
GPUs like CPUs are a type of processor, but they are optimized for parallel computing and real-time graphics generation. However, despite the fact that we have different types of architectures, each and every one of the GPUs has an organization in and therefore they share. Which we are going to explain in this article in a detailed and detailed way.
In this article we are not going to deal with a specific GPU architecture, but that of all of them in general and therefore when you see the diagram that manufacturers usually launch about the organization of their next GPU you can understand it without problems. Regardless of whether this is an integrated or dedicated GPU and the degree of power they have.
Organization of a contemporary GPU

To understand how a GPU is organized, we have to think of a Russian doll or matrioshka, which is made up of several dolls inside. Which we could also speak of a set storing a series of subsets progressively. In other words, GPUs are organized in such a way that the different sets that compose them are in many cases one within another.
Thanks to this division, we will understand something as complex as a GPU much better, since from the simple we can build the complex. With that said, let’s start with the first component.
Set A in the organization of a GPU: the shader units
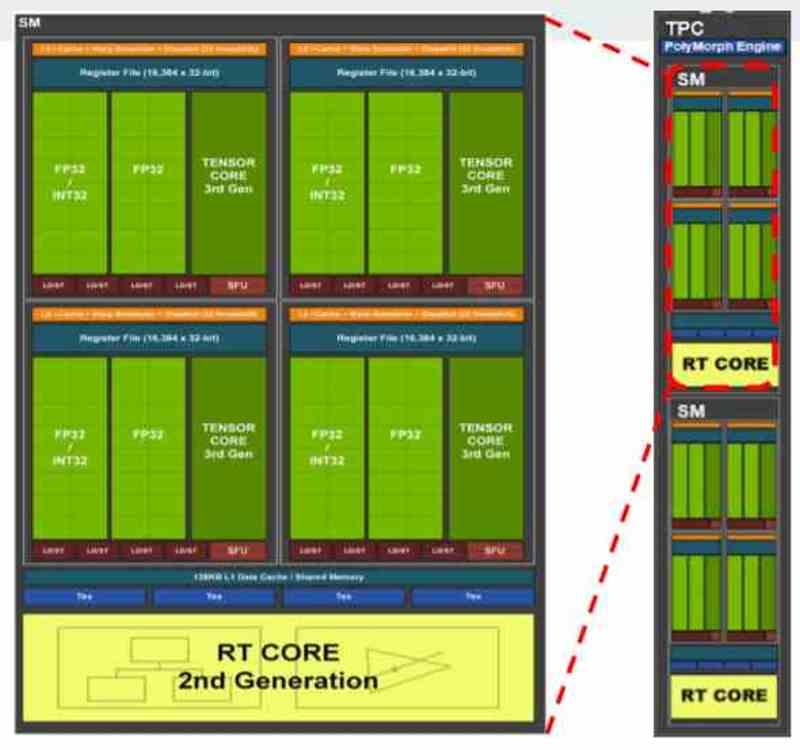
The first of the sets are the shader units. By themselves they are processors, but unlike CPUs they are not designed for parallelism from instructions, ILP, but from threads of execution, TLP. Regardless of whether we are talking about GPUs from AMD, NVIDIA, Intel or any other brand, all contemporary GPUs are made up of:
- SIMD units and their records
- Scalar Units and their registers.
- Planner
- Shared Local Memory
- Texture Filtering Unit
- Top-notch data and / or texture cache
- Load / Store drives to move data to and from cache and shared memory.
- Lightning Intersection Unit.
- Systolic Arrays or Tensor Units
- Export Bus that exports data out of Set A and into the different components of Set B.
Set B in the organization of a GPU : Shader Array / Shader Engine / GPC
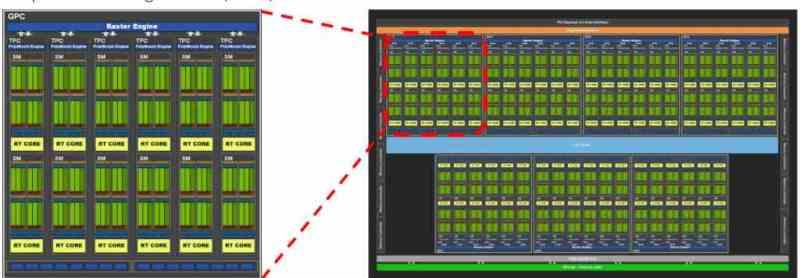
Set B includes set A in its interior, but initially adds the instruction and constant caches. In GPUs, as well as CPUs, the first level cache is divided into two parts, one for data and the other for instructions. The difference is that in the case of GPUs the instruction cache is outside the shader units and therefore they are in set B.
