When buying a CPU or a GPU we find technical specifications such as clock speed, the number of floating point operations, memory bandwidth, etc. But, one of the ways to measure performance and design a processor has to do with the latency of the instructions. We explain what it is and why it is so important to get faster CPUs.
The performance of one processor over another is measured by the time it takes to solve the same program. This can be achieved in many different ways and there are different ways to increase performance and thereby reduce the time it takes to run. One of them is to cut the latency of the instructions that are executed. But what exactly does it consist of?

What do we mean by instruction latency?
Latency is the time it takes a processor to carry out an instruction and this is variable from where the data is located, since the further it is, the more time it has to travel for these to be placed in the corresponding registers. It is for this reason and because the memory does not scale at the same speed as the processors, mechanisms such as the cache had to be created and even integrate the memory controller within the processor to reduce the latency of the instructions.
However, this is not usually taken into account when selling a CPU and even a GPU, other performance measures are often used to speak that one architecture is superior to another. But the latency of the instructions is not usually used when promoting a processor when it is one more way of understanding performance.
Clock cycles per instruction and latency

The first measure of performance is cycles per instruction, since there are instructions complex enough to have to be executed in several different instruction cycles. Many times when designing new processors, architects often make changes in the way of solving an instruction with respect to previous processors with the same ISA, whether we are talking about CPUs, GPUs or any other type of processor.
What is never changed is the form of the instruction, but what is done is to cut the number of clock cycles that are necessary to scramble it. For example, we can have an instruction in charge of calculating the average between two numbers that takes 4 clock cycles in a processor with the same ISA and that improves by 20% to a previous version of the same instruction that takes 5 cycles.
The idea is none other than to reduce the time it takes for a part of the instructions in order to reduce the time it takes to execute a program. In this way, it is achieved with small accelerations in the instructions that the overall performance increases.
Cache and instruction latency

The cache memory stores a copy of the RAM memory to which the instructions that are executed at that moment point, this allows the processor to access the memory without having to access the RAM and since the cache is closer to the units of the CPU that the memory ends up being able to execute the instruction in less time, since the capture of instructions requires less time.
The fact that we are talking about different cache levels does not mean that all first level, second level and even third level caches have the same distance and therefore latency, but rather that they vary from one architecture to another. For example, in the current Intel Core from Intel, the latency with the caches is lower than in their competitors’ equivalents, AMD‘s AMD Zen.
In order to improve an architecture from one version to another, one of the changes that are usually raised is the decrease in latency with respect to the cache. Especially when porting the same architecture from one node to another, thanks to the reduction of the processor size and the distance between the units and the cache.
The chiplet and latency dilemma

The idea of chiplets is none other than to use several chips instead of just one for the same function, this therefore increases the communication distance between the different parts and therefore the latency. This results in a loss of performance compared to the monolithic version of the processor.
In the case of the AMD Ryzen, which are the best known case, one way to cut the difference between the versions based on chiplets and those that are monolithic processors is to cut the last-level cache in seconds. The reason? If they had the same amount of cache then the versions via chiplet only due to the distance from the memory controller would have lower latency in the instructions and with it a higher performance.
Instruction latency is the key to 3DIC

The chips integrated in three dimensions are another of the key points, especially those that stack memory on a processor. The reason for this is that they put the memory so close to the processor that that alone increases performance. The trade-off of this is thermal choking between the memory and the processor, which forces the clock speed to drop, and in some designs it may happen that placing the processor and memory separately allows for higher clock speeds than in a 3DIC design.
If the memory is close enough to the processor it can create a curious effect, in which it takes less time to access the data in the embedded memory than to go through the different cache levels of the architecture one by one. Which completely changes the way a processor is designed, since cache memory is a way to reduce latency when the data to be processed is too far apart.
Distance and consumption are related
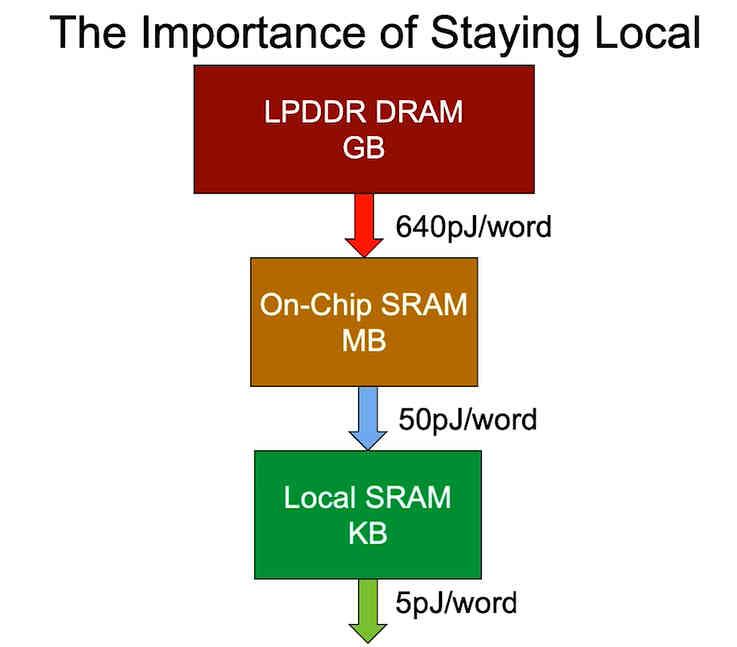
The last point is that of energy consumption, which depends on where the data is located. That is why when designing a more optimized version in terms of processor consumption, what is sought is to cut the distance in which the data is located, since the energy consumption of a processor increases with the distance in the let the data be found and not just latency, unfortunately we cannot fit the huge amounts of data we need to run a program within the space of a chip.
In a world where energy consumption due to climate change has become one of the most important points and portability and low consumption are a selling point and therefore of value in many products, the fact of looking for ways to bring memory closer to the processor and thus decrease the latency of the instructions, something that becomes extremely important in order to increase the performance per watt.