
Any multicore architecture requires internal communication to communicate its different components with each other, however there are different types of interconnection topologies with different results for the internal communication of a CPU, a GPU or any other type of processor composed of several elements that need communicate with each other. What is the most commonly used type of topology?
Most processors today are extremely complex pieces made up of others, but in general all of them tend to have a central communication that is responsible for communicating the different elements that are part of the processor. However, there are different topologies in what we know as Northbridge and that is why we are going to list them and explain the most used in the different processors of our system, whether they are CPUs, APUs and even GPUs.
Shared bus infrastructure
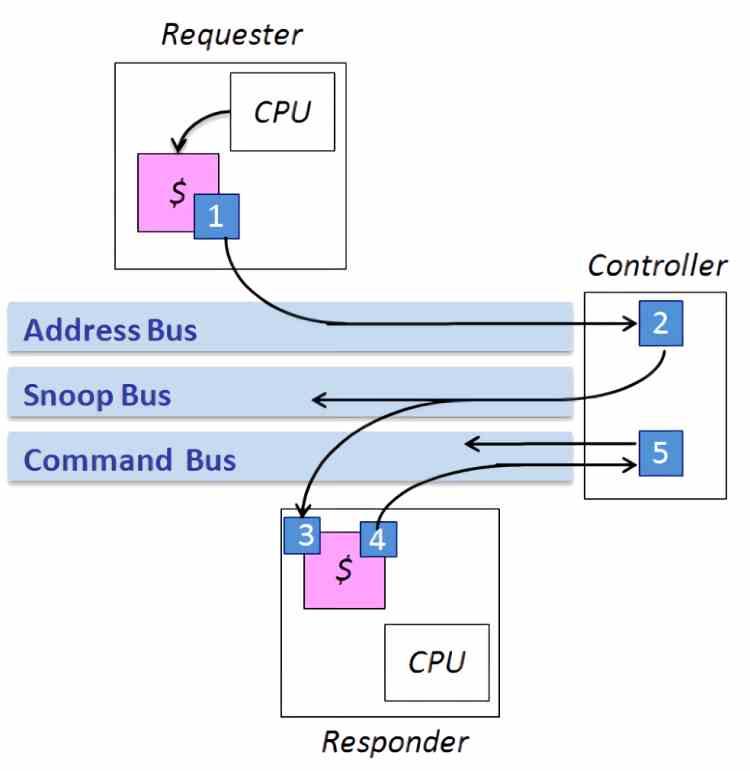
The first type of topology that we have to consider is the so-called shared bus infrastructure or Shared Bus Fabric. These types of interfaces have a great speed and are used to communicate the different cores with each other and their caches. But it is also responsible for giving access to the outside to the CPU cores and therefore allowing access to memory and peripherals in a consistent way.
This means that the shared bus infrastructure has to have a series of mechanisms integrated in order to ensure coherence with the memory of the components within the processor. Here we have to clarify that we can find that a CPU and a GPU do not share the same addressing, so they will not be coherent with each other, but internally of the same processor it is normal that all the components are coherent or the maximum possible consistency. Although in APUs this is not usually achieved.

The shared bus infrastructure is therefore what we know as the Northbridge or north bridge, which have different types of topologies. This has to be understood as the way in which the different components are intercommunicated with each other, which will affect latency, cost of implementation, energy consumption and other factors.
Many times there are designs that do not have the best type of infrastructure to get the most out of their processors, but it has been chosen for reasons of associated cost, either because of the number of transistors necessary for its implementation and because of the physical costs such as the energy transmitted to communicate or emitted in the form of temperature.
The Crossbar Switch
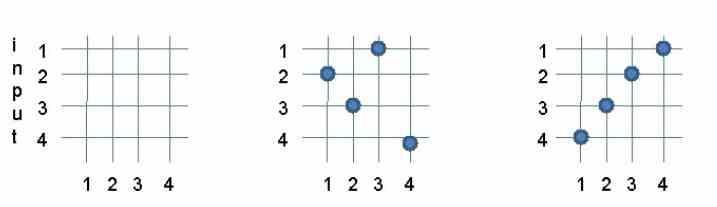
A Crossbar Switch is the easiest type of topology to visualize. It is a type of mesh interface where each of the components has a direct connection with the rest of the system’s components. For example, if we have a processor with 4 components inside then we will have a Crossbar Switch of 4 x 4 units.
It is the most widely used type of topology and the greatest advantage is that it allows several communications to be carried out in parallel. Its biggest disadvantage? As we have more and more components connected to the Crossbar Switch, more and more size takes this inside the chip, making the central communication infrastructure grow more and more and the moment is reached when the movement of data ends up taking up more space than the data processing.
That is why the Crossbar Switches despite being the most used are not the only type of topology that we can find within a processor, their enormous complexity makes designers take other types of topologies.
Ring topology
The second type of topology is the rings, to understand how they work we have to make a simile with reality, such as radial highways in some cities. Each exit to a neighborhood or district from the radial highway in our processor is an input and output of data to a component within the processor and the vehicles that circulate are requests for data from and to those same components.
