
If there is something that draws the attention of graphic cards, it is the enormous speed that their memories carry, understanding as speed the amount of data they transmit per second, that is, what is known as bandwidth. But what are the reasons that GPUs need the bandwidth of the VRAM to be so large? We explain them to you.
Next, we are going to explain the theory behind the fact that graphic cards use special memories with a high transfer speed, some concepts many will already know in advance, while others will be unknown because they are not usually discussed in the graphics card marketing.
The bandwidths between the GPU and VRAM

The GPU uses various bandwidths to render a scene in 3D, which we will list below:
- Color Buffer (Bc): It is part of the so-called Backbuffer or back buffer on which the GPU draws the scene. In it each pixel has RGBA components, if the rendering is delayed then several buffers are generated to generate the G-Buffer. In current APIs, GPUs support up to 8 buffers of this type at the same time.
- Depth Buffer (Bz): Also known as Z-Buffer, it is the buffer where the position of the pixels of each object with respect to the camera is stored. combines with the Stencil Buffer. Unlike the Color Buffer, this is not generated during the post-texturing stage, but in the previous one, the rasterization.
- Texturing (Bt): GPUs use texture maps so large that they do not fit in memory and have to be imported from VRAM, it is a read-only operation. On the other hand, post-processing effects read the image buffer as if they were textures.
This is summarized in the following diagram:
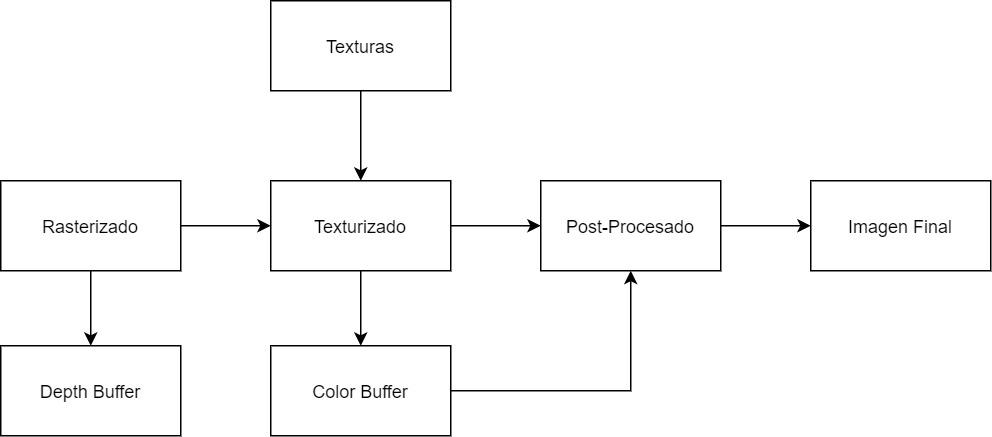
Since VRAM memory chips are Full Duplex and transmit both read and write at the same time, the bandwidth is the same in both directions. Precisely the part of the graphical pipeline in which more processing is done is during texturing, so that is one of the first explanations why GPUs require a high width of walk.
As for the data used during the pre-rasterization process, the calculation of the geometry of the scene, these are low enough not to result in a huge amount of memory used and influence the type of memory used as VRAM.
The Overdraw problem

The algorithm used to render a scene is rasterization, also called the z-buffer algorithm or the painter’s algorithm, which in its base form has the following structure: for each primitive in the scene, for each pixel covered by the primitive, marks the pixel closest to the camera and stores it in the z-buffer.
This causes that, if several objects are in the same position of the X and Y coordinate axis with respect to the camera, but in a different position with respect to the Z axis, then the pixels of each of them are drawn in the final image buffer and finish to be processed multiple times. This effect is called overdraw or overdrawn due to the fact that the GPU paints and repaints pixels in the same position.
