Increasing the IPC or Instructions per Cycle, is one of the challenges for any CPU manufacturer when designing increasingly powerful architectures. In this article we are going to tell you what the latest technique is being used by engineers working on developing the latest CPUs to increase the IPC and with it the performance of the processors.
In the history of processor architectures, we have seen how different concepts have been implemented to increase their performance. Approaches like segmentation, superscalar processors, out-of-order execution, etc. All of them have served to have increasingly faster processors and with a higher performance per clock cycle.

The concept of hybrid cores is one more step in achieving higher performance, it is based on the combination in a single core of two types of cores, one optimized for complex instructions and the other for simpler instructions, but in such a way that they share hardware in common and work together as if they were a single CPU core.
The concept of hybrid cores to increase the CPI

In a CPU, not all instructions are equally complex, some of them require a greater number of clock cycles to complete, while others require very few clock cycles to complete because they are much simpler. In the design of new processors the trend up to now was to optimize the most complex instructions in terms of the number of cycles.
But regardless of the type of instruction executed by the cores of our CPU, all of them make use of the same components during the instruction cycle, which means that at the level of energy consumption, the simplest instructions cannot be optimized. which would not have a lower performance in a binary compatible CPU but of lower consumption.
The idea is reduced to the fact that a CPU has two types of execution units, some optimized to execute the most complex instructions and the other for the simplest, this allows optimizing the consumption of the different instructions.
An idea from the world of GPUs
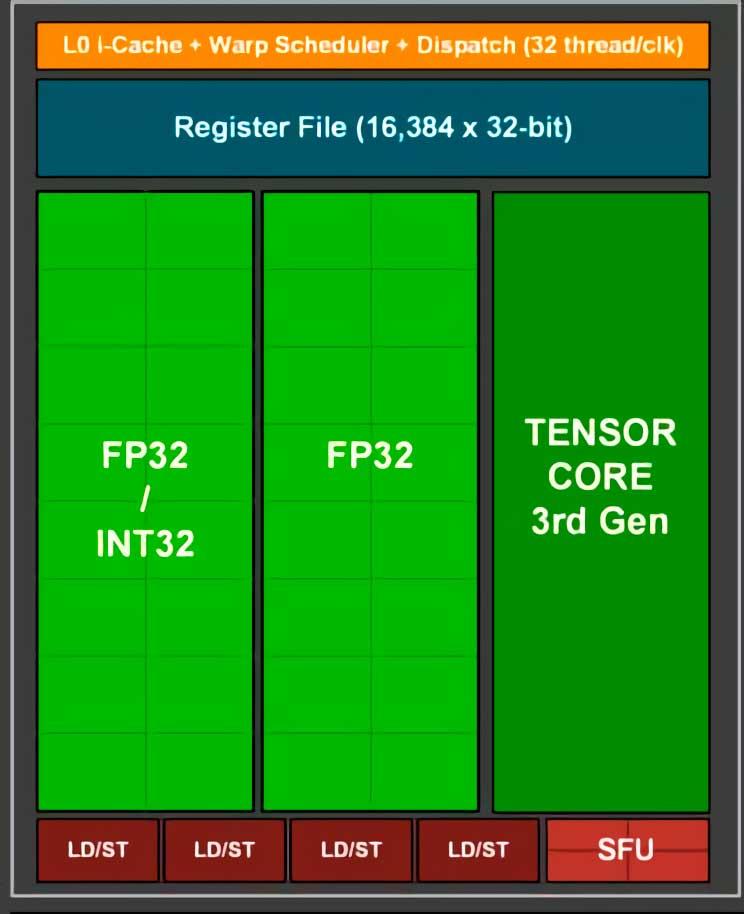
RTX 3000 SM Subcore
In the GPUs we have two different types of ALUs, on the one hand we have the SIMD units, such as the CUDA cores, which manufacturers usually promote to talk about the TFLOPS rate, these units are responsible for the execution stage of extremely simple instructions, but, on the other hand, we have SFUs that are ALUs with a lower calculation rate, since they are optimized for more complex instructions
Well, SFUs would consume much more power to execute a simple instruction than SIMD units, hence the separation that was made years ago in both NVIDIA and AMD GPUs. When the control unit or scheduler of the C0mpute Unit detects an instruction that the SFUs can execute, it simply copies that instruction line and sends it directly to one of the SFUs that is free for execution.
Implementation of hybrid cores to increase the IPC

