DLSS is one of the spearheads of NVIDIA versus AMD, the games that support it can achieve higher frame rates at output resolutions where without the use of this technique it would not be possible. This fact has been what has made the GPUs of the NVIDIA RTX ranges the current leaders in the GPU market, but the NVIDIA DLSS has a trap and we are going to tell you what it is.
If we have to talk about the two spearheads of NVIDIA for its GeForce RTX it is clear that they are Ray Tracing and DLSS, the first is no longer an advantage due to the implementation in AMD’s RDNA 2, but the second is still a differential element that gives it a great advantage, but not everything is what it seems at first glance.

DLSS on RTX depends on Tensor Cores
The first thing we have to take into account is how the different algorithms, commonly called DLSS, take advantage of the console hardware and nothing better than to do an analysis of the operation of the GPU while it is rendering a frame with the DLSS active and without it.
The two screenshots that you have above these images correspond to the use of the NVIDIA NSight tool, which measures the use of each of the parts of the GPU over time. To interpret the graphs we have to take into account that the vertical axis corresponds to the level of use of that part of the GPU and the horizontal axis the time in which the frame is rendered.
As you can see, the difference between both screenshots of the NSight is that in one of them you can see the level of use of each part of the GPU when using the DLSS and in the other not. What is the difference? If we do not look closely we will see that in the one corresponding to the use of the DLSS the graph corresponding to the Tensor Cores is flat except at the end of the graph, which is when these units are activated.
DLSS is nothing more than a super-resolution algorithm, which takes an image at a given input resolution and outputs a higher resolution version of the same image in the process. That is why the Tensor Cores when applied are activated last, since they require the GPU to render the image first.
DLSS Operation on NVIDIA RTX

DLSS takes up to 3 milliseconds of the time to render a frame, regardless of the frame rate at which the game is running. If for example we want to apply the DLSS in games at a frequency of 60 Hz, then the GPU will have to resolve each frame in:
(1000 ms / 60 Hz) -3 ms.
In other words, in 13.6 ms, in return we are going to obtain a higher frame rate in the output resolution than we would get if we were to natively render the output resolution to the GPU.

Suppose we have a scene that we want to render at 4K. For this we have an indeterminate GeForce RTX that at said resolution reaches 25 frames per second, so it renders each of these at 40 ms, we know that the same GPU can reach a frame rate of 5o, 20 ms at 1080p. Our hypothetical GeForce RTX takes about 2.5 ms to scale from 1080p to 4K, so if we activate DLSS to get a 4K image from one at 1080p then each frame with DLSS will take 22.5 ms. With this we have been able to render the scene at 44 frames per second, which is greater than the 25 frames that would be obtained rendering at native resolution.
On the other hand, if the GPU is going to take more than 3 milliseconds to make the resolution jump then the DLSS will not be activated, since it is the time limit set by NVIDIA in its RTX GPUs for them to apply the DLSS algorithms. This makes lower-end GPUs limited in the resolution at which they can run DLSS.
DLSS benefits from high speed Tensor Cores

