One of the key concepts to understand the architecture and performance of current Intel and AMD CPUs is the concept of microoperations, as well as units such as their cache. In this article we will tell you in an accessible way what they are and why today’s processors base all their operation on them to achieve the maximum possible performance.
A CPU today can execute a large number of different instructions, and it does so at frequencies that are up to 5,000 times higher than that of early personal computers. We tend to think and completely wrongly that the greater amount of MHz or GHz is due to the new ones of manufacture. The reality is very different, and this is where microoperations come in, which are key to achieving the enormous computing power of today’s microprocessors.

What are microoperations?
One of the similes with reality that are usually used to explain what a program is is the simile with a cooking recipe. In which we can see assigned in a verb a series of actions that we have to carry out. For example, I can put in a recipe that you fry a piece of meat in the pan, but for you it will turn out to have to look for the pan, do the same with the oil, put the latter in the pan, wait for it to be hot and put the piece of meat in it. As you can see, we have converted something that in principle is defined by a single verb into a series of actions.
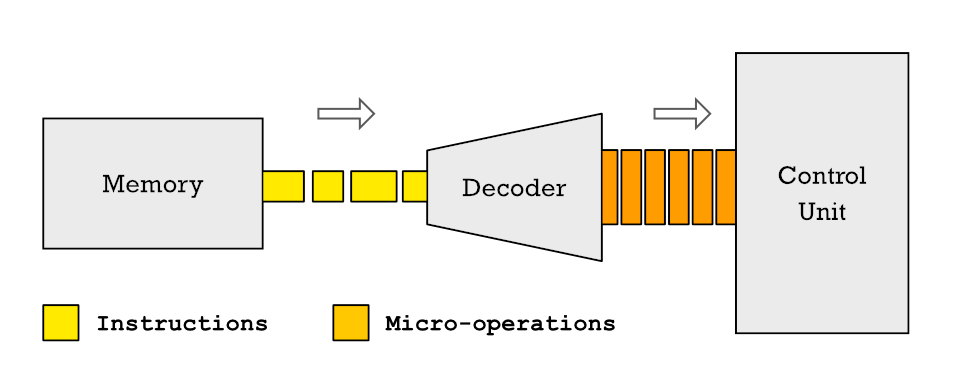
Well, the instructions of a CPU can be broken down into smaller ones that we call microoperations. And why not microinstructions? Well, due to the fact that an instruction, just by segmenting it into several cycles for its execution, takes several clock cycles to resolve. A microoperation, on the other hand, takes a single clock cycle.
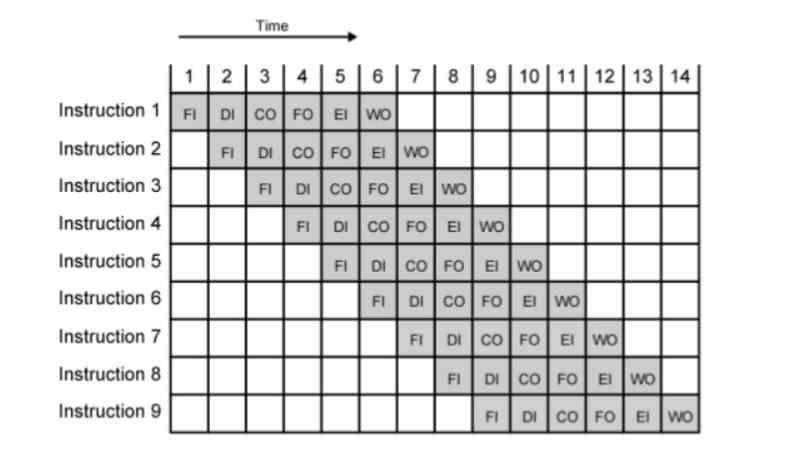
One way to get the most MHz or GHz is pipelining, where each instruction is executed in several stages that each last one clock cycle. Since frequency is the inverse of time, in order to get more frequency we have to shorten time. The problem is that the point is reached where an instruction can no longer be decomposed, the number of stages in the pipeline becomes short and thus the clock speed that can be achieved is low.
Actually, these were born with the appearance of the out-of-order execution of the Intel P6 architecture and its derivative CPUs such as the Pentium II and III. The reason for this is that the segmentation of the P5 or Pentium only allowed them to reach a little over 200 MHz. With the microoperations, by lengthening the number of stages of each instruction even more, they surpassed the GHz barrier with the Pentium 3 and were able to have clock speeds 16 times higher with the Pentium 4. Since then they have been used in all CPUs with out-of-order execution, regardless of brand and register and instruction set.
Your CPUs are neither x86, nor RISC-V, nor ARM
In current CPUs when instructions arrive at the CPU control unit to be decoded and assigned to the control unit they are first broken down into several different micro-operations. This means that each instruction that the processor executes is made up of a series of basic micro operations and the set of them in an ordered flow is called microcode.

