Ray Tracing is an algorithm for rendering scenes that has been widely used in the world of offline animation but that in real-time environments such as video games is now when it begins to emerge. In this article we will talk about the past, present and future evolution of the hardware regarding ray tracing so that you can get an idea of what we can expect.
As with rasterization, where initially it was only possible on supercomputers, then on workstations and later on home computers with 3D cards, ray tracing or known by its English name “Ray Tracing” has had the same evolution and what years ago was only possible with very powerful and expensive systems is increasingly available to everyone.

The evolution of hardware with respect to Ray Tracing

That is why we have decided to do a retrospective to show you the evolution of the hardware as far as Ray Tracing is concerned; We have divided this evolution into five different stages, and in them we will not only talk about the methods of the past but also the methods that we are going to see in the near future and that therefore will be implemented in future generations of the GPUs that will equip our PCs.
Stage 1: Rendering via CPU

It must be taken into account that GPUs for a long time were tied to the rasterization algorithm, so they were not suitable for rendering scenes based on Ray Tracing, which uses a different algorithm.
The solution that existed for when you wanted to render a scene via ray tracing? Pulling multi-core CPUs and although this is already part of history, it was the approach that Intel wanted to execute with its canceled and failed Larrabee a little over a decade ago, which was nothing more than several x86 cores in a configuration very similar to a GPU.

This solution turns out to be the most inefficient because CPUs are scalar systems designed to work with a single task per thread of execution and compared to a GPU they have very few threads running simultaneously, forcing it to be necessary to create supercomputers of dozens if not hundreds of CPUs for rendering.
Stage 2: Ray Tracing on the GPU through Compute Shaders
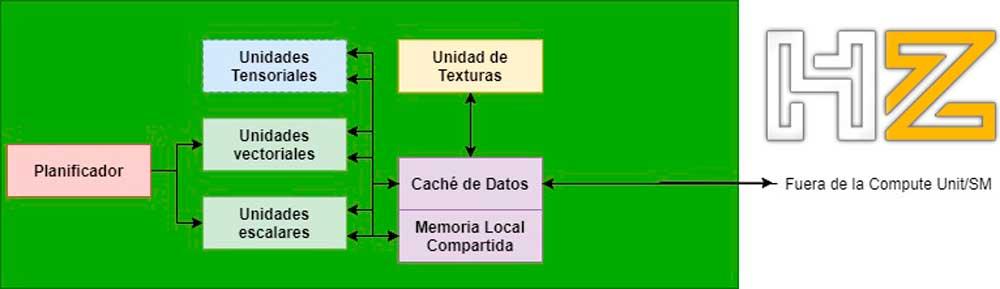
Starting with DirectX in version 11 and OpenGL in version 4, a new type of shader programs for GPUs called Compute Shaders appeared, which are not associated with a stage of the graphic pipeline.
Thanks to them, the GPUs were able to focus their power totally or partially on solving problems beyond rasterization and among them it was possible to implement ray tracing in the GPU, not at a sufficient speed to allow real-time rendering, but yes in order to implement a pipeline of successive stages via Compute Shaders.
But it was not until DirectX 12 that it began to be possible to propose a complete rendering pipeline for Ray Tracing where each of the specific stages is a Compute Shader performing one of these stages in particular.
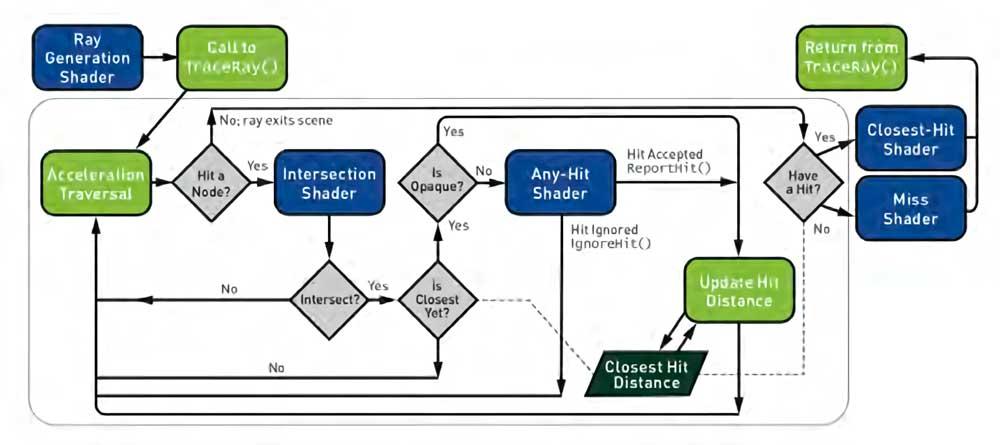
This pipeline is the one that ended up being standardized as of 2018 as a preliminary to DirectX Ray Tracing and was later also adopted by Vulkan; however, this early GPU implementation for real-time ray tracing was not good enough in terms of performance and changes were required to the classic Compute Unit / SM.
