
If you have read the complete specifications of some of the latest Intel CPUs, you will have seen some mysterious acronyms appear: GNA. In reality it is a small processor or rather a coprocessor that is responsible for accelerating certain Deep Learning algorithms and that, therefore, are highly related to the implementation of artificial intelligence. We explain what this coprocessor consists of and what its functionality is.
Processors dedicated to speeding up certain everyday tasks, using models developed via artificial intelligence, have been appearing in recent years in all configurations and sizes and it is not surprising that Intel has not wanted to be left behind.
What is the Intel GNA?
The Intel GNA is the coprocessor that some Intel CPUs have integrated and that serves to accelerate the execution of some inference algorithms. That said, many of you will already know that therefore we are facing a neural type processor, which in this case was first introduced in the Intel Ice Lake, and its acronym means Gaussian Neural Accelerator ( GNA ), and being integrated into the own processor works at very low consumption.
It is intended to be used for tasks such as real-time audio transcription or photo noise removal, which are typical for AI, but do not require a high-powered accelerator.
It was recently improved at Tiger Lake, where version 2.0 of the GNA was implemented, which is intended to also be used for canceling ambient noise and reducing noise in photographs. With this we can deduce that the GNA is designed for collaborative business environments, especially those based on teleworking in which the transcription of text and that communication is carried out without noise of any kind is very important.
How does it work?
The Intel GNA is not an execution unit of the CPU so we are dealing with a processor within another and it serves to accelerate certain tasks for its guest. This means that it has to be explicitly invoked in the code through an API, in this case the dedicated Intel API.
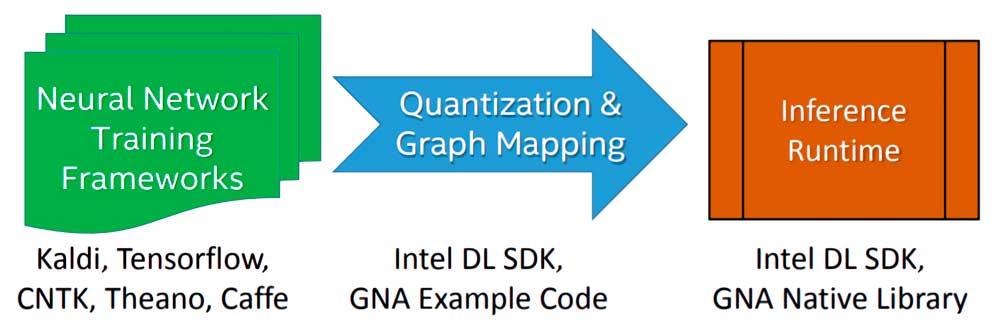
The implementation of a Deep Learning algorithm or model to be executed by the Intel GNA during the inference stage is done in three stages:
- We start by training the algorithm using a floating point neural network with a free choice framework.
- The model resulting from the training is imported using the Intel Deep Learning SDK Deployment Tool that allows importing any model generated by the most famous and used Deep Learning frameworks.
- It links with the Intel Deep Learning SDK Inference Engine or the native GNA libraries, of which there are two: one for Intel Quark and the other for Intel Atom and Intel Core.
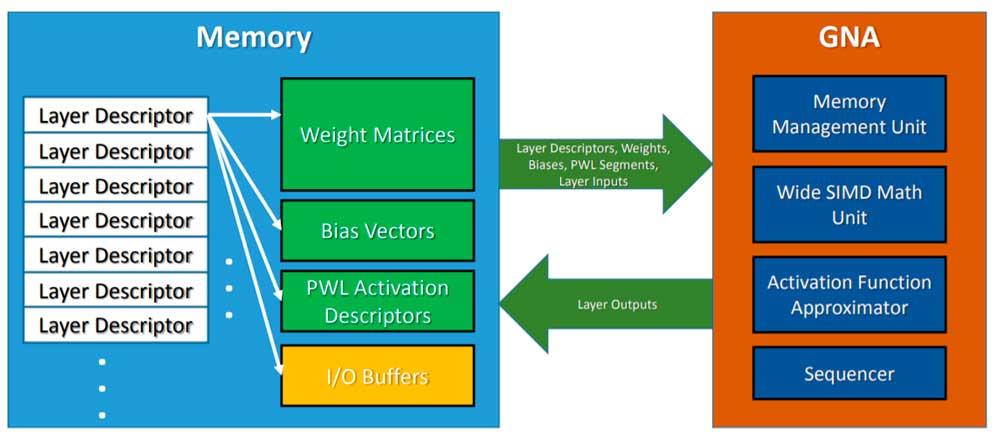
In order to invoke the GNA, what the CPU does is leave the inference model in memory, and the GNA is invoked to adopt said algorithm and execute it in parallel to the work of the processor of which it is the host. It must also be taken into account that it is a low-power unit, so we cannot expect the same results as using a high-performance neural network or an FPGA configured as such, but it is good enough for tasks simple from day to day.
Intel GNA outside of Intel CPUs

Although the GNA is itself a processor that is integrated as part of x86 CPUs, it can be deployed outside the CPU if desired, the most famous case being the Intel Speech Enabling Dev Kit , which is used especially for inference of voice commands for applications for Amazon Alexa devices.