Il concetto SWAR sembrerà strano a molti, ma cosa succede se ti diciamo che le unità SIMD delle tue CPU, GPU nei tuoi sistemi sono per lo più di tipo SWAR? Questi tipi di unità differiscono dalle unità SIMD convenzionali e hanno la loro origine nelle estensioni multimediali della fine degli anni '90. Cosa sono e a cosa servono oggi?
Le prestazioni di un processore possono essere misurate in due modi, da un lato, quanto velocemente esegue le istruzioni in serie e che quindi non possono essere parallelizzate, poiché influenzano solo un dato di unità. D'altra parte, quelli che funzionano con più dati e possono essere parallelizzati. Il modo tradizionale di farlo su CPU e GPU? Le unità SIMD, di cui esiste un sottotipo molto utilizzato nelle CPU e nelle GPU, le unità SWAR.

ALU e loro complessità
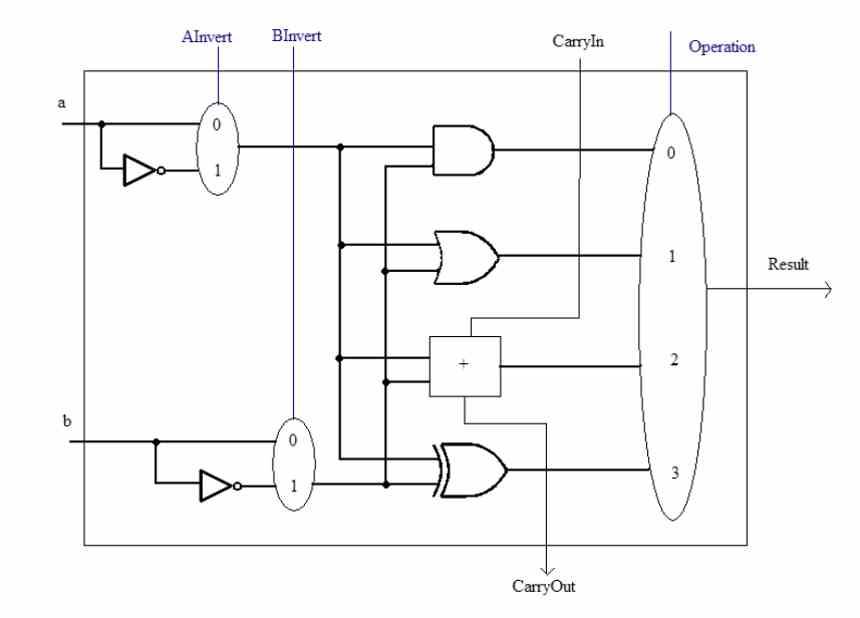
Prima di parlare del concetto SWAR, dobbiamo tenere presente che le ALU sono le unità di a CPU responsabili dell'esecuzione di calcoli aritmetici e logici con i diversi numeri. Questi possono crescere in complessità in due modi, uno dalla complessità dell'istruzione che devono eseguire. La circuiteria interna di una ALU che può eseguire, ad esempio, il calcolo di una radice quadrata non è la stessa di quella di una semplice somma.
L'altro è la precisione con cui lavorano, cioè il numero di bit che manipolano simultaneamente ogni volta. Una ALU può sempre gestire dati uguali o inferiori al numero di bit per cui è progettata. Ad esempio, non possiamo fare in modo che un numero a 32 bit venga calcolato da un ALU a 16 bit, ma possiamo fare il contrario.
Ma cosa succede quando abbiamo diversi dati di minore precisione? Normalmente funzioneranno alla stessa velocità della massima precisione, ma c'è un modo per velocizzarli, e questo è il SIMD over-register. Che è anche un modo per salvare i transistor in un processore.
Qual è il concetto SWAR?
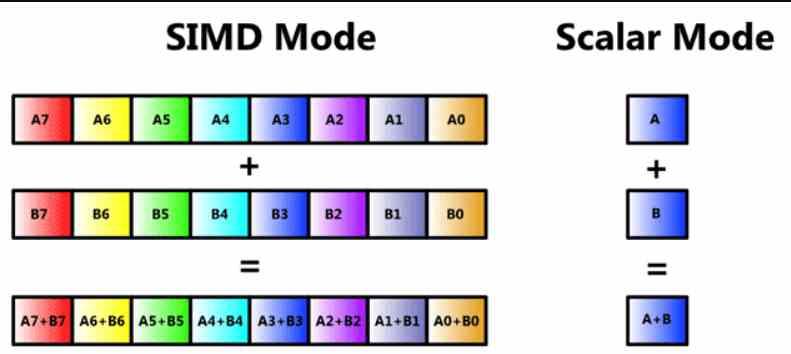
Ormai molti lettori sapranno che si tratta di un'unità SIMD, ma la esamineremo in modo che nessuno perda il filo di questo articolo dall'inizio. Un'unità SIMD è un tipo di ALU in cui più dati vengono manipolati attraverso una singola istruzione contemporaneamente, e quindi ci sono più ALU che condividono la parte di captazione di ciò che è l'istruzione stessa e la sua decodifica, ma dove in ognuna una diversa viene trattata un'informazione.
