There is no storage medium that is completely immune to data corruption , but as technology advances, there are more and more mechanisms to mitigate its adverse effects. Now, with the NVMe 1.4 specification introduced in SSDs that make use of this protocol, a new feature called RRL or Read Recovery Level has been enabled, a mechanism that helps the SSD to recover from errors due to corrupted data automatically. And in this article we are going to explain what it is exactly and how it works.
There are many factors that can influence the fact that corrupted data occurs on a storage device, and one of the advantages of SSDs is that protection mechanisms and even resolution mechanisms can be integrated into the controller itself, as is the case with the NVMe 1.4 protocol that has recently been released. Today we are going to take an in-depth look at one of these mechanisms, perhaps the most important to avoid data corruption.

Read Recovery Level (RRL) on NVMe 1.4 SSDs
The NVMe 1.4 specification (be careful because this feature we are talking about is not integrated in previous versions) presents several new functions to help handle unrecoverable read errors and corrupted data, especially in RAID configurations and similar scenarios where the host system you can recover problem data much more quickly simply by removing it from another location. Let’s explain it.
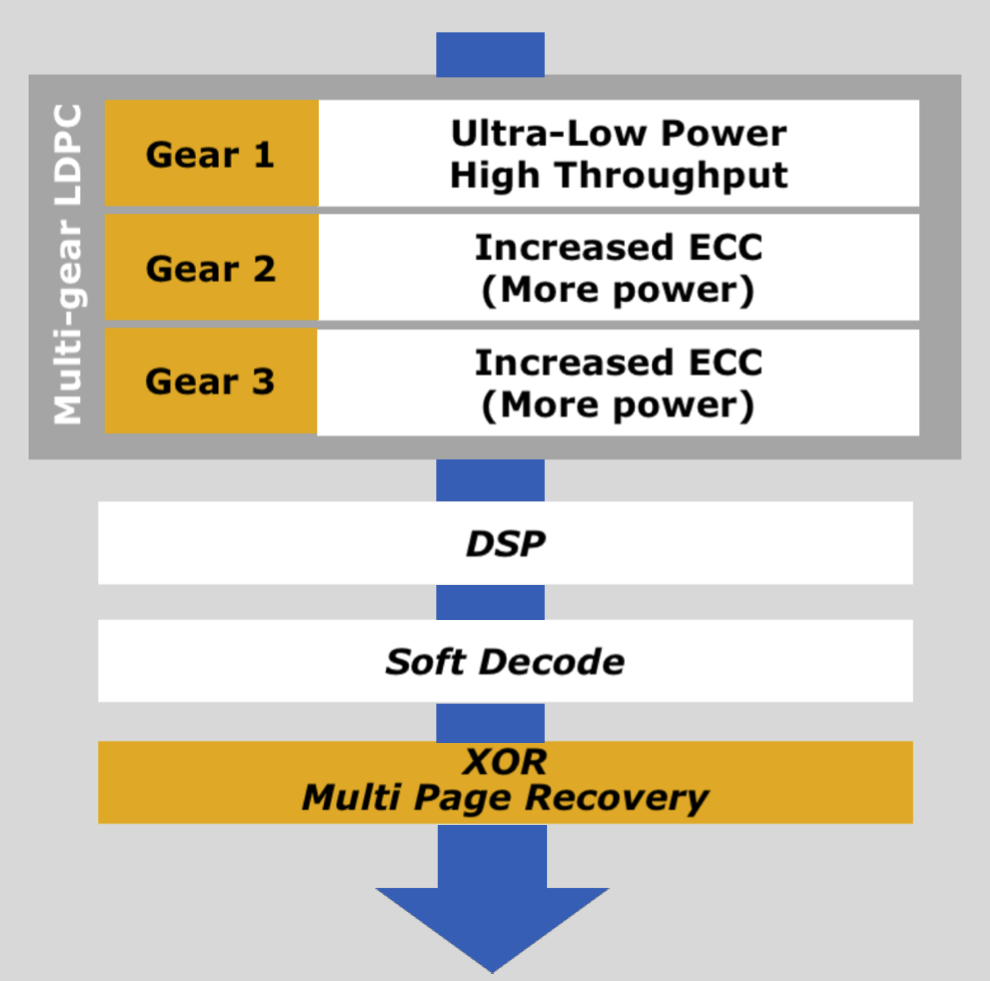
The Read Recovery Level feature allows the host system (the controller, essentially) to configure how hard the SSD should attempt to recover corrupted data when problems occur. SSDs usually have several layers of error correction (ECC) as you can see in the image above, and each of the layers is more robust but at the same time slower (penalizes performance) and consumes more power, generating more heat. at the same time.
In a RAID 1 or similar scenario, the host system will generally prefer to get rid of an error quickly by simply trying to read the same data that has been corrupted on an SSD in another of the drives that make up the RAID configuration, replacing the corrupted data to continue operating normally. . Until now the SSD had to try to correct the problem by itself with the ECC mechanisms, slowing down the performance of the unit and considerably increasing the consumption of energy and generated heat; furthermore, this method does not guarantee the recovery of corrupted data, although it does work well when simply reading errors occur.

NVMe already supports Time Limited Error Recovery (TLER), but this only allows the host system to put a limit on error handling time in 100ms increments. Read Recovery Levels allow drives to provide up to 16 different levels of error handling strategies, but drives that implement this feature are only required to actually implement a minimum of two levels to meet the standard. NVMe 1.4 standard. This feature is set at the assembly level by NVM.
Unrecoverable read errors on SSDs
To proactively prevent unrecoverable read errors, the NVMe 1.4 specification also adds the Verify and Get LBA Status commands. The Verify command is simple: it does everything a normal read command does except return data to the host system, but with the exception that if a read command returns an error, a verify command will return the same error. If a read command is successful, so will the Verify command.
This makes it possible to perform low-level cleaning of stored data without being bogged down by host interface bandwidth. Some SSDs will react to a fixable ECC error by moving or rewriting the degraded or corrupted data, and a verify command will trigger the same behavior. In general, this reduces the need for debugging and checksum verification at the filesystem level, which results not in a performance improvement, but does prevent performance from being degraded. Each Verify command is labeled with a bit that indicates whether the SSD should quickly dismiss the error or attempt to recover the data, similar but overriding the Read Recovery Level setting.

For its part, the Get LBA Status function allows the unit to provide the host with a list of blocks that are likely to end up resulting in unrecoverable read errors if a read or verify command is attempted on them; In other words, the controller is able to compile a list of data that are candidates for failure and / or problems beforehand, before the errors occur.
The SSD may already have detected ECC errors during background autoscan, or in severe cases it can report which LBAs are affected by a channel failure or full NAND die. The Get LBA Status function can also be used to request the SSD to perform a scan of the selected data ranges before returning the list of potentially unrecoverable blocks.
When the host system discovers that there is corrupted or missing data, either through the Get LBA Status function, by issuing normal read commands, or by using the Verify function, it can write this data back to the same LBA using a copy obtained from somewhere else (such as in a RAID system or in a backup) and then continue to use those logical blocks as normal, while the SSD will remove any physical blocks that are bad if necessary.
As you can see, these are just some of the mechanisms that SSDs have to preserve the integrity of the data when problems occur in the unit, and at each new revision of the standards (which as in this case come from the NVMe 1.4 standard ), the mechanisms for detecting, protecting and solving problems continue to be improved. However, we must remember that despite everything irreversible errors can occur that end up damaging the unit, no one is free from that (for now).