Stage 3: Units of intersection
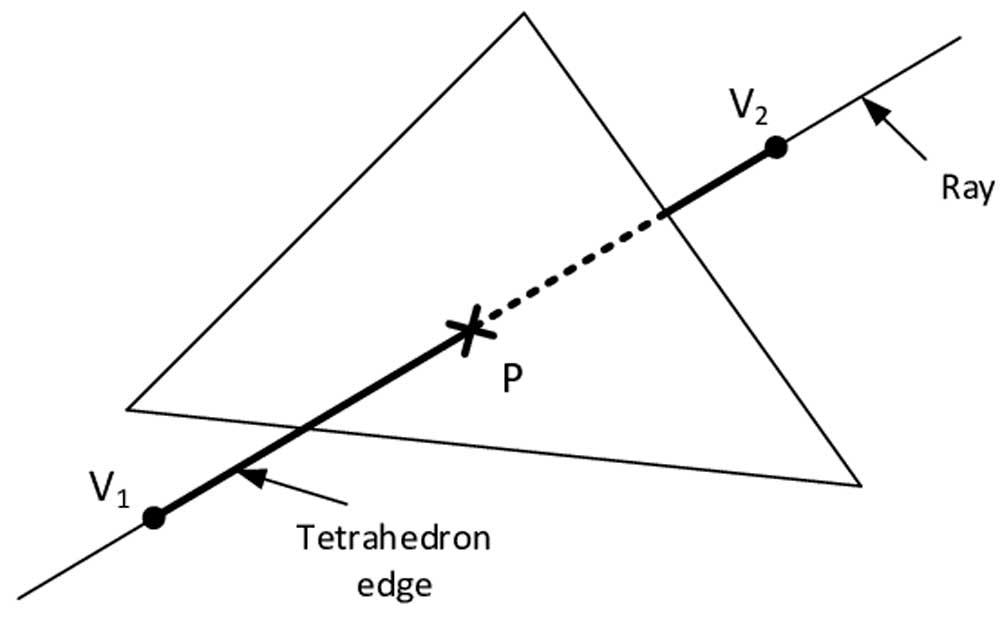
Something that is common in hardware design is to create accelerators to perform repetitive and repetitive tasks for a cost in area and energy much lower than a full processor, the idea is to unload these tasks on those specialized processors.
These types of units are common in GPUs. For example, when it comes to rasterization, we find units with a fixed function that perform operations such as rasterizing triangles, filtering textures, etc. These units are wired and always perform the function from the input data that is given to it and that is why they are called fixed function, because we cannot change their function, that is, they are not programmable. The advantage of this type of unit is that it allows us to carry out those specific calculations using very small units, with very little consumption and that work completely in parallel.
In Ray Tracing, each of the rays that are generated during the scene will hit one or more objects in the scene, so it is necessary to perform this calculation continuously and repeatedly that we call intersection, so it is the type ideal process ending in the form of a specialized unit operating in parallel.
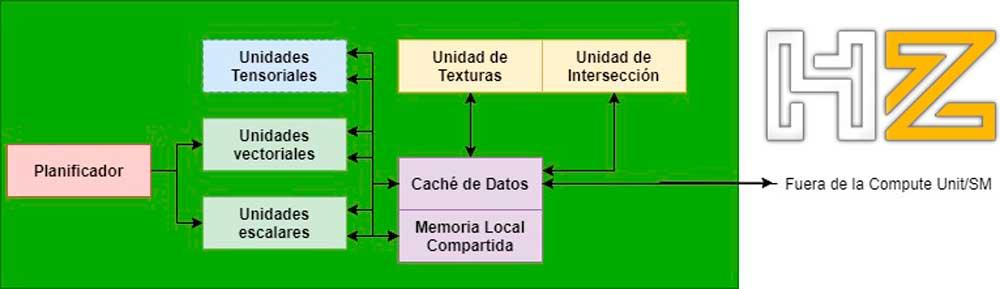
In the case of the intersection units, within the GPU they are found within the Compute Units / SMs in the AMD / NVIDIA graphics units (in any case we are talking about the same type of unit in both cases, but with a different name) and they communicate with the ALUs in charge of executing the shaders through the data cache within the same unit.