The concept in a CPU is not different, the instructions fetch phase would be almost the same in both processors, so both processors would share the Program Counter that points to the next instruction, it would be at the end of the fetch phase where the reading of the instruction register where the instruction would be sent to one type of kernel or another for execution.
This means that both cores would actually be like Siamese twins that share part of the hardware by sharing one of the stages of the instruction cycle, but since the instructions would be decoded and executed in the separate part of both cores, not only does the IPC increase in the sense of number of simultaneous instructions per clock cycle, but it also prevents certain instructions from conflicting in the use of resources.
Another of the things that this change allows to do has to do with the management of instructions that reach the processor, which are requests made by the peripherals that stop the execution of the code. You can make the kernel optimized for simple instructions handle them, without the other having to stop.
Its effects on the CPU pipeline
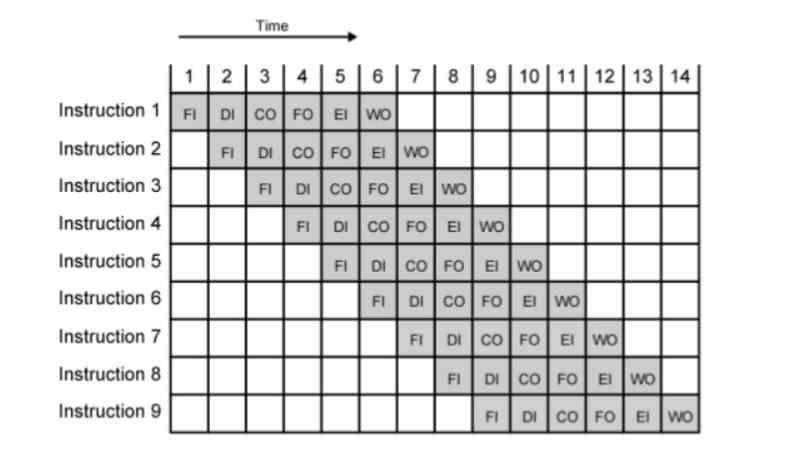
We have to understand that nowadays all processors are segmented into several stages, in such a way that if we have the n instruction in a specific stage, then the n + 1 instruction will be in the previous stage and the n-1 in the next.
The inverse of time is always the frequency (1 / time = frequency), so the trick to increasing the clock speed is to make each of the stages last less, so usually what you do is increase the amount of stages, with the objective that each new stage lasts less and the frequency or clock cycles is higher.
Obviously subdividing a complex instruction into a greater number of instruction cycles is ideal for achieving high clock speeds. But what about the same simple ones? It’s a headache for architects to break up even more simple instructions than they already are today.
Differences of hybrid kernels with big.LITTLE

In a big.LITTLE processor the “big” cores are separated from the “LITTLE” cores in the sense that they work in a switched way with respect to each other, so it is the application that makes a request to the operating system to that one group of cores or another is turned on.
The operation for this type of nucleus is that when they receive a specific interruption then they end the current one and give the witness to the other type. This occurs when the workload on the system is very high or certain conditions are met. In any case, it must be taken into account that in the big.LITTLE approach, each set of nuclei is complete and totally independent.
In the concept of hybrid ALUs, we do not have totally separate cores but rather they share the capture phase as well as access to both the cache hierarchy and memory. In addition, one does not deactivate when the other is working precisely because they share the hardware for memory access and we cannot forget either that big.LITTLE does not increase the IPC of the cores.
Why do hybrid cores increase the IPC of CPUs?

The reason is simple, the fact of having a greater number of execution units, as well as that the hardware of the decoding stage is not shared is what causes that there is no what is called contention, this occurs when two or more instructions they fight over a single resource, in such a way that one has to wait for the other to finish.
Why aren’t processors designed without that problem? Design can be designed, but the budget for transistors is limited and that is why architects cheat by putting common points along the way. Many of the minor updates to an architecture are usually based on avoiding this type of contention by adding more internal paths so that there is no contention.
The IPC as a marketing term is no longer the amount of simultaneous instructions that the core of a CPU can solve simultaneously in the best of conditions, the term is now based on taking a benchmark and looking at the average of the instructions per cycle that it outputs the processor. This is why avoiding contention between instructions is so important and that is why hybrid kernels with decoding and execution stages separated by kernel type are ideal for increasing the IPC.
What current CPU uses hybrid cores to increase the IPC?

The direct answer is a resounding NO, none of the processors that are currently on the market or that are going to come out in the short term are going to use hybrid cores, but they are going to be based more on the big.LITTLE concept in which the cores used will be one or the other depending on the situation, which is going to happen especially in Intel‘s Gen 12 that will be released in a few months.
The one that we do know, through clues in different patents published in the last year, that it will opt for a hybrid core approach is AMD, we do not know if facing Zen 4 or Zen 5. Which does not mean that Intel and even other CPU designers like Apple are not already implementing these solutions.
The cause of it? Increasing the CPI cannot be done forever and it is becoming more and more complex to carry out, hence the need to use techniques such as hybrid cores to increase it.