The decomposition of instructions into microoperations and the transformation of programs stored in RAM into microcode is found today in all processors. So when your phone’s ISA ARM CPU or your PC’s x86 CPU is executing programs, its execution units are not resolving instructions with those sets of registers and instructions.
This process not only has the advantages that we have explained in the previous section, but we can also find instructions that, even within the same architecture and under the same set of registers and instructions, are broken down differently and the programs are fully compatible. The idea is often to reduce the number of clock cycles required, but most of the time it is to avoid the contention that occurs when there are multiple requests to the same resource within the processor.
What is the micro-op cache?
The other important element to achieve the maximum possible performance is the micro-operations cache, which is later than the micro-operations and therefore closer in time. Its origin can be found in the trace cache that Intel implemented in the Pentium 4. It is an extension of the first level cache for instructions that stores the correlation between the different instructions and the microoperations in which they have been previously disassembled by the control unit.

However, the x86 ISA has always had a problem with respect to the RISC type, while the latter have a fixed instruction length in the code, in the case of the x86 each of them can measure between 1 and 15 bytes. We have to keep in mind that each instruction is fetched and decoded in several micro-operations. To do this, even today, a highly complex control unit is needed that can consume up to a third of its energy power without the necessary optimizations.
The micro-operation cache is thus an evolution of the trace cache, but it is not part of the instruction cache, it is a hardware-independent entity. In a microoperation cache, the size of each of them is fixed in terms of the number of bytes, allowing for example a CPU with ISA x86 to operate as close as possible to a RISC type and reduce the complexity of the control unit and with it consumption. The difference from the Pentium 4 plot cache is that the current micro-op cache stores all the micro-ops belonging to an instruction in a single line.
How does it work?
What the microoperations cache does is avoid the work of decoding the instructions, so when the decoder has just carried out said task, what it does is store the result of its work in said cache. In this way, when it is necessary to decode the following instruction, what is done is to search if the microoperations that form it are in said cache. The motivation for doing this is none other than the fact that it takes less time to consult said cache than not to decompose a complex instruction.
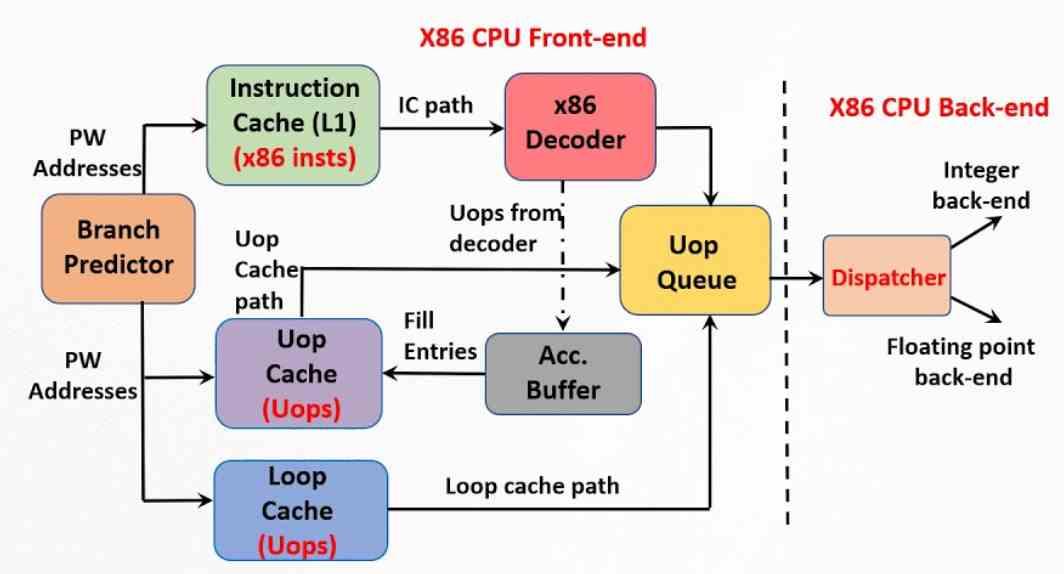
However, it works like a cache and its content is shifted over time as new instructions arrive. When there is a new instruction in the first-level instruction cache, the micro-operation cache is searched if it is already decoded. If not, then proceed as usual.
The most common instructions once decomposed are usually part of the micro-operations cache. What causes fewer to be discarded, however, is that those whose use is sporadic will be more often, in order to leave room for new instructions. Ideally, the size of the microoperation cache should be large enough to store all of them, but it should be small enough so that the search in it does not end up affecting the performance of the CPU.