Now, some of you are rightly thinking the following: If the depth buffer is generated before texturing, how is it that pixels are not discarded at that stage? Actually, there are techniques for that, but at that stage we are completely unaware of the color of each pixel and if an object is semi-transparent or not, so GPUs cannot discard all the pixels in a scene where there is only one object. transparent, since then its representation would be incorrect.
Middle Sort vs Last Sort
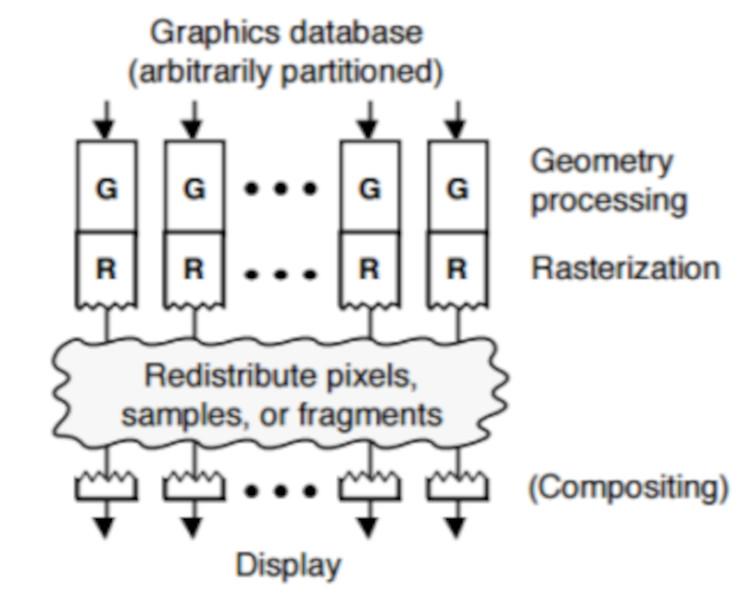
The process of checking the pixels one by one to see if they are visible or not requires extra circuitry in the GPUs and that the rendering process is affected by it. The idea with a GPU is that of gross power without taking into account other elements, if there is any optimization to be done this is left to the hardware part, that is why the verification that a pixel has to go to the image buffer or it is not done at the end of the process, which is called Last Sort.
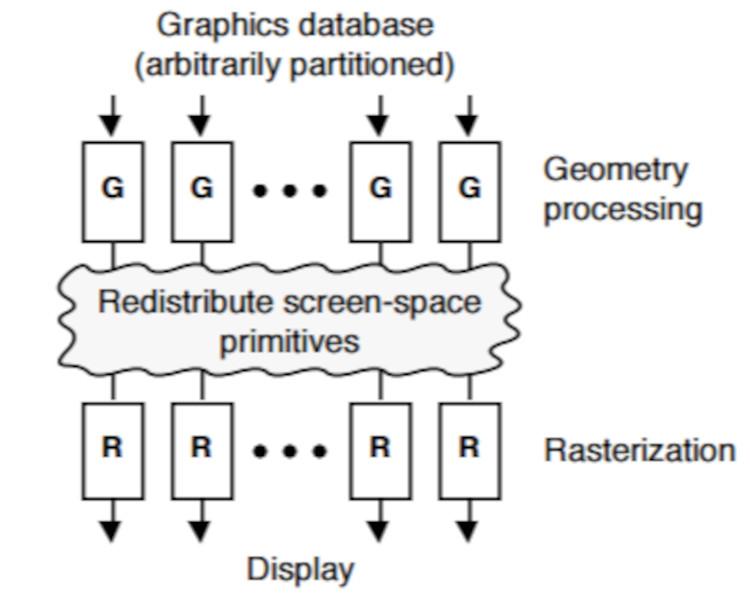
Whereas, if the objects are sorted during the raster phase, using the Depth Buffer as a reference, then we call it Middle Sort because it occurs right in the middle of the graphical pipeline.
The second technique avoids overdraw, but as we have seen before there are problems when a scene has transparency. And what do current GPUs use? Well, both, since developers can choose which type to choose. The difference is that in Middle Sort there is no overdraw.
