere different

We have to go inside the SM units to see changes in the Ampere-based RTX 3000 compared to the Turing-based RTX 2000 and they are changes that have been made on three different fronts:
- Floating point units in FP32
- The Tensor Cores.
- The RT Cores.
Outside of these elements and outside of the number of SM units, which is higher in the GeForce Ampere than in the GeForce Turing there is no change, so NVIDIA has recycled a good part of the hardware of the previous generation to create the new one. . And before you draw the conclusion that this is something negative, let me tell you how common in hardware design.
Floating Point Changes on GeForce Ampere SMs

On all GeForces up to Pascal, all floating point units were called CUDA kernels by NVIDIA. So without further ado, without clarifying what that meant beyond floating point calculations. They implied that they were 32-bit precision floating point units.
Actually the CUDA kernels were actually logicoarithmetic units for 32-bit floating point computation, but also units of the same type for 32-bit integers. The particularity? They operated switched, in such a way that both types could not work at the same time.

With Turing things changed and what is called concurrent execution appeared, the reason is that the GPU thread lists combined threads by integers and floating point and did not reach the maximum slot occupation of the SIMT unit with each sub -ola, so NVIDIA decided on Turing to apply concurrent execution. In which a wave of 32 threads of execution can be executed in a combined way between the integer and floating-point ALUs at the same time, as long as these are available.
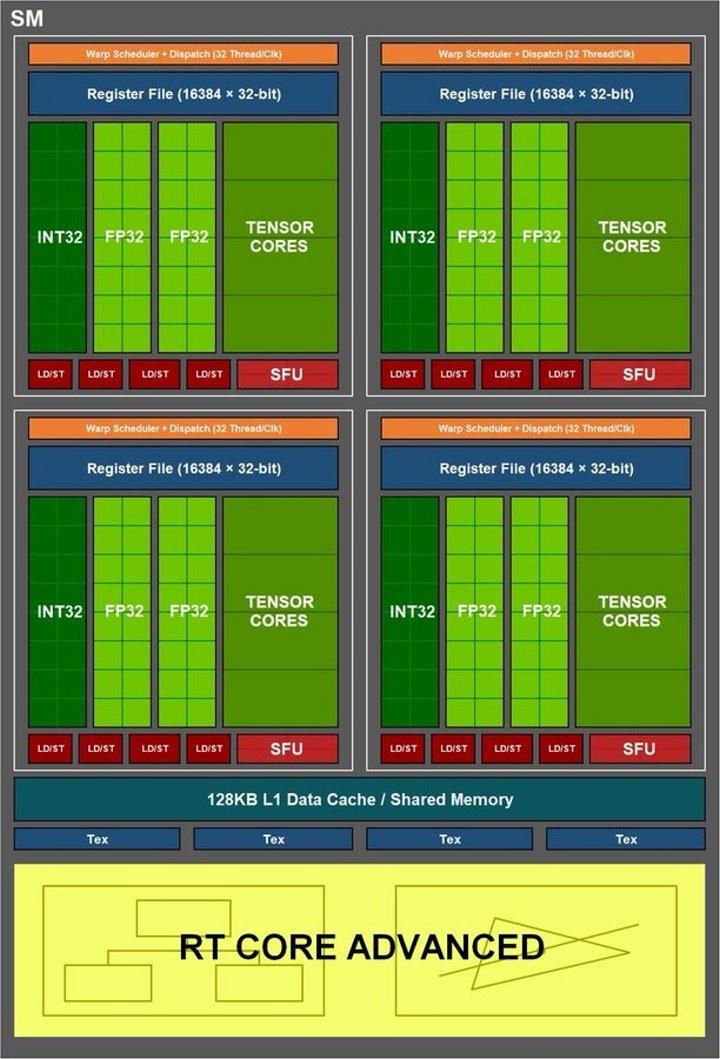
This means that the 32-wave thread distribution, which is the standard size for NVIDIA GPUs, can be distributed over up to 16 integer threads and 16 floating point threads. But, someone at NVIDIA came up with proposing a change for Ampere, which is that set of integer ALUs is switched with a second set of floating point ALUs, which does not require changing the rest of the SM.
Therefore, at certain times and when the condition that a 32-wire floating point wave enters, the calculation speed, measured in TFLOPS, is doubled. Although only when they are met under these conditions and if we had a device to measure the TFLOPS rate we would see that it is not the one that NVIDIA says, which gives the maximum peak in its specifications, but that it would have oscillations.
Tensor Cores on GeForce Ampere

Tensor Cores are systolic arrays that were first released on NVIDIA Volta GPUs, and they are systolic arrays that are the type of execution unit used to speed up AI-based algorithms. These units, unlike the RT Cores, use the control unit of the SM and cannot be used at the same time as the floating point and integer units, so although they can work concurrently, they do so by removing power from the rest. units except RT Cores.
If we add the ALU quantity that the RT Cores form between one generation and the other, we will see that there is the same quantity but with a different configuration. In Turing we have 8 units, 2 per sub-core, of 64 ALUs each in a Tensor 4 x 4 x 4 configuration. While in Ampere the Tensor Cores have a configuration of 4 units, 1 per sub-core, with 128 ALUs. for each of them.
RT Cores on GeForce Ampere
The RT Cores are the least known part of all, as NVIDIA has not given any information about what their internal workings are. We know what it does, how it works, but we do not know what the elements are inside and what changes have occurred from one generation to another.
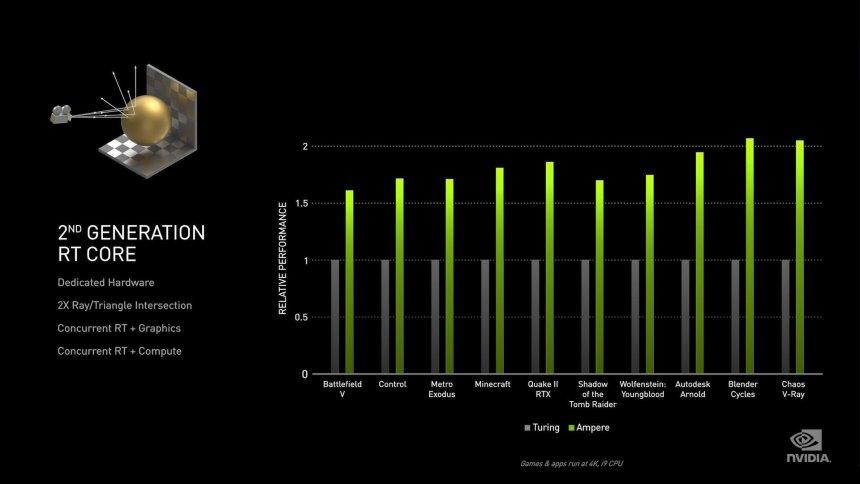
The first thing that stands out is the mention by NVIDIA that RT Cores can now do twice as many intersections per triangle, which does not mean twice as many intersections per second. The reason for this is that when traversing the BVH tree, what it does is to make the intersection of the boxes that are the different nodes of the tree and only the final intersection of the tree is the one made with the triangle, the which is the most complex to perform. The units for calculating the intersection of the boxes are much simpler, in Turing we have in theory four units that work in parallel to go through the different levels of a tree and a single unit that performs the intersection of the ray with the triangle.
The second change at the hardware level is the ability to interpolate the triangle according to its position in time, which is key to the implementation of Ray Tracing with Motion Blur, a technique still unprecedented in games compatible with Ray Tracing. In the event that there are other changes, NVIDIA has not publicly reported this and therefore we cannot draw further conclusions.