Computers are no longer like their beginnings running a process and thanks, they now have the ability to run an immense number of programs in parallel. Some of them we see in our games, others are invisible, but there they are, being executed by the CPU. Is there a relationship between the processes of the software and threads of execution with those of the hardware?
We often hear or read the thread of execution concept when hearing about new CPUs, but also in the software world. That is why we have decided to explain the differences between what are the processes or threads of execution in the software and their significant equivalents in the hardware.
Processes in the software

In its simplest definition, a program is nothing more than a succession of instructions ordered sequentially in memory, which are processed by the CPU, but the reality is more complex. Anyone with a little knowledge of programming will know that this definition corresponds to the different processes that are executed in a program, where each process intercommunicates with the others and is found in a part of memory.
Today we have a large number of programs running on our computer and therefore a much larger number of processes, which fight to access the CPU resources to be executed. With so many processes at the same time, a conductor is needed to be in charge of managing them. This work is in the hands of the operating system, which, as if it were a traffic control system in a big city, is in charge of managing and planning the different processes that are going to be executed.
However, software processes are often referred to as threads of execution, and it is not a bad definition if we take into account their nature, but the definition does not coincide in both worlds, so they are often confused and this leads to several misunderstandings about how multithreaded hardware and software works. That is why in this article we have decided to call the threads of the software processes to differentiate them from those of the hardware.
The concept of a bubble or stop in a CPU
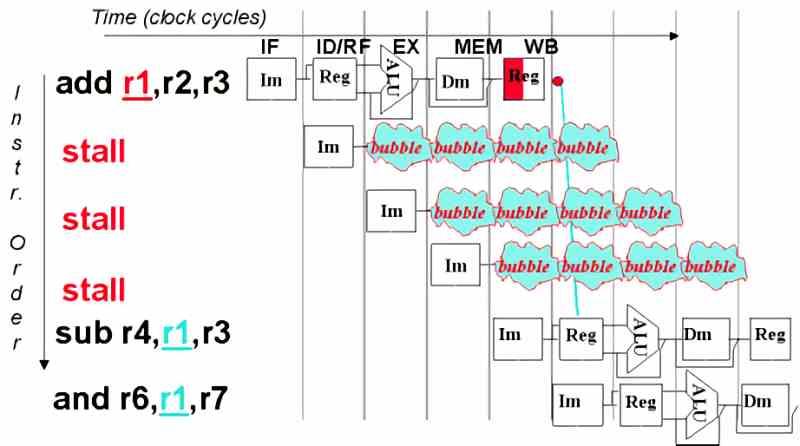
A bubble or stop in the execution occurs when a process that executes the CPU for some reason cannot continue, but has not been terminated in the operating system either. For this reason, operating systems have the ability to suspend a thread of execution when the CPU cannot continue and assign the work to another kernel that is available.
In the hardware world appeared in the early 2000s what we call multithreading with the Hyperthreading of the Pentium IVs. The trick was to duplicate the CPU’s control unit that is responsible for capturing and decoding. With this it was achieved that the operating system will end up seeing the CPU as if they were two different CPUs and assigned the task to the second control unit. This does not double the power, but when the CPU itself got stuck in one thread of execution, it passed to the other immediately to take advantage of the downtime that occurred and get more performance from the processors.
Multithreading at the hardware level by duplicating the control unit, which is the most complex part of a modern CPU, completely increases power consumption. Hence, the CPUs for smartphones and tablets do not have hardware multithreading in their CPUs.
Performance depends on operating system
Although CPUs can execute two threads of execution per core, it is the operating system that is responsible for managing the different processes. And today the number of processes running on an operating system is greater than the number of cores a CPU can run simultaneously.
Therefore, since the operating system is in charge of managing the different processes, this is also the one in charge of assigning them. This is a very easy task if we are talking about a homogeneous system in which each core has the same power. But, in a totally heterogeneous system with cores of different powers, this is a complication for the operating system. The reason for this is that it needs a way to measure what the computational weight of each process is, and this is not measured only by what it occupies in memory, but by the complexity of the instructions and algorithms.
The leap to hybrid cores has already occurred in the world of ARM processors where operating systems such as iOS and Android have had to adapt to the use of cores of different performances working simultaneously. At the same time the control unit of future designs has had to be further complicated in the x86. The objective? That each process in the software is executed in the appropriate thread of the hardware and that the CPU itself has more independence in the execution of the processes.
How is the execution of processes on the GPUs?

The GPUs in their shader units also execute programs, but their programs are not sequential, rather each execution thread is made up of an instruction and its data, which has three different conditions:
- The data is found next to the instruction and can be executed directly.
- The instruction finds the memory address of the data and has to wait for the data to arrive from memory to the registers of the shader unit.
- The data depends on the execution of a previous thread of execution.
But a GPU does not run an operating system that can handle the different threads. The solution? All GPUs use an algorithm in the scheduler of each shader unit, the equivalent of the control unit. This algorithm is called Round-Robin and consists of giving an execution time in clock cycles to each execution / instruction thread. If this has not been solved in that time, it goes to the queue and the next instruction in the list is executed.
The shader programs are not compiled in the code, due to the fact that there are substantial differences in the internal ISA of each GPU, the controller is in charge of compiling and packaging the different execution threads, but the program code is in charge of managing them. . So it is a different paradigm than how the CPU executes the different processes.