Set B in the organization of a GPU therefore includes a series of shader units, which communicate with each other through the common communication interface between them, allowing them to communicate with each other. On the other hand, the different shader units are not alone in Set B, since this is where there are several fixed function units for rendering graphics, as now.
- Primitive Unit: This is invoked during the World Space Pipeline or Geometric Pipeline, it is in charge of tessellation of the geometry of the scene.
- Rasterization Unit: It performs the rasterization of the primitives, converting the triangles into pixel fragments and its stage being the one that begins the so-called Screen Space Pipeline or Rasterization Phase.
- ROPS: Units that write the image buffers, act during two stages. In the raster phase prior to the texturing phase, they generate the depth buffer (Z-Buffer) while in the phase after the texturing phase, they receive the result of this stage to generate the Color Buffer or the different Render Targets (delayed rendering).
Set C in the architecture of a GPU :
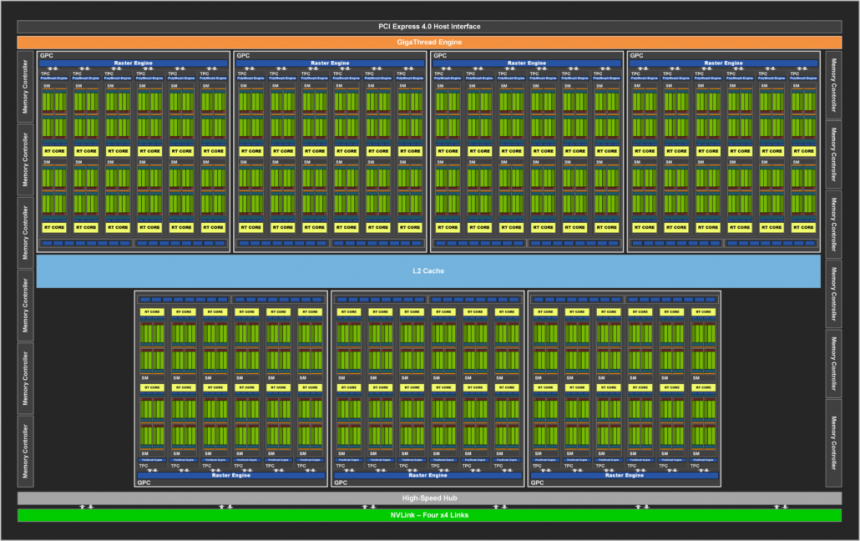
We already have almost the complete GPU or the GPU without the accelerators, it consists of the following components:
- Several B-Sets inside.
- Shared Global Memory : A Scratchpad and therefore outside the cache hierarchy to communicate B-Sets with each other.
- Geometric Unit: It has the ability to read the pointers to the RAM that point to the geometry of the scene, with this it is possible to eliminate non-visible or superfluous geometry so that it is not rendered uselessly in the frame.
- Command Processors (Graphics and Computing)
- Last Level Cache: All the elements of the GPU are clients of this cache so it has to have an immense communication ring, all the components of Set B have direct contact with the L2 cache as well as all the components of Set C itself .
The Last Level Cache (LLC) is important since it is the cache that gives us coherence between all the elements of Set C with each other, obviously including Sets B within it. Not only that, but it allows not over-saturating the external memory controller since with this it is the LLC itself, together with the MMU unit (s) of the GPU, that are responsible for capturing instructions and data from RAM. Think of the Last Level Cache as a kind of logistics warehouse in which all the elements of Set C send and / or receive their packages and their logistics are controlled by the MMU, which is the unit in charge of doing so.
Final set, full GPU

With all this we already have the full GPU, set D includes the main unit that is the GPU in charge of rendering the graphics of our favorite games, but it is not the highest level of a GPU, since we are missing a series of coprocessors support. These do not act to render graphics directly, but without them the GPU would not be able to function. These elements are generally:
- The GFX Unit including its top-level cache
- The North Bridge or Northbridge of the GPU, if this is in a heterogeneous SoC (with a CPU) but with a shared memory well then they will use a common Northbridge. All elements of Set D are connected to the Northbridge
- Accelerators: Video Encoders, Display Adapters, are connected to the Northbridge. In the case of the Display Adapter, it is the one that sends the video signal to the DisplayPort or HDMI port
- DMA drives: If there are two RAM addressing spaces (even with the same physical well), the DMA drive allows data to be passed from one RAM space to another. In the case of a separate GPU, the DMA units serve as communication with the CPU or other GPUs.
- Controller and memory interface: It allows to communicate the elements of Set D with the external RAM. They are connected to the Northbridge and it is the only path to the outside RAM.
With all this you already have the complete organization of a GPU, with which you can read the diagram of a GPU much better and understand how it is organized internally.