NVIDIA presented its Ampere architecture two weeks ago and as such, the stir caused has been enormous, mainly due to the supposed increase in performance so great that they are going to have their graphics cards. But one of the key characteristics of Ampere GPUs has been largely overlooked and where much of the specific performance improvements are focused, something that AMD already has in development and that will mean a paradigm shift, which they have called Multi- Instance . Is Ampere therefore a premature response to Lisa Su’s technology?
The whole argument is going to focus on a key feature such as GPU Multi-Instance or also known as MIG. This technology is very representative in terms of what its own name indicates and will bring a new era for both programmers and software.

NVIDIA GPU Multi-Instance, the revolution that AMD is also preparing

We will not go into depth to explain MIG, but to understand what the launch of Ampere represents and what AMD will bring, we will explain it briefly. GPU Multi-Instance represents the largest release and allocation of resources seen on a graphics card. What this technology achieves is to divide the available resources for each cluster into up to 7 different instances that can work independently and simultaneously to maximize performance.
This is logically not reproducible by any AMD GPU today and is a very clear advantage for NVIDIA, or maybe not? Can it be a checkmate from NVIDIA to AMD? In principle not, since apparently and according to what has been seen in various patents, those of Lisa Su are already working hard on a similar system that at the moment is a very advanced concept.
This new system would have an advantage over the one implemented by NVIDIA and is nothing more than a non-limitation of resources per instance. Is this really better and more productive?
Higher performance that will require extensive control
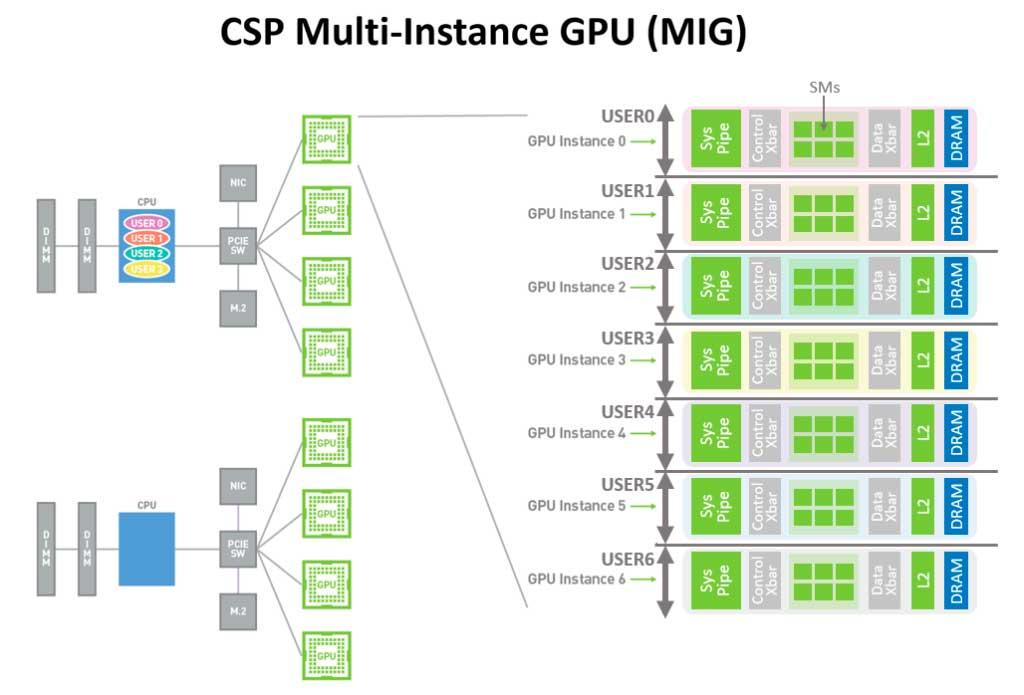
AMD’s proposal for what the patents reflect offers greater granularity in terms of the allocation of available resources. This means that in principle there is no physical limit to the resources, if a container needs to work with a Shader or with a specific engine it could do it dynamically with no limit per instance as NVIDIA does.
That is, the AMD option would allow full use of the GPU functions, all in theory with maximum efficiency and power utilization. Another advantage that AMD seems to have over NVIDIA is the fact of admitting queues from different operating systems, where to differentiate the tasks an ID would be assigned to each container, whether physical or virtual, thus supporting multiple queues.
It is unclear whether this will eventually come to RDNA 2 as such or be part of the CDNA series for HPC, but it seems pretty clear that Ampere has been an early bet on multi-instance adoption.
Of course, once both technologies with their corresponding cards are on the market, it will be necessary to assess with on-site data whether we are indeed talking about higher performance in AMD or better optimization in NVIDIA, since as the history of GPUs has shown, the Much encompasses little squeeze and in this sense NVIDIA has always managed to do more with less.