Although AMD has not specified anything official in this regard or commented on details of RDNA 2 improvements such as architecture, we do have an idea of how it is going to achieve the dreaded task of introducing specific units for Ray Tracing in its GPUs. This will extend to the iGPUs of the consoles, so we are facing a novelty shared by all sectors, but how will they do it?
As it has happened to NVIDIA, AMD will have to carry out, due to pure restrictions of the current architecture, a hybrid approach to Ray Tracing technology, that is, they will have to rely again on the texture processors to give life to the layout ray in real time.

The BVH algorithms will therefore be, once again, key to knowing the performance that the new RDNA 2 architecture will offer by means of fixed function units very similar to NVIDIA. Still, AMD cannot be said to be copying Huang’s, as the implementation is different, but the concept is similar in terms of form.
Shaders will be key to the performance of fixed units
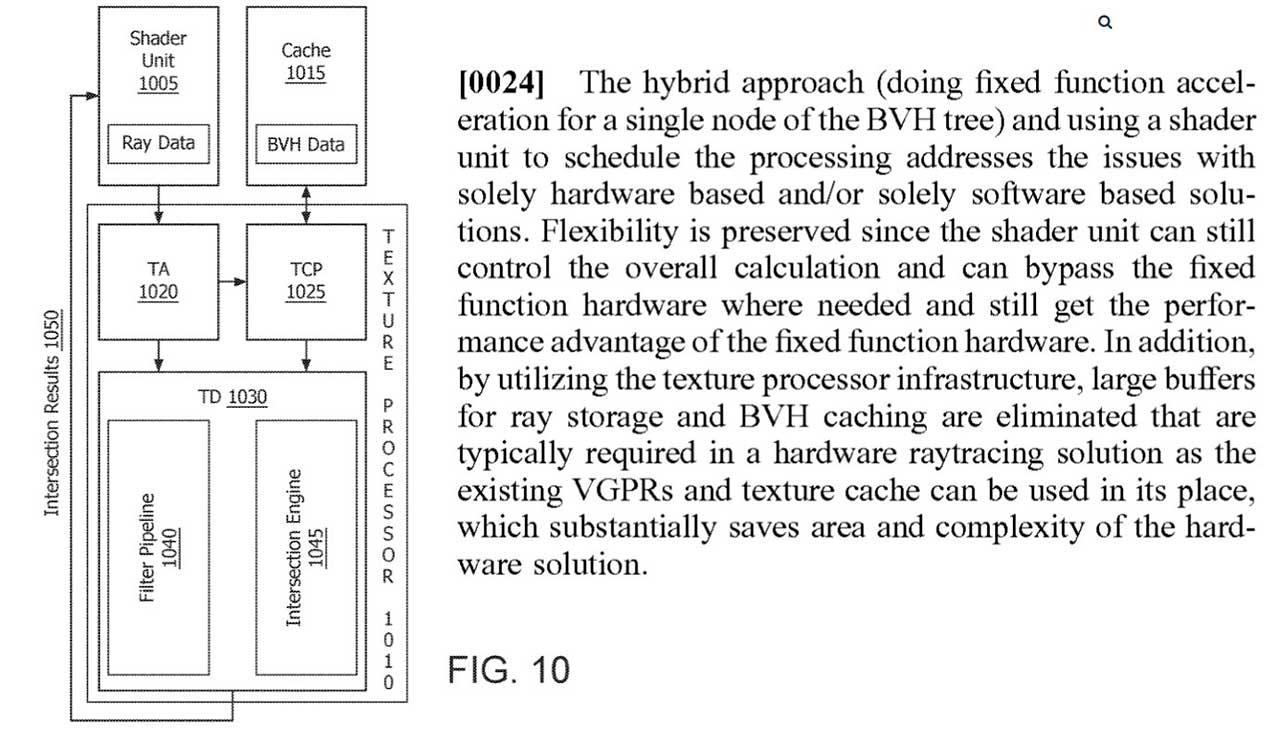
In the case of NVIDIA we have talked a lot about the fixed function units known as RT Cores, so AMD will do the same with its own, which it has called as “fixed function ray intersection engine” , something like an intersection engine of rays as a fixed function.