Stage 4: BVH Tree Travel Units
The BVH is a spatial data structure that stores the geometry of the scene in an orderly manner. In order to speed up the process of calculating the intersection, what is done is to perform this on the BVH tree instead of doing it pixel by pixel.
Without the units in charge of traversing the BVH tree, it is necessary to do it with the compute shader program, but with these units implemented at the hardware level we forget about having to carry out this process.
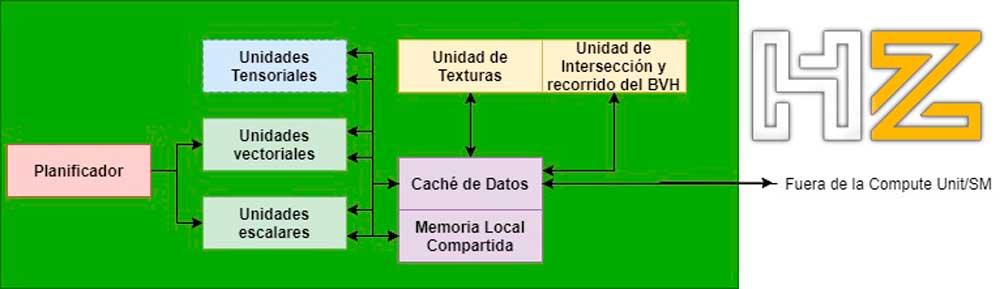
In other words, a path unit will generate all the rays and their path through the BVH tree automatically without the participation of a shader program and will interact with the intersection unit. Both at the end of the process will send the results back.
It must be taken into account that in the current version of DirectX 12 Ultimate this is not part of the minimum specification and it is necessary to control the creation of new rays from the intersection of others with objects through the Ray Generation Shader. So the use of this unit is limited, since it is preferred to give the power to the game developers for the moment about the lightning density in the scene.
Stage 5: Coherent Ray Tracing
The next stage in the evolution of GPUs for Ray Tracing will be the addition of a coherence unit in the GPU, but first of all we have to understand what we mean with memory coherence from the point of view of any processor, being this that the vision of the memory of each processor is the same, specifically of contemporary GPUs.
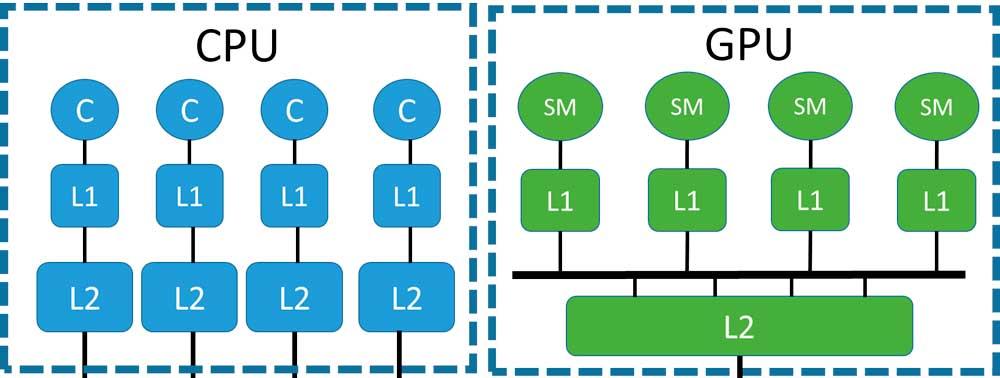
If we want to understand the problem with memory coherence, then we have to understand how the caching mechanism of any multi-processor system works, whether we are talking about a CPU or a GPU.
- Caches are not RAM themselves, but rather store specific portions of RAM or higher cache levels.
- The lower levels of the cache and closest to the processors contain copies of portions of data from the higher level caches.
Therefore, if we want to make a coherent system, a mechanism has to be created that when a core or other unit of the GPU changes the value of a data, all the copies that refer to that data in all the caches are also changed in a way simultaneous as well as in VRAM.
So what problem are GPUs facing now? Before we have commented that the intersection and traversal unit of the BVH have access to the data cache of the Compute Unit / SM, but since there is no consistency mechanism, when a change is made to the data in a Compute Unit / SM then the rest of the units are unaware of it, and this leads to a good part of the intersection and distance calculations being repeated even if they have already been carried out by other units.
