Is it true that NVIDIA has doubled the power of the shaders in its new graphics of the RTX 30 series ? How? We explain it to you in this article and dispel some myths in the process.
One of the most surprising developments during the NVIDIA RTX 30 architecture presentation is NVIDIA’s claim that the number of Shaders has doubled. To what extent is this NVIDIA saying true? Is it a general rule or does it only happen at specific times?

What is really a core on a GPU?
A very widespread myth by the marketing of both AMD and NVIDIA is the confusion of the units in charge of executing the instructions with what is a whole nucleus that would be the one that takes the entire instruction cycle to complete.
So NVIDIA has historically called the ALUs in charge of executing low precision 32-bit floating point math operations as CUDA cores, which leads to confusion since when we talk about CPUs, a complete core is one capable of performing the three general stages of the instruction loop, which is also called the Fetch-Decode-Execute loop.
In NVIDIA GPUs the complete unit that handles a complete instruction cycle is the SM. This unit is common among all NVIDIA GPUs over the years and has undergone evolutions over time and various additions. One of the latest evolutions has been to go to the 64 FP32 ALUs for SM that we saw in the NVIDIA Turing, both in the 20 × 0 and in the 16 × 0.
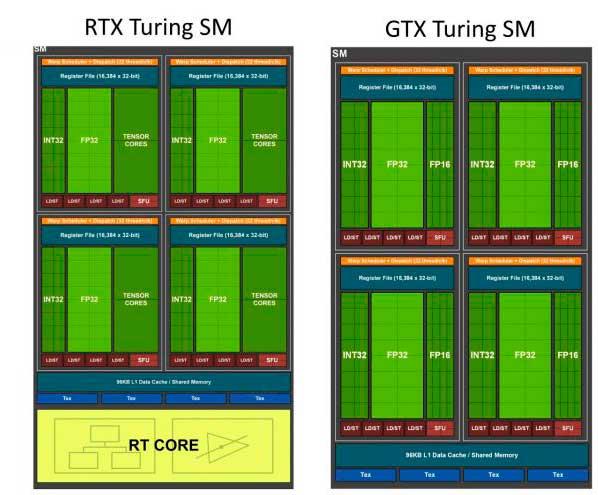
Meanwhile, in the SMs in the RTX 30 × 0 range, the FP32 units have doubled, reaching a total of 128, but this does not mean that the power has been doubled.
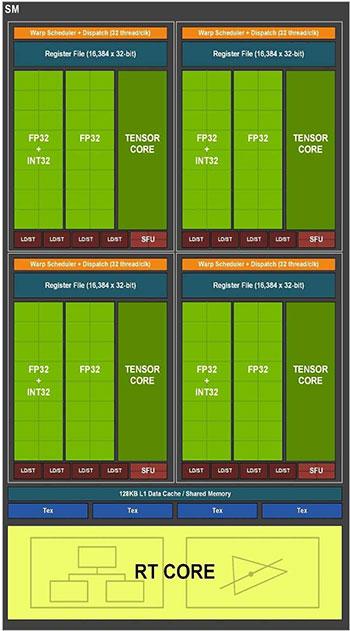
Has the power of the shaders on the RTX 30 been doubled?
Obviously the reality is that not all the instructions of the different Shader programs will be executed in floating point units, some of them will do so in:
- The integer ALUs (Int32)
- The data fetching instructions will use the Load / Store units (L / S in the diagrams).
- Some mathematical instructions are executed in SFUs (Special Function Units).
- Obviously we cannot forget the Tensor Cores that are also in the SM.
Each type of instruction has its own metric. However, double the number of FP32 operations per clock cycle has its trap, since in order to operate the ALUs they must have access to the registers and the problem is that the second set of FP32 ALUs is switched with the 16 Int32 ALUs. By switched we mean that if one type of ALUs is used to execute one type of instruction then the ALUs of the other type are inactive and vice versa. Therefore, the advantage of the RTX 30 × 0 compared to its predecessors, which is to have twice the number of units in FP32, will only be visible in programs that make massive use of this type of operation.
How do the threads run on the SM?
To understand the reason, we must take into account that the SM has 4 equal parts. Each one of them symmetrical; on the one hand, a unit that distributes 32 wires among the SMs, 16 ALUs for calculating with integers (Int32) and 32 ALUs for calculating in floating point (FP32). All this having as a conductor the so-called “Warp Scheduler” or “Warps” Planner.
What is a Warp? Well, a set of grouped threads of execution. What the scheduler does is, as its name suggests, schedule which threads of execution and in what order they will be executed in the ALUs of the SM (Int32, FP32 …), and sends each thread of execution through the Dispatch unit to registers at a rate of 32 threads per clock cycle.
On the other hand, the ALUs that are also connected to the registers take the execution threads that are stored in the registers and execute the execution threads. Since only 32 registers can be used in ALUs per clock cycle, this means that there are units that will not be used and this leads to the second set of ALUs in FP32 and Int32 being switched due to lack of registers in those that operate within each subgroup of the SM, since without a support memory from which to read the data and write the data, an ALU cannot operate, and hence if the second set of comma ALUs are used floating cannot be used for integers and vice versa.
To make a simile and simplify it to the maximum, imagine that we have a mixed group with 32 girls and 16 boys who have to take turns teaching them but we only have 32 desks. Imagine that each instruction is a class and that each student is given a different class (thread). On the other hand, it has been decided that 16 of the girls have their desks secured, so the other 32 will have to share the remaining 16 desks (records).
The conclusion is that the supposed double power of the RTX 30 range only occurs in certain circumstances and therefore not 100% of the time.