One of the limitations that desktop and laptop graphics cards have is the inability to run multiple operating systems at the same time or virtual machines. This differentiation that some GPUs have is called virtualization and in this article we are going to explain what it is and what changes it requires in the hardware.
Before the arrival of the personal computer, people worked in terminals connected to a central mini-computer, which was in charge of carrying out all the tasks. With the advent of cloud computing running various operating systems in virtual machines, virtualization is not only necessary on CPUs, but also on GPUs.

Why is virtualization necessary on GPUs?
Virtualization is the ability of hardware to create multiple versions of itself so that it can be used by multiple virtual machines. For example a part of a CPU that has been virtualized will be seen by an operating system running in a virtual machine, while other virtual machines will see other parts of the CPU as a single and distinct CPU. In that case we have virtualized the CPU, as we have created a virtual version of each operating system running on the system.
In the case of GPUs, the command lists for graphics and computing are written in certain parts of the memory in particular and in general the GPUs that we mount in our PCs are designed to work in a single operating system without any virtual machine in between. .
This is not the case with graphics cards for data centers, where several different instances, virtual machines, of an operating system are usually running and it is necessary for each client to access the GPU. It is in this case where virtualization in GPUs is necessary
Virtualization from the GPU side

GPUs also need changes at the hardware level to support virtualization. Because of this, graphics cards with this capacity are usually sold only to markets far away from desktop PCs and therefore have a much higher price than desktop GPUs. Today you can hire the power of a GPU in the cloud to accelerate certain scientific works, render a scene remotely for a movie or a series, and so on.
SR-IOV
Each PCI Express peripheral has a unique memory address on each PC’s memory map. What means that if we are using a virtualized environment we cannot access the hardware that is connected to these ports such as graphics cards many times. Usually the virtual machines that we run on desktop PCs do not have the ability to use the graphics card, which will only be accessible to the guest operating system.
The solution to this is SR-IOV, which virtualizes the PCI Express port and allows multiple virtual machines to access these memory addresses simultaneously. In the PC, peripheral communication is made through calls to certain memory addresses. Although today these calls do not correspond to physical memory addresses, but virtual ones, the inviolable rule is that the content of a memory address cannot be manipulated by two clients at the same time, since then there are conflicts regarding the content of the data.
The SR-IOV to function needs a network controller integrated in the PCI Express device, in the case that we are dealing with the graphics card, which receives the requests from the different virtual machines that need access to its resources.
Changes to DMA drives for GPU virtualization
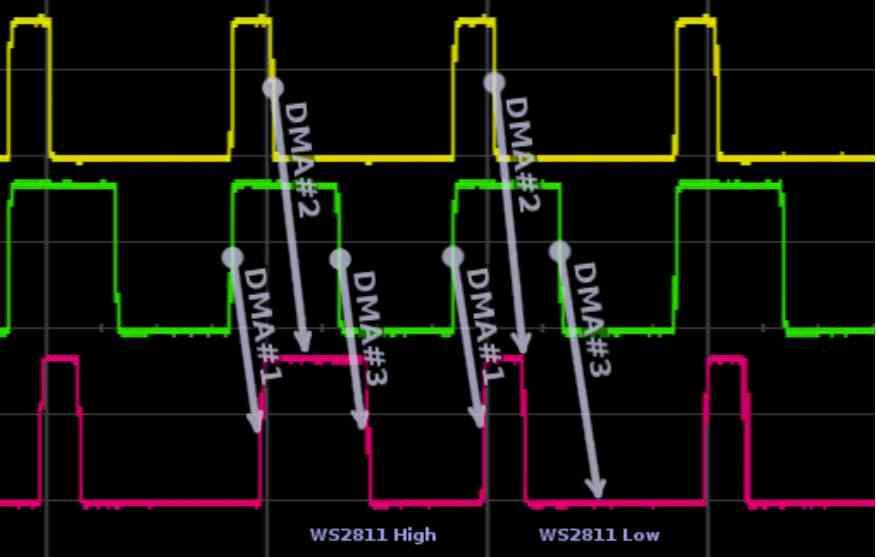
The first change occurs in the DMA units, these units usually come in pairs in the GPUs that we use in PCs and give access to the RAM of the system, not to be confused with the VRAM, through an alternative channel. At each frame the GPU will have to access to read the screen list in a part of the RAM or it will have to copy the data from the RAM to the VRAM in case it needs that data later. This uses one DMA unit in each direction. In the case of GPUs with virtualization? They use several DMA units in parallel or one DMA unit with several simultaneous access channels .