Le unità SIMD sono solitamente composte da più ALU, ma ci sono casi in cui le ALU sono suddivise in più semplici, così come il registro di accumulazione dove memorizzano temporaneamente i loro dati per calcolarle. Questo si chiama SIMD su un registro o dal suo acronimo in inglese SWAR, che significa SIMD all'interno di un registro o SIMD su un registro.
Questo tipo di unità SIMD è molto utilizzato e consente a un ALU di precisione a n bit di eseguire la stessa istruzione ma utilizzando i dati con minore precisione. Di solito con metà o un quarto di precisione. Ad esempio, possiamo fare in modo che una ALU a 64 bit agisca come due ALU a 32 bit eseguendo detta istruzione in parallelo, o quattro a 16 bit.
Approfondire il concetto SWAR?
Questo concetto ha già diversi decenni, ma la prima volta che è apparso su PC è stato alla fine degli anni '90 con la comparsa di unità SIMD nei diversi tipi di processore esistenti. I veterani del posto ricorderanno concetti come MMX, AMD 3D Now!, SSE e simili erano unità SIMD costruite secondo il concetto SWAR.
Supponiamo di voler costruire un'unità SIMD a 128 bit
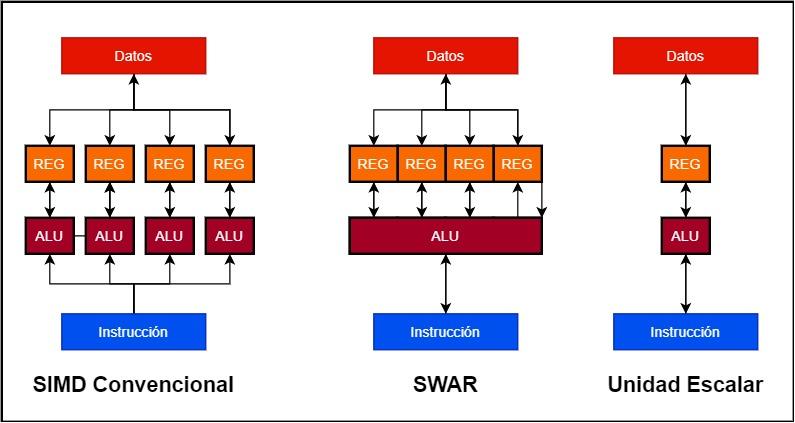
- Nelle unità SIMD convenzionali abbiamo diverse ALU che lavorano in parallelo e ognuna di esse ha il proprio registro dati o accumulatore. Pertanto, un'unità SIMD a 128 bit può essere composta da 4 ALU a 32 bit e 4 registri a 32 bit.
- Invece un'unità SWAR è una singola ALU che può lavorare con un'altissima precisione così come il suo registro accumulatore. Questo ci consente di costruire l'unità SIMD utilizzando un singolo ALU a 128 bit con supporto SWAR.
Il vantaggio che l'implementazione di un'unità di tipo SWAR ha rispetto a una scalare è semplice da capire, se una ALU non contiene il meccanismo SWAR che le consente di funzionare come un'unità SIMD con dati di minore precisione, allora le eseguirà contemporaneamente velocità. rispetto ai dati di massima precisione. Cosa significa questo? Un'unità a 32 bit senza supporto SWAR, nel caso in cui debba eseguire la stessa istruzione su dati a 16 bit, lo farà alla stessa velocità di un'unità a 32 bit. D'altra parte, se l'ALU supporta SWAR, sarà in grado di eseguire due istruzioni a 16 bit nello stesso ciclo, nel caso in cui vengano entrambe successivamente.
SWAR come patch per AI

Gli algoritmi di intelligenza artificiale hanno una particolarità, tendono a lavorare con dati di precisione molto bassa e oggi la maggior parte delle ALU opera con una precisione a 32 bit. Ciò significa aggiungere ALU di precisione a 16, 8 e persino 4 bit a un processore per accelerare quegli algoritmi. Il che per complicare il processore, ma gli ingegneri non sono caduti in quell'errore e hanno iniziato a tirare il SIMD sul registro in un modo particolare, specialmente sulle GPU.
È possibile combinare un ALU SIMD convenzionale con un design SWAR? Ebbene sì, ed è quello che, ad esempio, fa AMD nelle sue GPU dove ciascuna delle ALU a 32 bit che compongono le unità SIMD delle sue GPU RDNA supporta SIMD over register e quindi può essere suddivisa in due a 16 bit, 4 di 8 bit o 8 di 4 bit.
Nel caso di NVIDIA, hanno dato l'onere di accelerare gli algoritmi per AI ai Tensor Core, si tratta di array sistolici composti da ALU a virgola mobile a 16 bit interconnesse tra loro in una matrice a tre assi, da cui il nome dell'unità. Tensore. Non sono unità SIMD, ma ciascuna delle loro ALU supporta SIMD su registro essendo in grado di eseguire il doppio delle operazioni con precisione a 8 bit e quattro volte con precisione a 4 bit. In ogni caso, le unità Tensor sono importanti perché sono progettate per accelerare le operazioni da matrice a matrice a una velocità molto più elevata rispetto a un'unità SIMD.