DirectX is an API that has been with us since Windows 95, it is a high-level API that abstractly represents different components of the PC to facilitate the communication of programs with the different peripherals. DirectML is one of the branches of DirectX 12 thought to facilitate the use of specialized units in artificial intelligence that have been implemented in hardware in recent years.
With the arrival of the new generation consoles in combination with the AMD RX 6000 we finally have both manufacturers of graphics cards with GPUs capable of executing algorithms designed for AI, however, the approach of both companies is different. While NVIDIA tries to tie developers to libraries that are exclusively intended for their hardware, AMD has chosen not to develop its own tools and to use the Microsoft DirectM L API .

Taking into account the two next generation consoles, PlayStation 5 and Xbox Series X, then it is clear that when it comes to the use of artificial intelligence algorithms in games then AMD is going to win, but we have to start from the idea that DirectML is not designed for specific hardware and is completely platform agnostic.
DirectML works under any type of processor
DirectML is based on the idea that we can execute any type of instruction on any type of processor, but not all are equally efficient, this means that some architectures will be more efficient than others when executing these algorithms.
The fastest type of unit are called ASICs, these are neural processors (NPUs) whose ALUs are systolic arrays and are optimized to execute these algorithms more quickly, examples of this type of units are the following:
- The Tensor Core of the NVIDIA RTX
- The NPUs of the different SoCs for Smartphones
The second type of unit are FPGAs configured as if they were ASICs, but due to the larger area of the FPGAs and the lower clock speed they are less efficient.
The third type is the GPUs, these do not have specialized units, but rather it is about executing the AI algorithms as if they were Compute Shader programs, they are not as efficient as an FPGA or an ASIC, but they are much more efficient than a CPU to when executing this kind of algorithm.

DirectML is designed to use an ASIC if it is in the system, if it is not found then it will look for the GPU to run it and ultimately the CPU as a very desperate resource. On the other hand, libraries like NVIDIA cudNN will only work with the NVIDIA GPU and through the Tensor Cores, ignoring other types of units in the system.
Super-Resolution

It is known as Super-Resolution through AI when using an artificial intelligence algorithm to generate a higher resolution version of a given image , which has the advantage of being able to increase the output resolution of the games without having to render it natively and consume much less resources: Super-Resolution is only worth it when the time to render at a native resolution is greater than the time to render at a lower resolution rescan and perform the scaling algorithm through AI.

Keep in mind that there are two types of super-resolution algorithms:
- Those of the first type are used in films and therefore in already predefined frames that are updated every x ms and where the decoding of them plus scaling via AI is done with very little power required. The automatic scaling systems of some televisions are based on algorithms of this type.
- The second type is what we have seen with NVIDIA’s DLSS , in real-time games there is no predefined version of the image in memory, it has to be generated and then the processor that executes the algorithm has a few milliseconds to apply it. However, it must be clarified that what DLSS does is not exclusive to NVIDIA and anyone can make a counterpart.
The first type is very easy to train them since we can use the higher resolution version of a movie so that the AI can feed back during the training process. But in a video game it is different, each frame does not previously exist so the training used is much more complex and requires continuous supervision, hence, for example, NVIDIA has to use the Saturn-V supercomputers to train the AI.