The use of the different channels by the virtual GPUs is managed by the integrated network controller, which is responsible for managing requests to RAM, either physically or to another peripheral also connected to the PCI Express port. So if the different virtual GPUs have to access, for example, an SSD disk, they do so through the DMA units.
GPU command processor changes
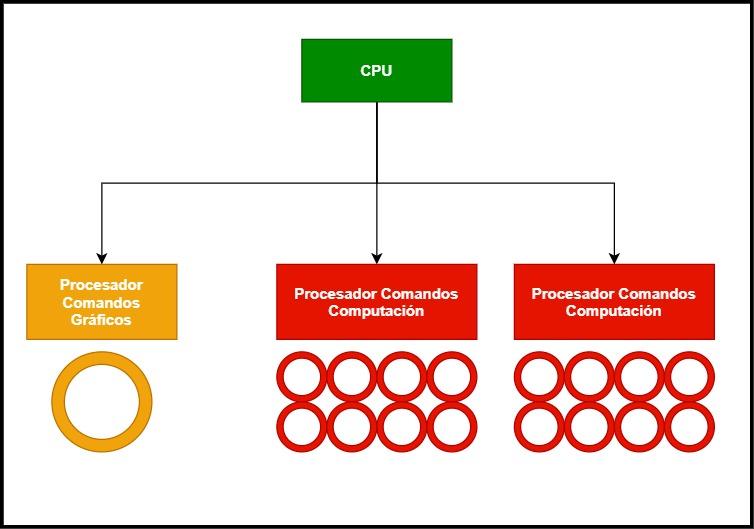
The second change is in the command processor. All GPUs for computing without graphics in the middle are used to working in several contexts at the same time, this is because they are very small command lists that are solved in a short time, on the other hand if we talk about graphics the thing it changes completely, since a single list of commands is usually used.
What about non-virtualized GPUs that use multiple displays? It is not the same as using several operating systems in virtual machines, since the screen list in these cases comes from a single operating system that indicates to the GPU the video output through which each image must be transmitted.
Therefore, it is necessary to implement a special graphics command processor, which works in conjunction with the DMA units and the integrated network controller to function not as one GPU, but as several different and virtual ones.
