One of the confusions created by the marketing of graphics card manufacturers is when it comes to talking about the number of cores that a GPU has, we anticipate that they lie to exaggerate the numbers. But what do we understand by core in a GPU, can we compare them with those of a CPU and what differences are there?
When you go to buy the latest model graphics card, the first thing you see is that they tell you about huge amounts of cores or processors, but what happens if we tell you that it is a wrong nomenclature?

The trap that manufacturers make is to call simple ALUs or execution units under the name of cores, for example NVIDIA calls its ALUs CUDA cores that operate in 32-bit floating point, but if we are strict we cannot call them cores or processors anymore. They do not meet the basic requirements to be considered in such a way.
So what is a core or processor in a GPU?
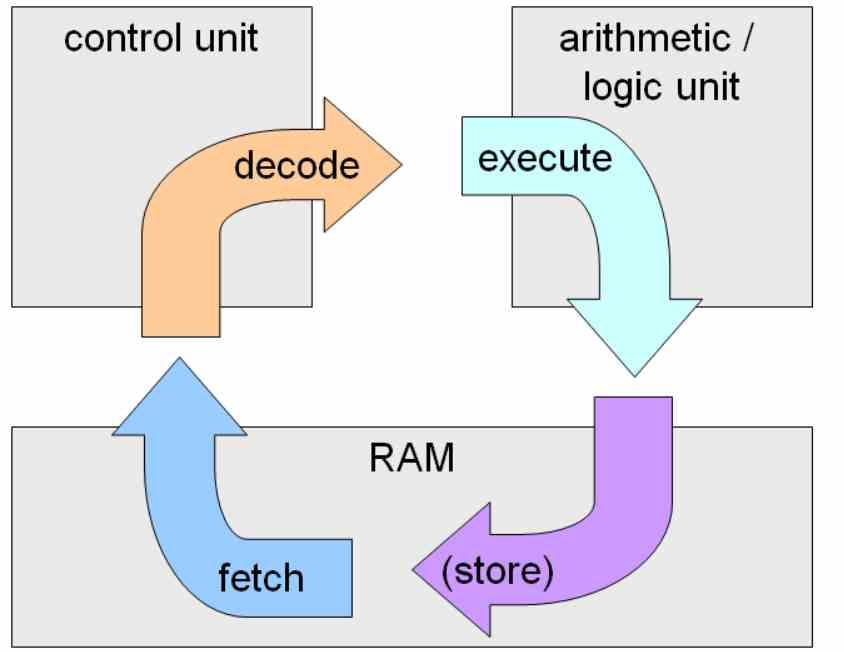
A core or processor is any integrated circuit or part of it that together can execute a complete instruction cycle, this is the capture of instructions from a memory, the decoding and the execution of them.
An ALU is only an execution unit so it needs a control unit to be a complete core. And what do we consider a complete core? Well, what NVIDIA calls SM, Intel calls Sub-Slice and AMD Compute Unit.
The reason for this is that it is in these units where the entire instruction cycle takes place, and not in the ALUs or execution units, which are only in charge of a part of the instruction cycle.
GPUs do not “run” programs

Keep in mind that GPUs do not execute programs as we know them, these being a sequence of instructions. The exception is shader programs that run on what are actually the GPU cores.
What shader programs do is manipulate data sets or graphical primitives in the different stages. But at the hardware functionality level, these are presented in the form of kernels.
Kernels, not to be confused with those of operating systems, are self-contained data + instruction sets, which are also called threads in the context of a GPU.
How is a GPU core different from a CPU core?

The main difference is that CPUs are primarily designed for instruction-level parallelism , while GPUs are specialized for thread-level parallelism.
The instruction level parallelism is intended to reduce the instruction time of a program by executing several instructions of the same simultaneously. The kernels based on thread level parallelism take several programs at the same time and execute them in parallel ,
Contemporary CPUs combine ILP and TLP in their architectures, while GPUs remain purely TLP without any ILP in order to simplify the control unit and be able to place as many cores as possible.
Running on a GPU versus running on a CPU
Most of the time, when a thread reaches the GPU core ALUs it contains the instruction and the data directly, but there are times when the data has to be searched in the caches and in memory, to avoid delays in the executing the GPU kernel scheduler what it does is what is called a Round-Robin and passes that thread to run afterwards.
In a CPU this cannot be done, the reason for this is that the threads are very complex sets of instructions and with a high dependency between them, while in a GPU there is no problem for this, since the execution threads are extremely small as they are self-contained in “kernels” many times of a single instruction duration.
In reality, what GPUs do is gather a set of kernels in what is called a wave, assigning each wave to an ALU of the GPU, these are executed in cascade and in order. Each kernel has a limit of threads or kernels, which will keep it busy for a while until it needs a new list, in this way avoiding that the huge number of cores is constantly making requests to memory.