Když máme server s Linux nebo NAS server (který má také operační systém založený na Linuxu) se spoustou informací uvnitř, a to jak samotného operačního systému, tak osobních nebo pracovních souborů a složek, je nezbytné kontrolovat, zda jsou pevné disky a SSD disky jsou v dobrém zdravotním stavu a v dohledné době se bez varování nerozbijí. Z tohoto důvodu je velmi důležité neustále monitorovat pevný disk nebo SSD našeho serveru, aby nedošlo ke ztrátě dat v důsledku jeho poškození. Dnes vám v tomto článku ukážeme vše, co byste měli zkontrolovat na svém linuxovém serveru, abyste zkontrolovali stav svých disků.

Jaký je SMART disků
Všechny pevné disky a SSD disky mají technologii zvanou SMART, nebo také známou jako SMART, což je zkratka pro „Self Monitoring Analysis and Reporting Technology“. Tato technologie začleněná do firmwaru pevných disků a SSD spočívá v detekci možných poruch na pevném disku s cílem předvídat fyzické chyby na pevném disku nebo neočekávané poruchy SSD disků v důsledku zápisu do interní flash paměti. . Cílem SMART je upozornit uživatele, aby mohli zálohovat a vyměnit disk bez ztráty dat. Pokud budeme SMART ignorovat, přijde čas, kdy se pevný disk rozbije a přijdeme o data, proto je nezbytné vždy dávat pozor na SMART data disků.
Pro použití SMART je bezpodmínečně nutné, aby BIOS nebo UEFI serveru byl kompatibilní s touto technologií a aby byla aktivována, navíc je také bezpodmínečně nutné, aby ji disky obsahovaly. Dnes všechny servery, operační systémy a disky tuto technologii používají k detekci problémů na pevném disku, dalo by se říci, že je „univerzální“ a že se vždy používá.
Tato technologie je zodpovědná za sledování různých parametrů pevného disku, jako je rychlost diskových ploten, vadné sektory, chyby kalibrace, cyklická kontrola redundance (typické chyby CRC), teplota disku, rychlost čtení dat, čas spuštění (spin- nahoru), počítadlo přerozdělených sektorů, rychlost vyhledávání (doba vyhledávání) a další velmi pokročilé parametry, které vám umožní vědět, co je důležité: pokud dojde k brzkému selhání pevného disku.
Interně má SMART rozsah hodnot, které můžeme považovat za „normální“, a když parametr překročí tyto hodnoty, to znamená, že se spustí alarm, BIOS/UEFI jej detekuje a oznámí operačnímu systému, že došlo k chybě. v systému. disk a to může být vážné. V operačních systémech Linux máme možnost provádět SMART testy pro kontrolu, zda disk funguje správně, navíc máme možnost tyto testy naprogramovat, abychom minimalizovali dopad na výkon.
Jak zobrazit stav disku
Ve většině distribucí založených na Linuxu máme balíček nazvaný smartmontools. Někdy je tento balíček v naší distribuci předinstalovaný a jindy si jej musíme nainstalovat sami. Tento balíček má dva různé programy:
- smartctl : je program příkazového řádku, který nám umožňuje na požádání ověřovat pevné disky a SSD, nebo můžeme jeho činnost naprogramovat pomocí typického cronu v operačním systému.
- chytrý : je démon nebo proces, který ověřuje, že pevné disky nebo SSD v určeném intervalu nevykazovaly žádné selhání. Je schopen zaregistrovat jakýkoli typ varování nebo chyby disku do hlavního syslog serveru, umožňuje také zasílat stejná varování a chyby e-mailem administrátorovi, aby mohl ověřit, že je vše v pořádku.
Balíček smartmontools je zodpovědný za monitorování pevných disků a SSD disků, bez ohledu na to, zda používají rozhraní SATA, SCSI, SAS nebo NVME, podporuje jakýkoli typ datového rozhraní. Tento program je samozřejmě zcela zdarma.
Instalace
Instalace tohoto programu, pokud není standardně nainstalována ve vaší distribuci Linuxu, se provádí pomocí správce balíčků vaší distribuce. Například na operačních systémech Debian s apt by to bylo takto:
sudo apt install smartmontools
V závislosti na správci balíčků vaší distribuce budete muset použít ten či onen příkaz, důležité je, že tento balíček je dostupný pro všechny unixové distribuce a také Linux, takže byste jej bez problémů mohli nainstalovat i na FreeBSD.
Pomocí smartctl
Abychom mohli používat tento program a kontrolovat stav našeho pevného disku, musíme nejprve vědět, kolik pevných disků máme a jaká je cesta ke zkoumání těchto pevných disků nebo SSD. Abychom věděli, kde jsou disky, musíme provést následující příkaz:
df -h
Můžeme také použít fdisk k získání seznamu disků, které máme na našem serveru:
sudo fdisk -l
Tyto příkazy nám zobrazí seznam jednotek a také oddílů. Tento program musíme používat na úrovni pevného disku nebo SSD, nikoli na úrovni diskových oddílů. Obecně v systémech Linux najdeme disky v cestě /dev/sdX.
Jakmile budeme vědět, který disk budeme analyzovat, abychom zkontrolovali jeho stav pomocí SMART, musíme vědět, že existují celkem dva různé testy, které můžeme provést:
- Krátký test – Tento test se nejčastěji používá k detekci problémů s diskem. Při provádění tohoto testu nám ukáže nejdůležitější chyby a varování, aniž by bylo nutné podrobně rozebírat celý disk. Tento krátký test můžeme přes cron naplánovat na týdenní, takto jednou týdně provede tuto analýzu a upozorní nás, pokud zjistil nějaké chyby. Tento test je vhodné dělat v době, kdy je málo nebo žádné využití, nedoporučuje se to dělat v pracovní době, lépe za svítání.
- Dlouhý test – Tento test může trvat poměrně dlouho v závislosti na disku a jeho kapacitě. Provedením tohoto komplexního testu nám ukáže všechna varování či chyby, které na celém disku najde. Tento dlouhý test s cronem můžeme naplánovat tak, aby se dělal měsíčně, to znamená, že jednou za měsíc provedeme tento test, abychom zkontrolovali stav disku. Tento test je vhodné provést v době, kdy je disk málo využíván, například za svítání, protože jinak se značně zvýší výkon čtení a zápisu a také latence přístupu k datům.
Jakmile známe dva typy testů, které můžeme použít, první věc, kterou potřebujeme vědět, je, zda má pevný disk nebo SSD povoleno SMART:
sudo smartctl -i /dev/sda
V případě, že disk podporuje SMART, ale není aktivován, můžeme jej aktivovat provedením následujícího příkazu:
sudo smartctl -s on /dev/sda
Chcete-li zobrazit všechny atributy SMART výrobce příslušného disku, můžeme provést následující příkaz:
sudo smartctl -a /dev/sda
K provedení krátkého testu provedeme následující:
sudo smartctl -t short /dev/sda
K provedení dlouhého testu provedeme následující:
sudo smartctl -t long /dev/sda
Jakmile provedeme krátký nebo dlouhý test, můžeme provést následující příkaz a zobrazit všechny výsledky:
sudo smartctl -H /dev/sda

