
The first processor with out-of-order execution was the IBM POWER 1, which would be the basis for the RISC processors of the same name and the PowerPCs. Intel adopted this technology for the x86 in its Pentium Pro. Since then all PC CPUs make use of out-of-order technology as one of the bases to get the maximum possible performance.
The main concern in the design of processors is often not to get the most power, but the best performance when executing the instructions. We understand performance as the fact of approaching the theoretical ideal of a processor’s operation. It is useless to have the most powerful CPU if, due to limitations, the only thing it has is the potential to be and is not.
Two ways of dealing with parallelism
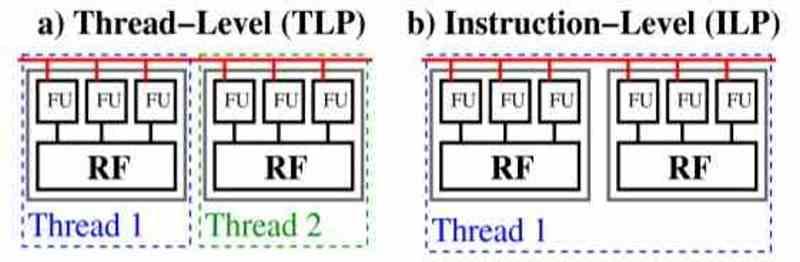
There are two ways to treat parallelism in the code of a program, these are thread-level parallelism or ILP and instructional parallelism or TLP.
In the TLP, the code is divided into several subprograms, which are independent of the others and work asynchronously, that means that each of them does not depend on the code of the rest. When we are in a TLP processor, the key is that if an execution stop occurs for some reason then the TLP processor takes another of the execution threads and places the idle one on hold.
ILP processors are different, their parallelism is instruction level and therefore in the same thread of execution, so they cannot cheat by putting the main thread on hold. Nowadays, the CPUs combine the two types of execution, but the ILP is still exclusive to CPUs and it is where they get a great advantage in terms of serial code over fully parallelizable code.
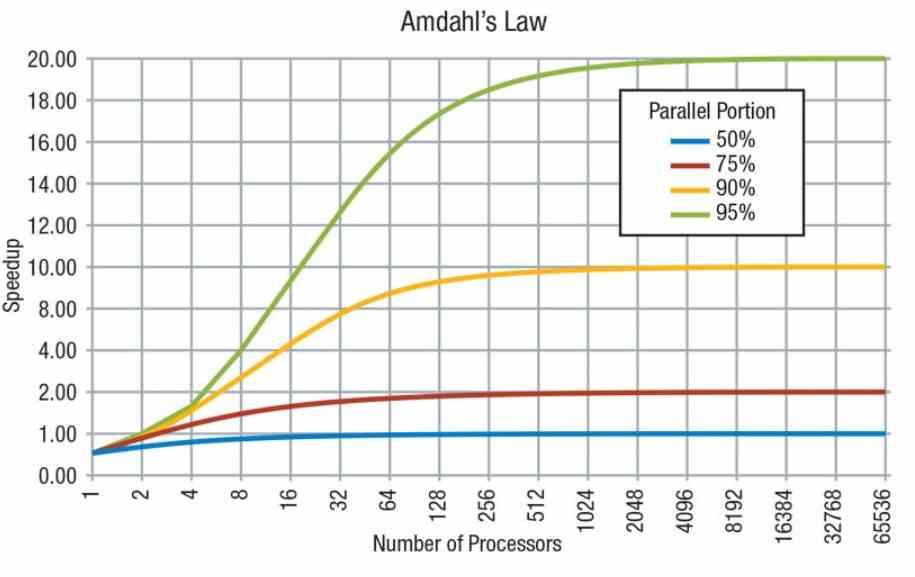
We cannot forget that according to Amdahl’s Law, a code is made up of parts in series, which can only be executed by one processor, and in parallel, which can be executed by several processors. However, not everything can be parallelized and there are serial parts of the code that require serial operation.
In the last 15 years the concept has been developed in which parallel algorithms are executed on GPUs, whose cores are of the TLP type, while serial code is executed on CPUs that are of the ILP type.