In the ring infrastructure, data circulates around the central ring. Therefore, the communication is not direct and the data only leaves the ring when it passes in front of the determined component. An automated system in the ring extracts the data and instruction packets to said component and circulates the rest. The problem with this type of topology is the speed at which the data travels. Typically, for each cycle of the shared bus infrastructure a subsection of the ring is advanced, so the number of subsections of a ring will correspond to the number of components, which makes it difficult to scale to create designs with more or more. fewer components.
Rings are the simplest type of infrastructure to implement on a processor and also the cheapest to implement at the cost level. But in an infrastructure of this type, each node is connected only to its 2 closest neighbors, one per address. This means that communication with more distant components will have higher latency.
Toroidal topology

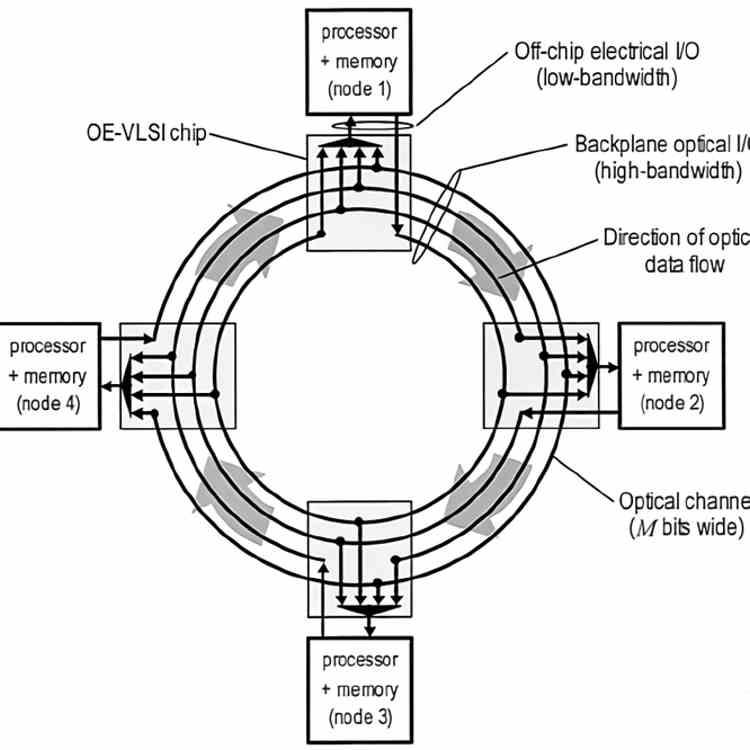
Toroidal infrastructures are widely used in the world of supercomputing to connect in the fastest and most efficient way the different processors distributed in the different blades around the infrastructure in the most efficient way possible. Although where they have achieved their greatest popularity in recent years has been in the face of processors designed to accelerate artificial intelligence algorithms. Either at the level of communicating several ALUs with each other or different processors.
At first glance it may be reminiscent of a Crossbar Switch, but in the case of a 2-dimensional torus a component can communicate with 4 other components at the same time instead of 2 compared to a ring and if we speak of a 3-dimensional torus then we have that each component will have a communication with other 6 components. To visualize it, we must bear in mind that each dimension of a toroidal topology allows communication with a different component, one for each dimension. So in a simplified way, a ring is a one-dimensional toroid infrastructure.
Tree topology
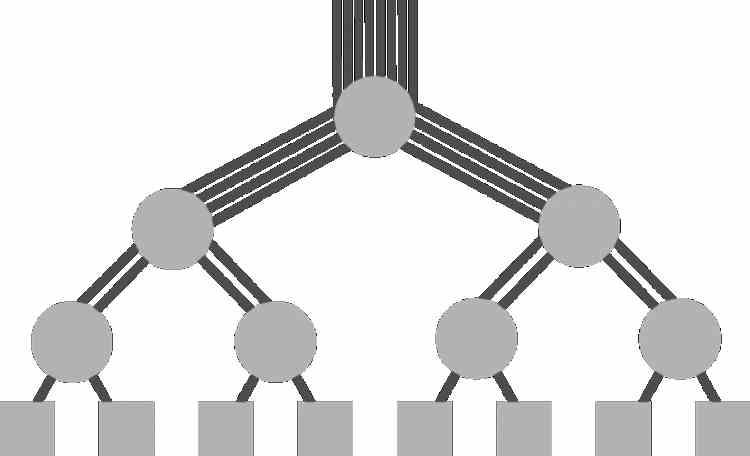
The tree topology communicates the components in an organized hierarchical infrastructure, in such a way that to access a component it is necessary to communicate with the one that is earlier in the hierarchy. It is a concept very similar to that of toroidal topology and like this it has a very low latency when the components are close together. Therefore, the latency will depend on the number of levels that one component is with respect to another within the hierarchy.
The organization of a tree topology does not have to have a fixed number of nodes in each of its levels and can be totally irregular in that aspect from one level of the hierarchy to another. So in that aspect it has a greater versatility than the toroidal topology that we have discussed in the previous section.