HBM memory is known for its use as VRAM memory in some graphics cards, but one of the points where we will start to look at is HBM memory in server CPUs. The reason? The objective is not to mount the HBM memory as RAM memory, but LLC or last level cache, in order to speed up certain jobs.
The HBM memory that until now has been related to GPUs for the HPC market will start to be adopted by CPUs. What does it bring and why will HBM memory be used for CPUs and what are Intel and AMD‘s reasons for its implementation?
A review of the HBM memory

HBM memory is a type of memory that is made up of several stacked memory chips, which communicate with your controller vertically using pathways through silicon. Such a three-dimensional integrated circuit is packaged together and sold as an HBM chip.
In order to communicate with the processor, the HBM chip does not use a serial interface, but rather communicates with the substrate or interposer below to transmit the data. This allows you to communicate with the processor making use of a greater number of pins and lower the clock speed for each of them. The result? A RAM memory that compared to another type consumes much less when transmitting data.
HBM memory has not been used in the domestic market because it is expensive, its composition of several memory chips makes it very difficult to manufacture for large-scale products, but it is ideal for smaller-scale products. Be it GPUs for high-performance computing and even CPUs for servers where the HBM is going to make its appearance,
Memory channels are a part of the key
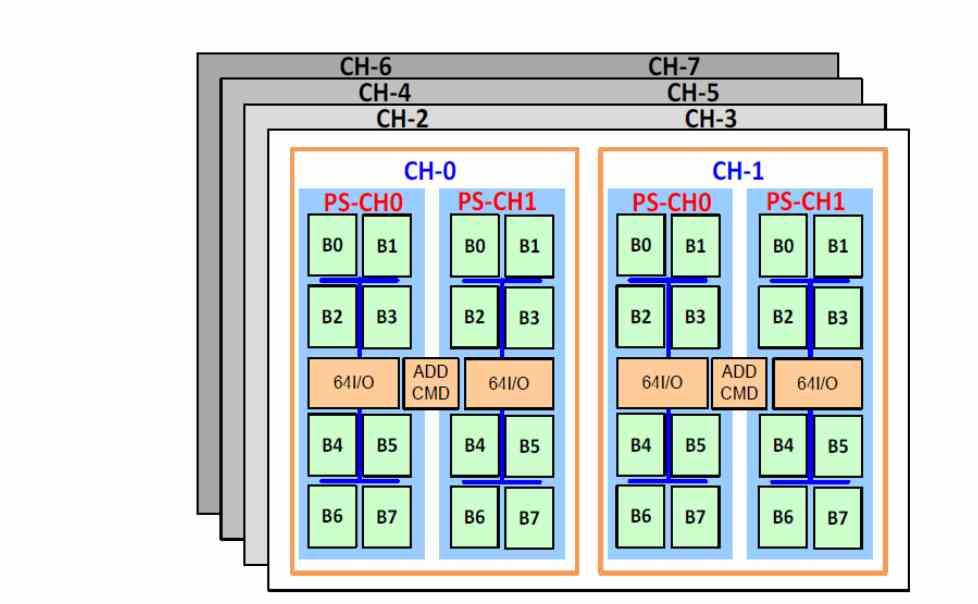
One of the differences of the HBM memory with respect to other types of memory is the support of up to 8 memory channels, which is the configuration that is usually used in servers. Thus, the 8 channels of DDR4 memory are replaced by the 8 channels of HBM memory, which have a much higher bandwidth and lower latency.
Lower latency? Well yes, and all due to the fact of being on the same substrate, this means that memory accesses during the execution of the instructions last less time and therefore there is less latency. The handicap? The HBM2 memory has a much smaller storage capacity and therefore it is necessary to add a memory to a lower level of the hierarchy.
As it has lower latency than DDR4, it is possible to place the HBM as memory for the CPU above the DDR4 memory in the memory hierarchy, and that the data is dumped from the DDR4 to the HBM memory as it is needed and even use NVMe SSD memory underneath with a fast enough PCI Express interface. Of course, with the use of real-time data compression and decompression systems from the SSD to the RAM.
What does a server CPU need HBM memory for?
The HBM memory stands out especially for its enormous bandwidth, which seems completely an exaggeration for a CPU, but it must be taken into account that one of the points in which NVIDIA has a great presence in the server market is in artificial intelligence, thanks to the addition of tensor units in their GPUs since the launch of Volta, so the vast majority of systems used for training and inference for artificial intelligence include such units.
What is the situation of Intel and AMD? The answer is to add this type of units in their servers, in the case of Intel they are the AMX units and in AMD at the moment it is unknown which unit they are going to implement. But the point of adding these drives is to cut back on the NVIDIA hardware for the servers. To this we must bear in mind that AMD has a graphics division that competes against NVIDIA, but we cannot forget the Intel Xe HPC and Intel Xe HP by Intel either.
The units for the AI require a lot of bandwidth to work, in that they coincide enormously with the GPUs, hence NVIDIA sells its GPUs as “AI” PU or vice versa. At the same time, this is the reason why the use of HBM memory will be added to the CPUs, in order to convert them into units that double for both the AI and CPUs.
An evolution that has happened before

In the 1990s, DSP units were used to speed up emerging multimedia applications. Where are these units right now? They disappeared as soon as SIMD units were implemented in CPUs and the implementation of a DSP unit for acceleration of multimedia algorithms was no longer necessary.
In the case of AI, the concept is the same, the idea of implementing tensor units in the CPUs for servers is looking to be able to dispense with the GPUs for these tasks. So from a business point of view for Intel and AMD the message can be summarized as “Don’t buy a GPU with units for AI when you can already do it on the CPU.”
NVIDIA GPUs owe their power to AI thanks to the huge number of shader units or SM, for example the GA102 has 82 SM in its configuration, which is much more than the number of cores in a desktop CPU. In a server CPU we speak of dozens of cores, for example the AMD EPYC can reach up to 64 cores and will grow in the next generations. With this we can understand much better how the adoption of HBM memory in server CPUs is going to be, especially in the face of a market with increasingly AI-centric applications.