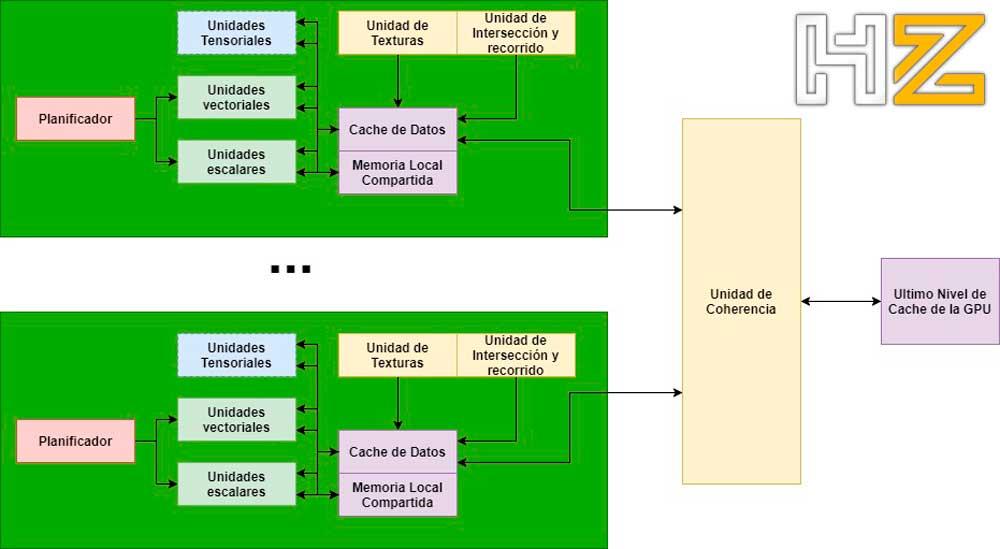
The coherence unit is one or more hardware units responsible for notifying all Compute Units / SMs of changes in the content of the caches, so it is difficult to implement hardware due to the amount of intercommunications it requires .
In a CPU, coherence can be achieved easily due to the fact that we have very few cores inside it, but in a GPU the greater number of cores makes the coherence system difficult to implement; keep in mind that the number of data paths that need to be implemented is n 2 where n is the number of elements interconnected with each other.
Since GPUs are on the way to being divided into chiplets, it is quite possible that this coherence unit becomes a chiplet itself or is in the central part in charge of communicating the different parts with each other. In any case, we have not yet reached this point and given that the changes at the level of architecture are taking place in periods of 2 to 5 years, we will still have to wait a bit.
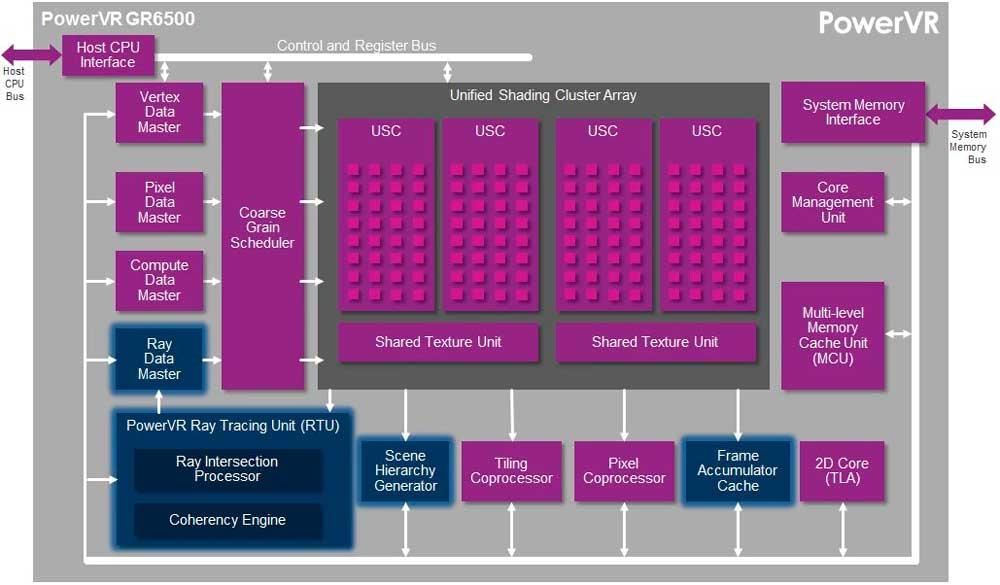
Where the Coherency Engine is implemented is in Imagination’s PowerVR Wizard architecture, since it has been implemented in that hardware for years, but NVIDIA and AMD have not yet implemented it in their GPUs and it must be taken into account that they have approach a “little” different from Imagination; In any case, it is the next evolution for Ray Tracing.