The Tensor Cores are essential for the execution of the DLSS , without them it would not be possible to perform at the speed that runs in the NVIDIA RTX, since the algorithm used to perform the increase in resolution is what we call a convolutional neural network, in which Composition, we are not going to go into this article, just say that they use a large number of matrix multiplications and tensor units are ideal for calculating with numerical matrices, since they are the type of unit that executes them faster.
In the case of a movie today, decoders end up generating the initial image in the image buffer several times faster than the rate at which it is displayed on the screen, so there is more time to scale and therefore you end up requiring much less computing power. In a video game, on the other hand, we do not have it stored on a support as will be the following image, but it has to be generated by the GPU, this cuts the time that the scaler has to work.
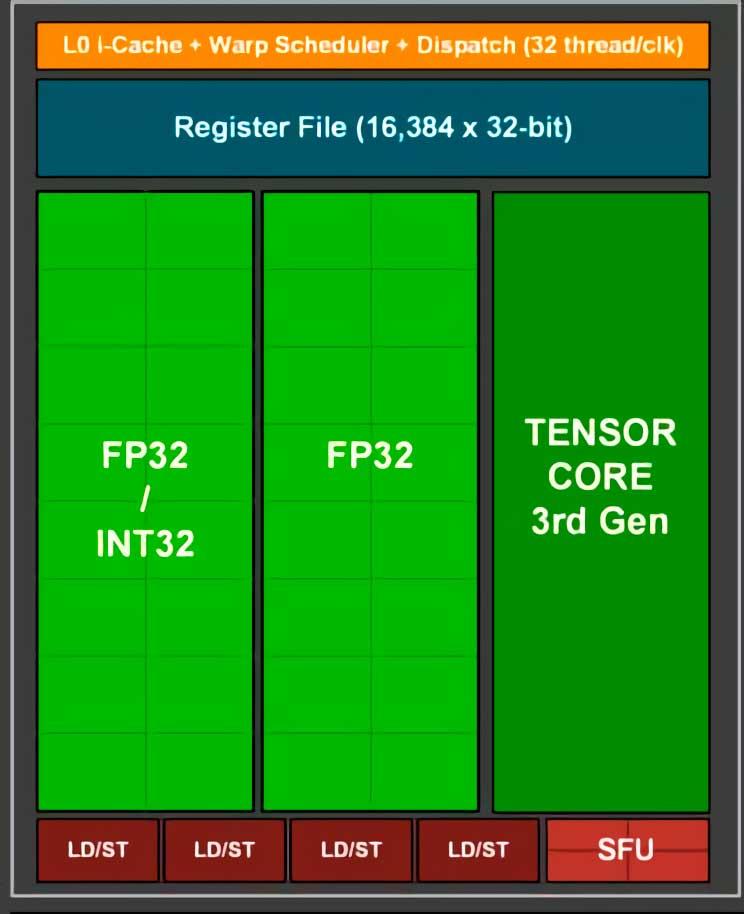
Each of these Tensor Cores is found inside each SM unit and depending on the graphics card that we are using, its calculation capacity will vary, by varying the number of SMs per GPU, and therefore will generate the scaled image in more less time. Because DLSS kicks in at the end of rendering , a high speed is required to apply DLSS , which is why it is different from other super-resolution algorithms such as those used to scale film and images.
Not all NVIDIA RTXs perform the same on DLSS
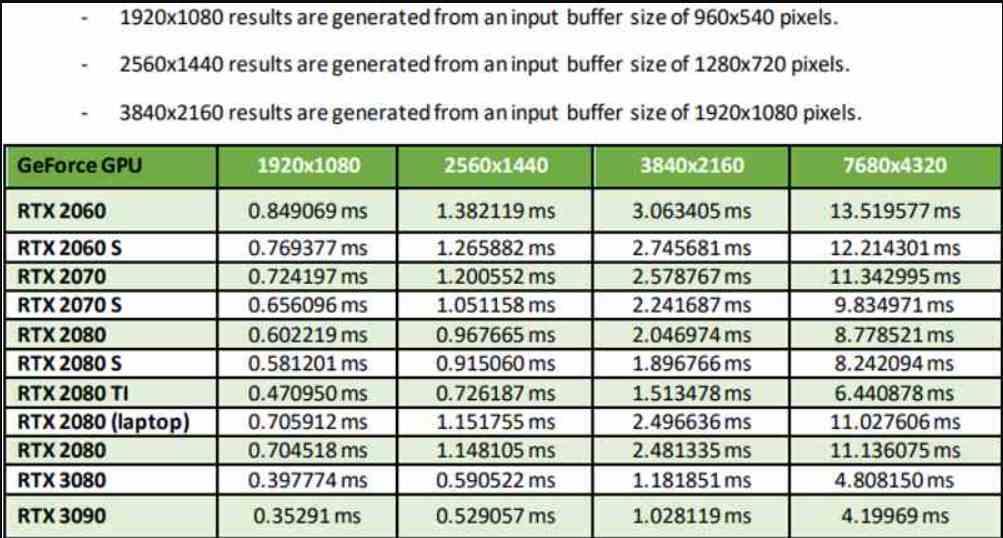
This table that you see is taken from NVIDIA’s own documentation, where the input resolution in all cases is 4 times less than the output resolution, so we are in Performance Mode. It should be clarified that there are two additional modes, the Quality Mode gives better image quality, but requires an input resolution of half the pixels, while the Ultra Performance Mode does a scaling of 9 times, but has the worst image quality. of all.
As you can see in the table, the performance not only varies according to the GPU, but also if we take into account the GPU that we are using. Which should come as no surprise after what we’ve explained earlier. The fact that in the Performance Mode an RTX 3090 ends up being able to scale from 1080p to 4K in less than 1 ms is the least impressive, however this has a counterpart that derives from a logical conclusion and that is that the DLSS in the graphics cards more modest will always work worse.
The cause behind this is clear, a GPU with less power will not only need more time to render the frame, but even to apply the DLSS. Is the solution the Ultra Performance mode that increases the number of pixels by 9 times? No, since DLSS requires that the output image has sufficient input resolution, since the more pixels there are on the screen then there will be more information and the scaling will be more accurate.
Geometry, image quality and DLSS
![]()
The GPUs are designed so that in the Pixel / Fragment Shader stage, in which the pixels of each fragment are colored and the textures are applied, they do so with 2 × 2 pixel fragments. Most GPUs, when they have rasterized a triangle, convert it into a block of pixels that is then subdivided into 2 × 2 pixel blocks, where each block is sent to a Compute Unit.
The consequences on DLSS? The raster unit tends to discard all 2 × 2 chunks out of the box as being too small, sometimes corresponding to details that are far away. This means that details that at a native resolution would be seen without problems are not seen in the resolution obtained through DLSS due to the fact that they were not in the image to be scaled.
Since DLSS requires an image with as much information as possible as an input reference, it is not an algorithm designed to generate images at very high resolution from very low ones, since detail is lost in the process.
And what about AMD, can it emulate the DLSS?

Rumors about the super resolution in the FidelityFX have been around the network for months but from AMD they have not yet given us any real example about the operation of its counterpart to the DLSS. What’s making AMD’s life so difficult? Well, the fact that the Tensor Cores are crucial for the DLSS and in the AMD RX 600 there are no equivalent units, but rather that SIMD over register or SWAR is used in the ALUs of the Compute Units to obtain a higher performance in FP16 formats of less precision. , but a SIMD drive is not a systolic array or tensioner drive.
From the outset, we are talking about a 4 times differential in favor of NVIDIA, this means that when generating a similar solution it starts from a considerable speed disadvantage, optimizations for the calculation of matrices apart. We are not discussing whether NVIDIA is better than AMD in this, but the fact that AMD when designing its RDNA 2 did not give importance to the tensor units.
Is it due to disability? Well no, since paradoxically AMD has added them to CDNA under the name of Matrix Core. At the moment it is early to talk about RDNA 3, but let’s hope that AMD does not make the same mistake again of not including one of these units. It makes no sense to do without them when the cost per Compute Unit or SM is only 1mm 2 .
So we hope that when AMD adds its algorithm due to the lack of Tensor units it will not reach the precision and neither the speed of NVIDIA’s, but that AMD will present a simpler solution such as a Performance Mode that doubles the pixels on the screen.