GPU resources are distributed in virtualization
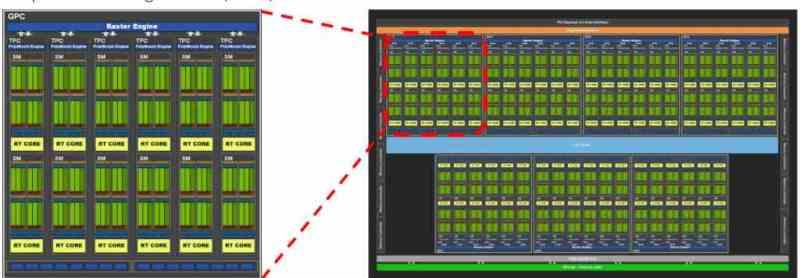
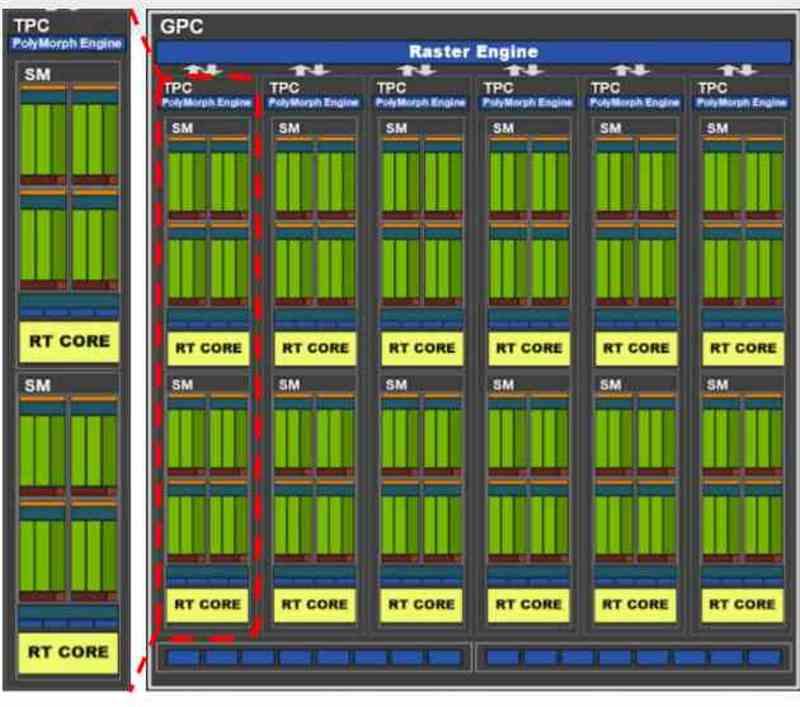
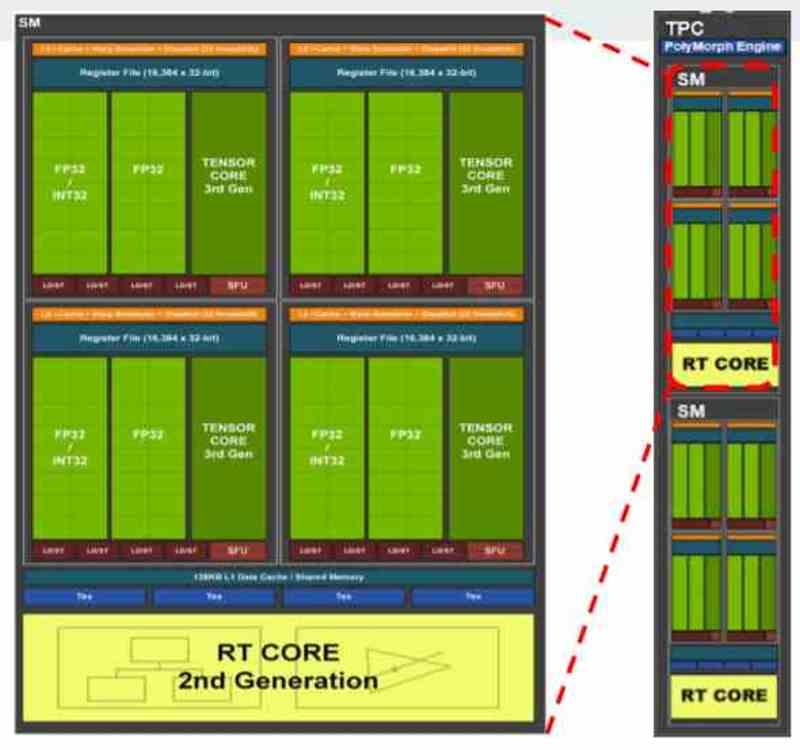
All contemporary graphics cards are usually divided into several blocks within other blocks, for example if we take the GA102 from the NVIDIA RTX 3080 or 3090 we will see that it is initially composed of several GPCs, within which there are several TPCs and in each TPC we have 2 SM.
Depending on how the distribution of resources has been proposed by the manufacturer, we can find a distribution in which each virtual machine corresponds to a GPC, so in the case of the GA102 we would be talking about a virtualization of the GPU in 7 different. Although it would also be possible to do it at the TPC level, in that case up to 36 virtual machines can be created, but as we understand the power for each one would be very different.
In the GPUs what is assigned in NVIDIA is a complete GPC or what in AMD is known as Shader Engine, since each of these parts have all the necessary components to function as a GPU by themselves. In cases where the virtualized GPU is not used for rendering but for computing, then the distribution is at the TPC level or its equivalent in AMD RDNA, the WGP.