
A few weeks ago a patent assigned to AMD was published, it explains how their GPUs divided into several chips will work, which will be a general rule not only for them but also for the competition. Where we know that NVIDIA Hopper and Intel Xe-HP are divided into several chips. But AMD’s solution is somewhat different from the one proposed by its competition, we explain the patent for AMD chiplets.
The reason why dual GPUs have disappeared from the domestic environment and is the answer to the question of why we no longer see graphics cards compatible with NVIDIA SLI or AMD Crossfire is the same, the applications we use on our PCs are programmed to use a single GPU.

In PC video games, when making use of a dual GPU. Techniques such as Alternate Frame Rendering are used, in which each GPU renders an alternate frame with respect to the other, or Split Frame Rendering where the pair of GPUs divide the work of a single frame.
In computing via GPU this problem does not occur, which is why in systems in which graphics cards are not used to render graphics, we find several of them operating in parallel without problems. What’s more, applications that make use of GPUs as parallel data processors are already designed to take advantage of GPUs in that way.
The increase in the size of GPUs in recent years

If we look at the evolution of GPUs in recent years, we will see there has been considerable growth in the area of top-of-the-line GPUs from one generation to the next.
The worst of the present scenario? There is no GPU that has the ideal performance for 4K gaming yet. It must be taken into account that a native 4K image has 4 times more pixels than one at 1080p and therefore we are talking about a data movement that is four times that necessary for Full HD.
In the current situation in VRAM, we have the case of GDDR6, said memory uses a 32-bit interface per chip, divided into two 16-bit channels, but, with a clock speed that causes its energy consumption to skyrocket, it which leads us to look for other solutions to expand the bandwidth.
Expanding the bandwidth of VRAM

If we want to expand the bandwidth there are two options:
- The first is to increase the memory clock speed, but it must be taken into account that the voltage is squared when the MHz of this increases, and with it the energy consumption.
- The second is to increase the number of pins, which would be to go from 32 bits to 64 bits.
We can’t forget about things like the PAM-4 used in the GDDR6X either, but that has been a move by Micron to avoid reaching high clock speeds. So a 64-bit bus per VRAM chip should be expected for a possible GDDR7 ..
We don’t know what VRAM makers are going to do, but increasing the clock speed is not the option we think they will end up adopting within a limited energy budget.

We don’t know what VRAM makers are going to do, but increasing the clock speed is not the option we think they will end up adopting.
However, the interfaces between the GPU and the VRAM are located on the outside of the perimeter of the GPU itself. So increasing the number of bits of it is to expand the periphery of said GPU, and therefore make it larger.
What is a serious of added problems due to the high size in terms of cost, this will force graphics card manufacturers to use several chips instead of one, and it is at this point where we enter the so-called chiplets.
Chiplet-based GPU types

There are two ways to divide a GPU into Chiplets:
- Dividing a single, massive-sized GPU into multiple chiplets, the trade-off of this is that communication between the different parties requires massive bandwidth that may not be feasible without the use of special intercoms.
- Use several GPUS in the same space that work together as one.
In the HardZone article entitled “This is how the GPUs based on Chiplets that we will see in the future will be” you can read about the configuration of the first type, whereas the AMD patent regarding its GPU with chiplets refers to those of the second type .
Exploring the patent for AMD chiplets:
The first point that appears in every patent is the usefulness of the invention, which always comes in its background, which in which we are concerned is the following:
Conventional monolithic designs that are becoming increasingly expensive to manufacture. Chiplets have been used successfully in CPU architectures to reduce manufacturing cost and improve yields. Since its heterogeneous computational nature adapts more naturally to separate CPU cores in different units that do not require much intercommunication between them.
The mention of CPUs is clear that it refers to AMD Ryzen and is that a good part of the design team of Zen architectures was displaced to the Radeon Technology Group to work on improving the RDNA architecture. The concept of chiplets is not the first one inherited from the Zen, the other is the Infinity Cache, which inherits the concept of “Victim Cache” from the Zen.
Second, the intercom problem you refer to refers to the enormous bandwidth that GPUs need to communicate their elements with each other. Which is the impediment in the face of the construction of these in chiplets, due to the energy consumed in the transfer of data.
The work of a GPU is parallel by nature. However, the geometry that is processed by a GPU not only includes sections of work in parallel, but also works that require to be synchronized in a specific order between the different sections.
The consequence of it? A programming model for a GPU that distributes work across different threads is often inefficient, as parallelism is difficult to distribute across multiple different workgroups and chiplets, as it is difficult and expensive to synchronize memory content of resources shared across the system.

