The recent introduction and imminent launch of the AMD Ryzen 5000 series of processors, based on the Zen 3 architecture, has been accompanied by the crown for AMD, at least for the moment, when it comes to power. But what is it that makes the Zen 3 architecture so fast? What elements have you added in the third generation of Zen architecture for better performance?
Before starting, it should be noted that the Ryzen 5000 are not the direct successors of the AMD Ryzen 4000 , which are monolithic SoCs, but rather the Ryzen 3000, since the Ryzen 5000 are also MCM systems based on chiplets.

In this system, we have on the one hand the IOD where the Northbridge of the system is located , baptized as Scalable Data Fabric or SDF by AMD and the Southbridge that is called IO Hub by the company of the Ryzens and the Radeons. Said IOD has not changed with respect to the Ryzen 3000 except in the fact of supporting faster memories since it is through the IOD that the cores have access to the RAM of the system.

However, we cannot say that they have taken the IO Die of the Ryzen 3000 as is and transplanted it as is, but that they have improved it through their experience when creating the Ryzen 4000 for computers with lower consumption than a PC desktop.
So where there have been the really important changes is in the CCD or Core Complex Die , the small chip that stores the different cores and their cache hierarchy, which is where there have been the most important changes.
The new Core Complex Die of Zen 3 architecture
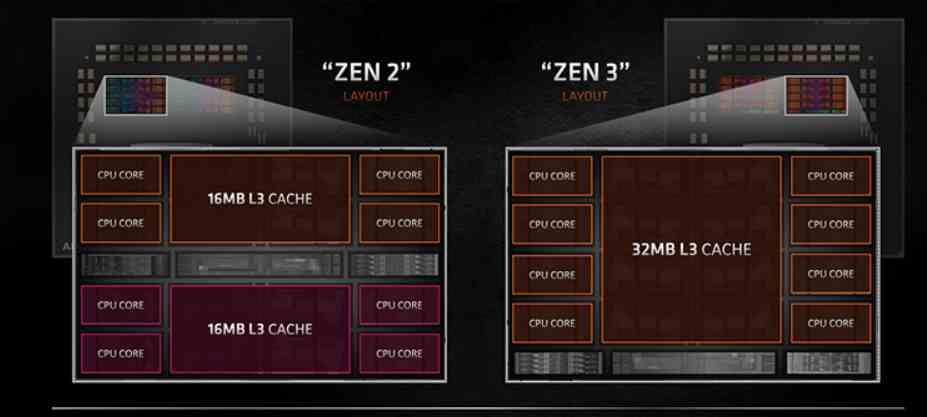
The CCD in Zen 2 was made up of two CCXs with 4 cores each, with their L3 cache shared within each of the CCXs . which causes a series of latency problems when several cores within the same CCD but in different CCX had to communicate, since if a nucleus had to communicate with another that was in the other CCX then it had to go through the IOD despite to be on the same CCD.
The change that AMD has made in the Zen 3 architecture is very simple, they have made 8 cores share the L3 cache instead of 4 cores at the same time . So we have gone from having 2 4-core CCXs per CCD to 1 8-core CCX per CCD . This in applications intended to run with 8 or fewer cores results in a performance advantage.
But where A MD has made improvements at the level of each core is in the Load / Store units , as well as in the front-end or control unit , improvements that have been key to achieving an average performance of 19% above its predecessor, Zen 2.
The key is the control unit
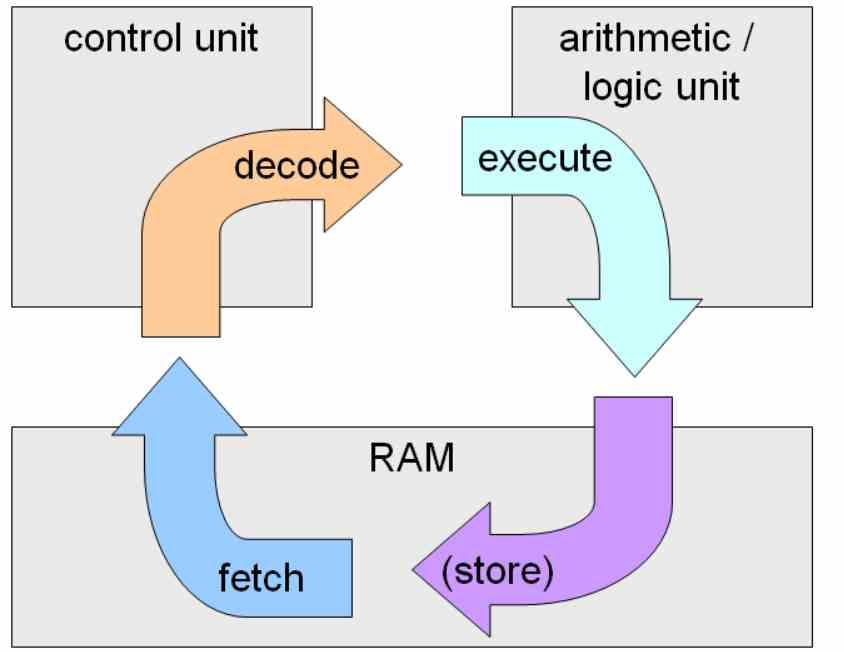
When we talk about Front-End we are referring to the control unit of a CPU, while ALUs are the Back-end. Within the instruction cycle , fetch-decode-execute, the first two stages are the work of the control unit , while the second part is the work of the ALUs or execution units.
All contemporary x86 processors do not execute the instructions under said ISA , but instead decrypt the instructions in an internal ISA RISC that is where the instructions are actually executed in the execution units. This internal ISA can change even between members of the same architecture and is key when increasing the IPC of the processors.
That is why AMD has remade the control unit and implemented a new, much more efficient internal ISA that allows instructions to be performed in fewer clock cycles per instruction (CPI), causing the average number of instructions per cycle to increase with it. .