Doporučujeme přečíst si manuálové stránky smartctl, kde najdete všechny příkazy, které budeme moci provést, abychom využili možností SMART, nicméně hlavní příkazy jsou ty, které jsme vám vysvětlili.
Na jaké hodnoty se mám dívat?
Když uděláme SMART test, objeví se velké množství atributů našeho pevného disku nebo SSD. Některé z těchto hodnot jsou kritické, kterým věnujeme velkou pozornost, protože by nám mohly poskytnout „nápovědu“, že disk velmi brzy selže:
- Reallocated_Sector_Ct: je počet sektorů, které byly přerozděleny do jiných oblastí disku, protože došlo k chybám čtení. Tato chyba je velmi typická, když je disk velmi starý a blíží se ke konci své životnosti.
- Spin_Retry_Count: je počet pokusů, které byly nutné ke spuštění disku, což znamená, že na disku je vážný hardwarový problém a nemusí se příště spustit.
- Reallocated_Event_Count – Počet realokací, které byly úspěšně nebo neúspěšně provedeny. Čím vyšší číslo, tím horší stav pevného disku.
- Current_Pending_Sector: počet sektorů, které čekají na brzké přerozdělení.
- Offline_Uncorrectable: počet neopravitelných chyb při přístupu, ať už čtení nebo zápisu, do různých sektorů disku.
- Multi_Zone_Error_Rate: celkový počet chyb během zápisu sektoru.
Na následujícím obrázku můžete vidět stav pevného disku WD Red 4TB z našeho NAS s operačním systémem XigmaNAS:

Na předchozím snímku obrazovky můžete vidět spoustu informací, ale musíme vědět, zda se jedná o ojedinělé selhání nebo může brzy selhat náš disk.
Stav disků v QNAP NAS
Pokud máte server QNAP, Synology nebo ASUSTOR NAS, budete také moci vidět SMART stav vašich pevných disků a SSD prostřednictvím operačního systému s webovým přístupem, není třeba zadávat přes SSH nebo Telnet a provádět žádné příkazy . V níže uvedeném příkladu jsme použili server QNAP NAS, ale proces s ostatními výrobci by byl velmi podobný.
První věc, kterou musíme udělat, je jít do „ Úložiště a snímky “, jednou zde klikněte na “ Úložiště / Disky “ a uvidíme něco takového:

Pokud klikneme na „ Stav disku “, budeme si muset vybrat, na který disk ze všech se chceme podívat. Můžeme vybrat jak pevné disky HDD, tak i SSD disky, bez ohledu na typ, protože mají také interní informace SMART, aby se zjistilo, zda nedošlo k chybě disku.

V nabídce „Souhrn“ vidíme celkový stav disku, pokud se vyskytne jakýkoli typ chyby nebo závažného varování, můžeme snadno a rychle vidět také celkový stav, aniž bychom museli provádět podrobnou analýzu SMART hodnoty . Samozřejmě můžeme vidět i historii přístupu na disk a jestli se vyskytly nějaké problémy.

Přestože nám QNAP poskytuje velmi snadno srozumitelné informace, v případě, že chceme vidět všechny surové hodnoty, bez problémů to zvládneme také. Kromě toho budeme mít další sloupec, který nám říká „Stav“ a zda je dobrý nebo špatný.
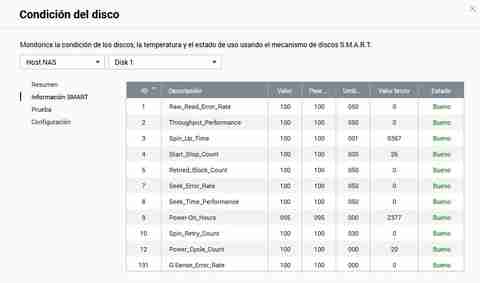
Budeme zde moci provádět rychlé nebo kompletní testy, stačí si vybrat testovací metodu a poté kliknout na tlačítko „Test“.

Nakonec můžeme tyto testy také velmi jednoduchým způsobem naprogramovat, stačí si vybrat aktivaci rychlého nebo úplného testu a zvolit frekvenci: denní, týdenní nebo měsíční, navíc můžeme definovat čas zahájení tohoto testu.

Jak vidíte, kontrola a ověření zdravotního stavu pevných disků a SSD na serveru je něco opravdu důležitého, aby se zabránilo ztrátě dat. Když dojde k jakékoli chybě, je velmi důležité koupit nový disk a vytvořit zálohu, abyste předešli ztrátě dat. Kromě toho bychom měli také zkontrolovat stav RAID, protože bychom mohli způsobit ztrátu celého úložiště, zejména pokud jsme nakonfigurovali ZFS RAID 0 nebo Stripe.