The part that we have put in bold is the explanation from the perspective of software development for which we have not seen GPUs based on chiplets. It is not only a hardware problem but a software problem, so it is necessary to simplify.
Also, from a logical point of view, applications are written with the view that the system has only one GPU. That is, although a conventional GPU includes many GPU cores, applications are programmed to target a single device. Therefore, it has historically been a challenge to bring the chiplet design methodology to GPU architectures.
This part is key to understanding the patent, AMD is not talking about dividing a single GPU into chiplets which is what it does in its CPUs, but rather talking about using several GPUs in which each one is a chiplet, it is important to keep in mind this difference, since AMD’s solution seems more focused on creating a Crossfire in which it is not necessary for programmers to adapt their programs for various GPUs.
Once the problem is defined, the next point is to talk about the solution offered by the patent.
Exploring the AMD Chiplet Patent: The Solution
The solution to the exposed problem proposed by AMD is the following:
To improve system performance using GPU chiplets while maintaining the current programming model, the patent illustrates systems and methods that use high-bandwidth passive crosslinks to connect GPU chiplets to each other.
The important part of the patent are those Crosslinks, which we will talk about later in this article, these are the communication interface between the different chiplets, that is, how information is transmitted between them.
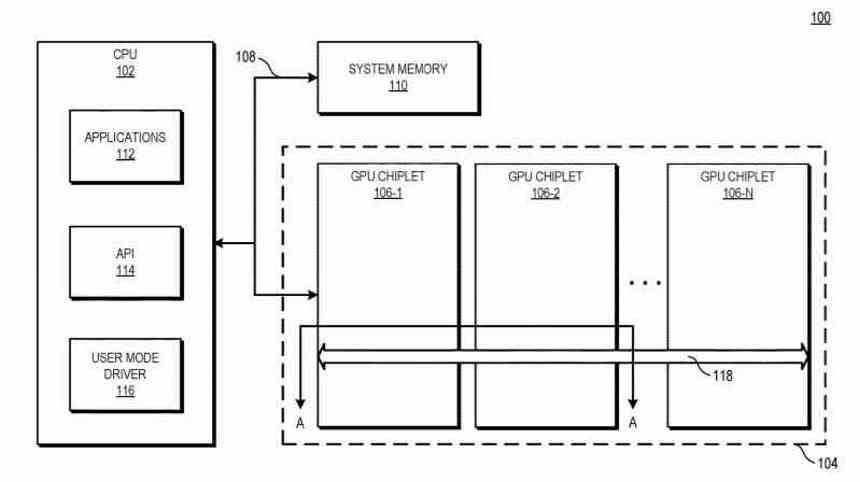
In various implementations, a system includes the central processing unit (CPU) that is connected to the first GPU chiplet in the chain, which is connected to a second chiplet through the passive crosslink. In some implementations, the passive crosslink is a passive interposer that handles communication between chiplets .
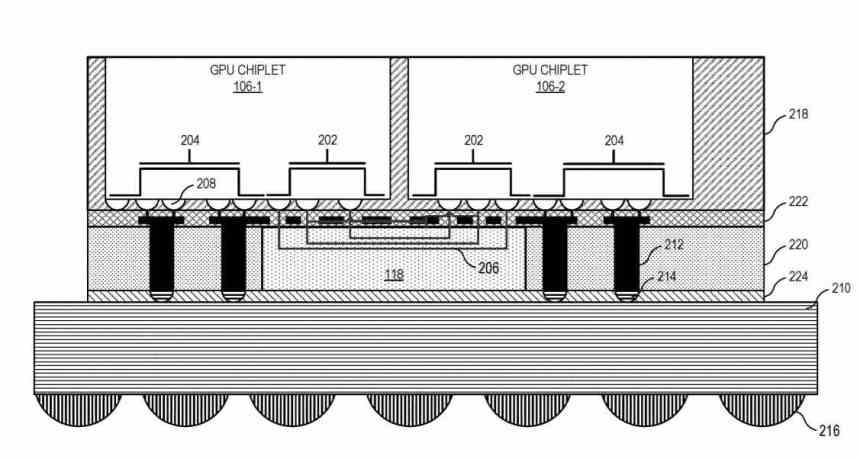
Basically, it boils down to the fact that we now have a dual GPU functioning as one, which is composed of two interconnected chips through an interposer that would be located below.
High bandwidth passive crosslinks
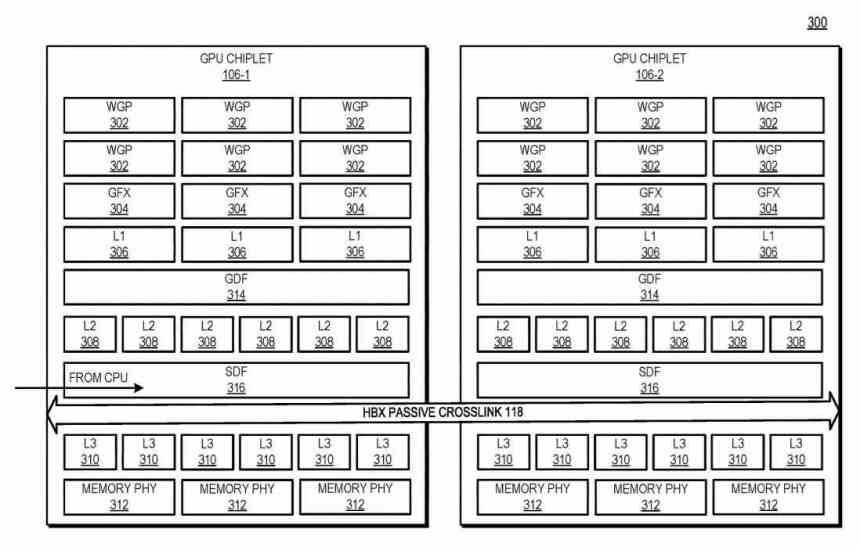
How do chiplets communicate with the interposer? Using a type of interface that communicates the Scalable Data Fabric (SDF) of each of the chiplets with each other, the SDF in AMD GPUs is the part that normally sits between the GPU’s top-level cache and the interface. memory, but in this case there is an L3 cache between the SDF of each GPU chiplet and the SDF and before that an interface that intercommunicates the two chiplets with each other.
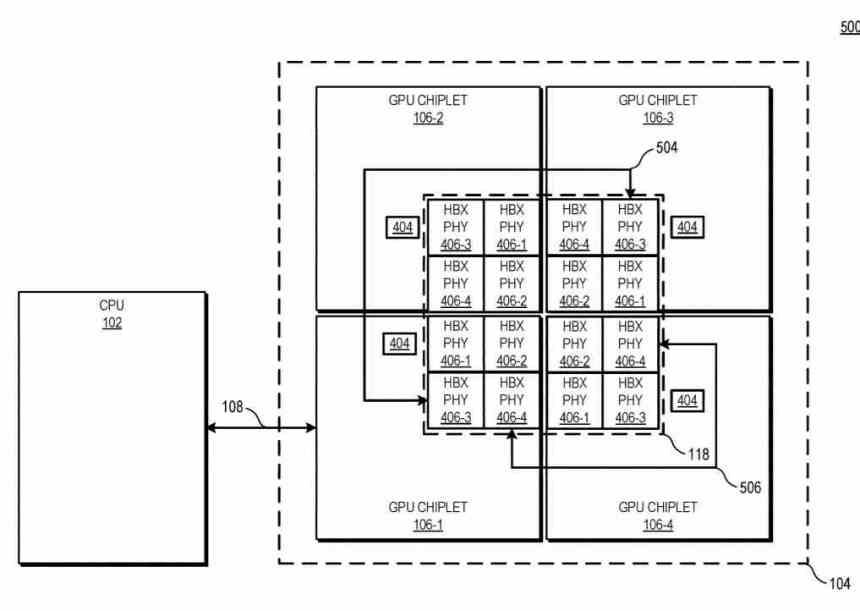
In this diagram you can see the example with 4 GPUs chiplets, the number of HBX interfaces is always 2 2 in which n is the number of chiplets in the interposer. Looking at the level of the cache hierarchy, L0 (not described in the patent) is local to each Compute Unit, L1 to each Shader Array, L2 to each GPU chiplet, while L3 cache would be a novelty, this It is described as the last level cache or LCC of the entire GPU set.