The other problem is when executing the algorithm that has been achieved with the training. In the case of DLSS 2.0. A type of algorithm of the second type, its Tensor Cores have an average of 1.5 ms to carry out the whole process, which means that it needs a high power to do it at that speed, hence the huge amount of TFLOPS in the Tensor Cores.
In DirectML you can apply an algorithm of the same style, but it must be understood that the less powerful the part that applies the algorithm is, then the faster the GPU will have to be than rendering the scene in advance in order to give the unit in charge time to apply the super-resolution algorithm.
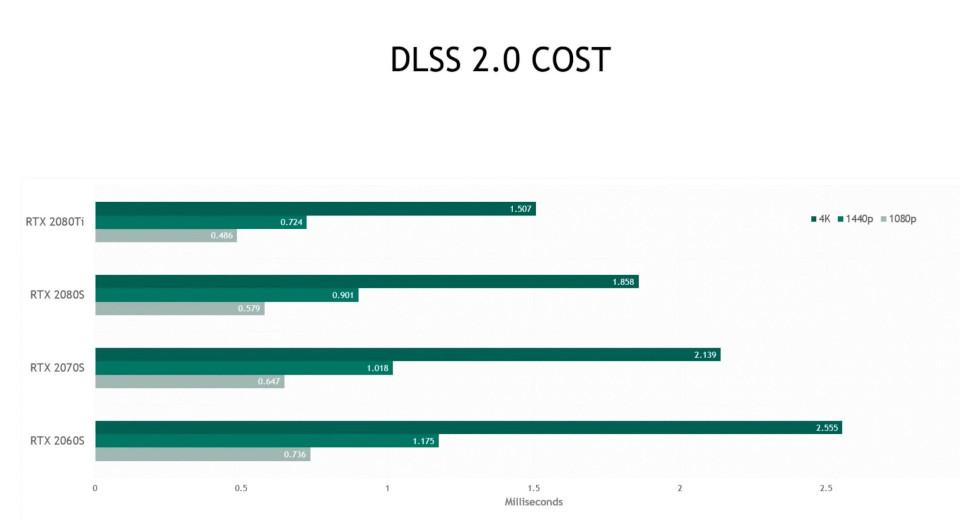
We may eventually see a demise of DLSS 2.0 in favor of the DirectML algorithm, but it remains to be seen if AMD’s GPUs are fast enough and hold up against NVIDIA’s . NVIDIA Tensor Core can perform FP16 and Int8 calculations at a 4: 1 ratio relative to any AMD GPU with similar specs. Not surprisingly, DirectML was introduced for the first time using the Tensor Cores of an NVIDIA Volta .
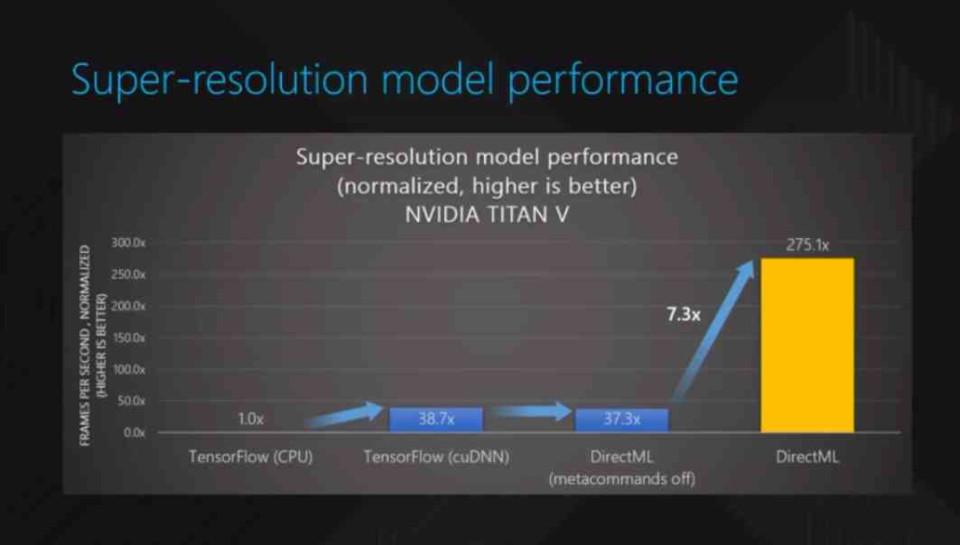
It must be taken into account that these algorithms do not generate the image in native 4K, but rather make an estimate of the value of each pixel and it must be taken into account that there is a range of error that can lead to representations that are far from what is expected. That is why the games that support this type of technique do not do it out of the box and the support is limited for the vast majority of games, but when the AI generates images very close to native 4K then the savings are significant.