Actually, and after this name, what we will find will be some hardware units that specialize in BVH algorithms (by software as in Pascal we have already seen the results against Turing at the same graphic power) but at the same time they are not as complex like NVIDIA options.
AMD’s idea is to reduce the storage dependency of ray tracing specific data, using the current memory buffers of the texture system. This has two positive factors: the chip area is not enlarged and at the same time it is a more simplistic design for the architecture.
Without additional hardware scheduler, is AMD’s approach to Ray Tracing optimal?
At the moment it is not clear, there are rumors of an alleged demonstration of Cyberpunk 2077 on an alleged RDNA 2 GPU versus the RTX 2080 SUPER where, apparently, the AMD option is much faster in Ray Tracing. Of course, grab this information with tweezers, it’s just a rumor.
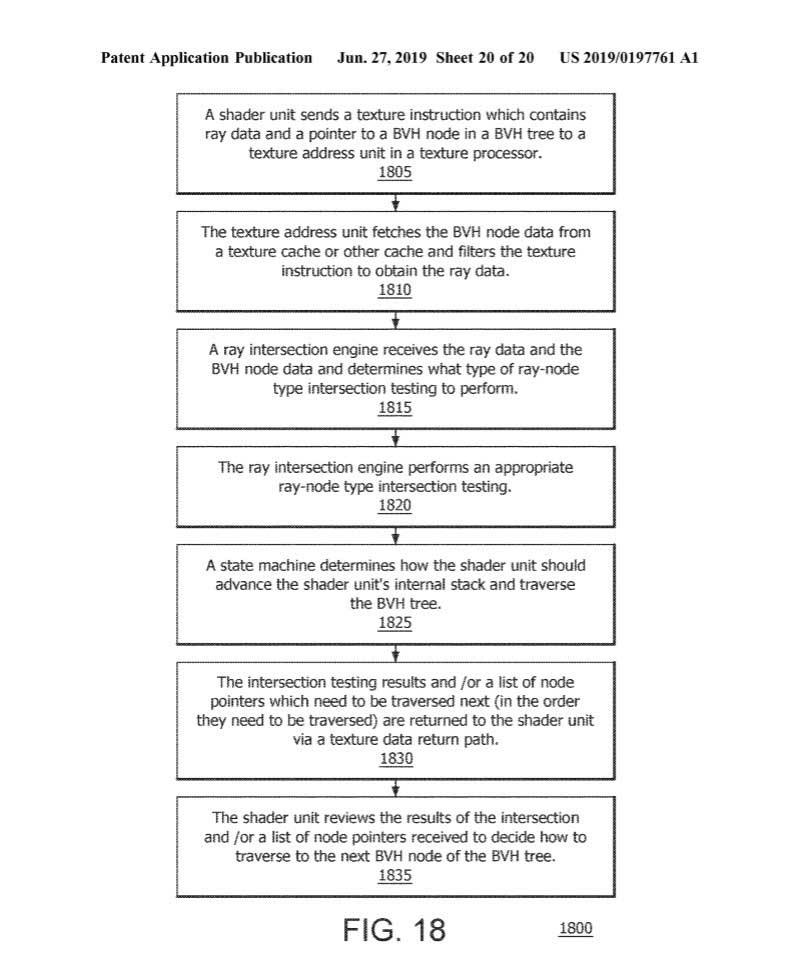
In any case, everything seems to indicate that AMD’s approach is based on the Shaders sending the ray tracing data to the texture pipeline for the fixed intersection motors to process. What does this imply on paper? In theory, more intersections per second are processed and fewer clock cycles are required to carry out these calculations, increasing performance.
For this, the architecture will have a series of units: Shaders, texture processors or TP, larger caches and, above all, an interconnection of these with lightning intersection motors. In summary, AMD’s system is much simpler than NVIDIA’s for developers, since in the case of Huang’s, programmers have to work with at least two different engines (Shader + RT) . Instead, AMD reuses many of its units and buses, where only the new intersection motors are the novelty as such.
It takes advantage of the plot to perform the calculations that are stored in the same cache and gives the programmer the power on which drives and routes it can work, thereby optimizing performance, lowering consumption and not having to create larger chips.
There are two hybrid approaches that work on paper, we will have to wait for both RDNA 2 and Ampere to be on the market to see which technique is the most optimal.