Currently, various architectures have at least one level of cache that is consistent across the entire GPU. Here, in a chiplet-based GPU architecture, it places those physical resources on separate chips and communicates them in such a way that said top-level cache remains consistent across all the GPU chiplets. Thus, despite operating in a massively parallelized environment, the L3 cache must be consistent.
During an operation, the request to a memory address from the CPU to the GPU is transmitted to a single GPU chiplet, which communicates with the passive high-width crosslink to locate the data. From a CPU point of view, it looks like you’re heading for a monolithic single-chip GPU. This allows the use of a high capacity GPU, composed of several chiplets as if it were a single GPU for the application.
This is why AMD’s solution is not the division of a GPU into several different chiplets, but the use of several GPUs as if it were one, thereby solving one of the problems that the AMD Crossfire brought with it and allowing any software you can use multiple GPUs at the same time as if they were one and without having to adapt the code.
The other key to passive crosslinks is the fact that contrary to what many of us speculated, they do not communicate with the GPU using channels through silicon or TSV, but that AMD has created a proprietary intercommunication for the construction of SoCs. , CPUs and GPUs, both in 2.5DIC and 3DIC, which leads us to wonder if the X3D interface that has to replace its Infinity Fabric.
AMD chiplets are for RDNA 3 onwards

The fact that the problem when using several GPUs is not a problem of applications designed for computing through GPUs makes it very clear that the solution proposed by AMD in its patent is aimed at the domestic market, specifically GPUs of RDNA architectures, there are several clues about it:
- In the diagrams of the chiplets of the patent, the term WGP appears, which is typical of the RDNA architecture and not of CDNA and / or GCN.
- The mention in a part of the patent of the use of GDDR memory, which is typical for domestic GPUs.
The patent does not describe a specific GPU to us, but we can assume that AMD will release the first chiplet-based dual GPU when RDNA 3 launches. This will allow AMD to create a single GPU instead of different variations of an architecture in the form of different chips as has been the case today.

AMD’s solution also contrasts with what is rumored by NVIDIA and Intel. From the first we know that Hopper will be its first architecture based on chiplets, but we do not know its target market, so it may well be aimed at the high-performance computing market such as gaming.
As for Intel, we know that Intel Xe-HP is a GPU also composed of chiplets, but without the need for a solution like AMD’s, since Intel’s target for said GPU is not the domestic market.