Bandwidth and VRAM: the overdraw
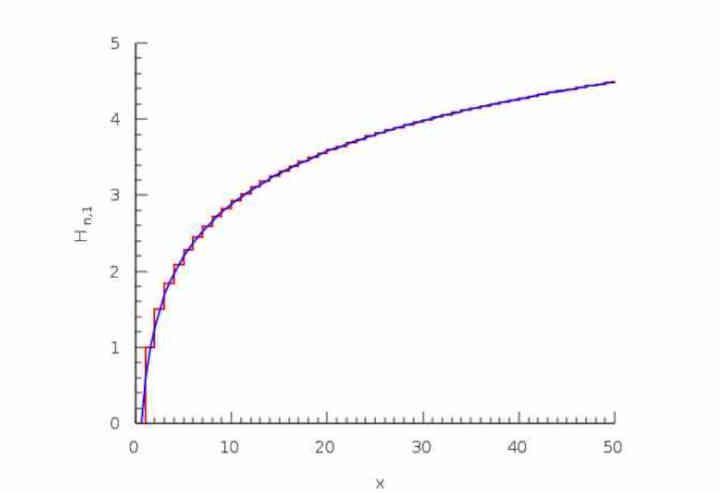
The logic behind the overdraw is that the first pixel in a position (x, y) will be drawn in the image buffer yes or yes, the second one under the same position will have a 50% chance of having a greater or 50 Z value % chance of having a smaller one and therefore it will be written in the final buffer, the third has 1/3 of possibilities of existing, the fourth of 1/4.
This is called the harmonic series:
H (n) = 1 + 1/2 + 1/3 + 1/4… 1 / n
Why is this important? Well, due to the fact that even though the pixels that are discarded by the overdraw are really large, it reaches the point where a massive overdraw does not result in a huge number of pixels being drawn in the Color Buffer, since if the value z of that already textured pixel is greater than one found in the image buffer, so it is discarded and does not count in the bandwidth of the Color Buffer, even if it has been previously textured.
VRAM Bandwidth: Compression Mechanisms

In recent years the so-called Delta Color Compression or DCC have appeared, we recommend you look for the article we did on this subject. These techniques are based on compressing the size of the Color Buffer in such a way that it occupies much less and to do it what they do is tell the GPU that each pixel has a value of + n bits, where n is the difference between the current image and the previous one.
Another element is texture compression, which is different from DCC and this is used when generating a Color Buffer that we later want to recover to perform post-processing effects. The problem is that the image that uses texture compression is not understood by the unit that reads the final image and sends it to the screen.
Bandwidth and VRAM: Tile Rendering
In Tile Rendering both the Color Buffer and the Depth Buffer are processed internally on the chip, so those bandwidths are not taken into account. Hence, the GPUs that use this technique, such as those used in smartphones, do not require so much bandwidth and can work with memories of much lower bandwidth.
However, the Tile Renderers have a series of setbacks that make them have less raw power than the GPUS that do not use that way of rendering the scene.
Conclusions

Guessing the bandwidth used by each of the games is difficult, so there are tools such as NVIDIA‘s NSight and Microsoft‘s PIX, which not only measure the level of computational load in each of the parts of the GPU but also the throughput of the bandwidth, this allows developers to optimize in the use of VRAM.
The reason for this is that in the case of overdrawn scenes they cannot predict what the load of each of the pixels in a frame will be. For both hardware architects and software engineers it is best not to complicate life and put the fastest VRAM within the stipulated costs.
What is taken into account is the ratio between the bandwidth and the theoretical fill rate, which consists of dividing the bandwidth by the precision per pixel and comparing it with the theoretical fill rate of the GPU, but It is a factor that is less and less taken into account, especially since the GPUs no longer draw the already textured pixels directly into the VRAM but instead write them to the L2 cache of the GPU itself, thus reducing the impact on the VRAM.