In-order execution of instructions
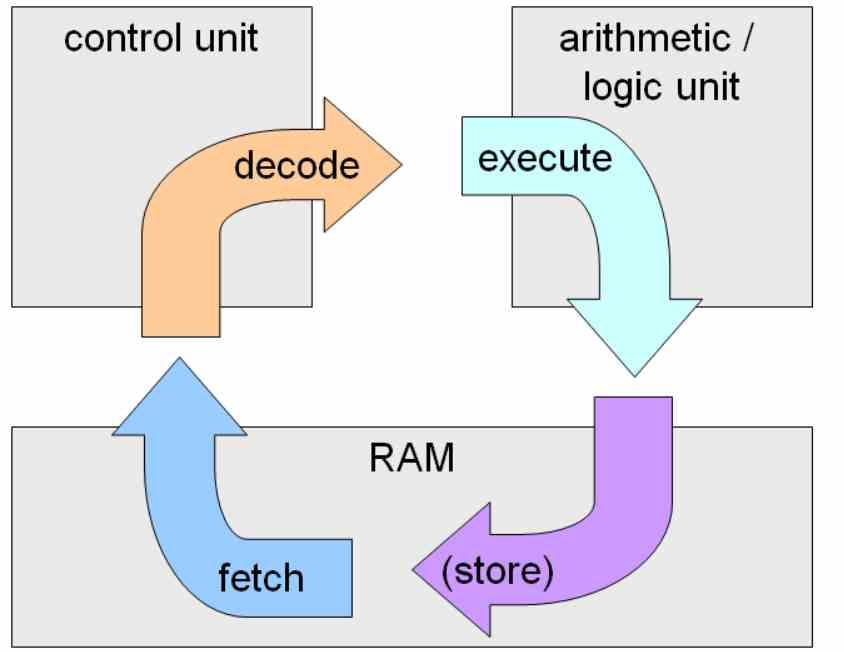
In-order execution is the classic instruction execution, its name is due to the fact that the instructions are executed in the order that they appear in the code and the next instruction cannot continue until the previous one has not been resolved.
The greatest difficulty of in-order execution is in the conditional and jump instructions, since this will be executed when the condition occurs, greatly slowing down the speed of code execution. This is a huge problem when the number of stages in a processor is extremely high, which is what happens when a CPU runs at high clock speeds.
The trap to achieve high clock speeds is to segment the resolution of instructions to the maximum with a large number of sub-stages of the instruction cycle. When a jump or an erroneous condition occurs then a considerable number of instruction cycles are lost.
Out-of-order, accelerating the ILP

Out-of-order or execution out of order is the way in which the most advanced CPUs execute the code and it is thought to avoid the execution stops. As its name indicates, it consists of executing the instructions of a processor in a different order than those indicated in the code.
The reason this is done is because each type of instruction has a type of execution unit assigned to it. Depending on the type of instruction, the CPU uses one type of execution unit or another, but these are limited. This can cause a stop in the execution, so what is done is to advance the next instruction in its execution, pointing in a memory or internal register which is the real order of the instructions, once they have been executed they are sent in back in the original order that they were in the code.
Using out-of-order allows you to expand the average number of instructions resolved per cycle and bring it closer to the ideal of performance. For example, the first Intel Pentium had in-order execution and was a CPU capable of working with two instructions against the 486 that could only work with one, but despite this its performance due to stops was only 40% additional.
Additional stages for out-of-order
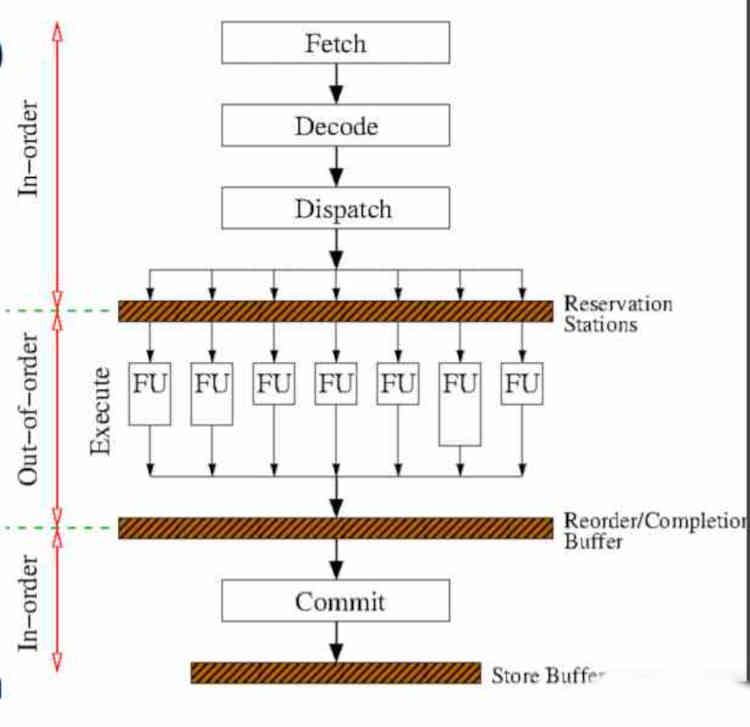
The implementation of out-of-order execution adds additional stages to the instruction cycle, which we already talked about in the article titled This is how your CPU executes the instructions given by the software, which you can find in HardZone.
In fact, only the central part of the execution of the instruction varies with respect to the execution in-order, these changes occur before the execution stage, so the first two that are fetch and decode they are not affected, but two new stages are added, which occur before and after the execution of instructions.
The first stage is the standby stations, in it the hardware waits for the execution units to be free. Its implementation is complex, since it is based on a mechanism that not only watches when an execution unit is free, but also counts the average duration in clock cycles of each instruction that is being executed to know how it has to reorder the instructions.
The second stage is the reordering buffer, which is in charge of sorting the instructions in order of output. Keep in mind that in order to speed up the output of the instructions in the out-of-order execution, all the speculative instruction branches in the code are executed. The speculative instruction is the one that is given when there is a conditional jump regardless of whether the condition is met or not. So it is at this stage that unconfirmed branches of execution are discarded.