The SWAR concept will seem strange to many, but what happens if we tell you that the SIMD units of your CPUs, GPUs in your systems are mostly of the SWAR type? These types of units differ from conventional SIMD units and have their origin in the multimedia extensions of the late 90s. What are they and what is their use today?
The performance of a processor can be measured in two ways, on the one hand, how fast it executes the instructions in series and that therefore they cannot be parallelized, since they only affect a unit data. On the other hand, those that work with several data and can be parallelized. The traditional way of doing it on CPUs and GPUs? The SIMD units, of which there is a subtype that is highly used in CPUs and GPUs, the SWAR units.

ALUs and their complexity
Before talking about the SWAR concept, we must bear in mind that ALUs are the units of a CPU that are responsible for performing arithmetic and logical calculations with the different numbers. These can grow in complexity in two ways, one from the complexity of the instruction they have to execute. The internal circuitry of an ALU that can perform, for example, the calculation of a square root is not the same as that of a simple sum.
The other is the precision with which they work, that is, the number of bits that they manipulate simultaneously each time. An ALU can always handle data equal to or less than the number of bits for which it is designed. For example, we cannot make a 32-bit number be calculated by a 16-bit ALU, but we can do the opposite.
But what happens when we have several data of lower precision? Normally they are going to run at the same speed as full precision, but there is a way to speed them up, and that’s the over-register SIMD. Which is also a way to save transistors in a processor.
What is the SWAR concept?
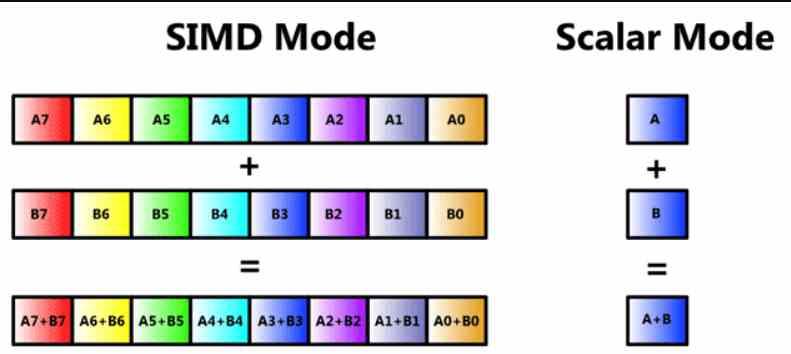
By now, many of the readers will know that it is a SIMD unit, but we are going to review it so that no one loses the thread of this article from the beginning. A SIMD unit is a type of ALU where several data are manipulated through a single instruction at the same time, and therefore there are several ALUs that share the catchment part of what the instruction itself is and its decoding, but where in each one a different piece of information is treated.
SIMD units are usually made up of several ALUs, but there are cases where the ALUs are subdivided into simpler ones, as well as the accumulation register where they temporarily store their data to calculate them. This is called SIMD on a registry or by its acronym in English SWAR, which means SIMD Within a Register or SIMD on a registry.
This type of SIMD unit is highly used and allows a precision n-bit ALU to perform the same instruction but using data with less precision. Usually with half or a quarter precision. For example, we can make a 64-bit ALU act as two 32-bit ALUs by executing said instruction in parallel, or four 16-bit ones.
Digging deeper into the SWAR concept?
This concept is already several decades old, but the first time they appeared on PC was in the late 90s with the appearance of SIMD units in the different types of processor that existed. Veterans of the place will remember concepts like MMX, AMD 3D Now !, SSE and the like that were SIMD units built under the SWAR concept.
Suppose we want to build a 128 bit SIMD unit
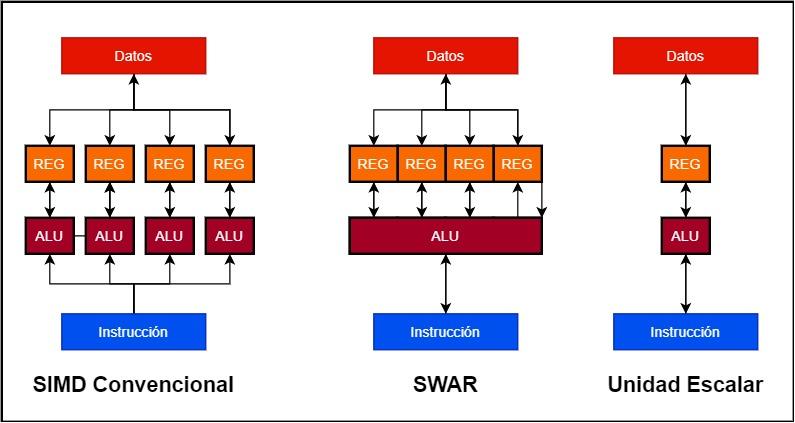
- In conventional SIMD units we have several ALUs working in parallel and each one of them has its own data register or accumulator. Thus, a 128-bit SIMD unit can be made up of 4 32-bit ALUs and 4 32-bit registers.
- Instead a SWAR unit is a single ALU that can work in a very high precision as well as its accumulator register. This allows us to build the SIMD unit using a single 128-bit ALU with SWAR support.
The advantage that the implementation of a SWAR type unit has over a scalar one is simple to understand, if an ALU does not contain the SWAR mechanism that allows it to operate as a SIMD unit with less precision data then it will execute them at the same speed. than the highest precision data. What does this mean? A 32-bit unit without SWAR support, in case it has to operate the same instruction on 16-bit data, will do so at the same speed as a 32-bit one. On the other hand, if the ALU supports SWAR, it will be able to execute two 16-bit instructions in the same cycle, in the event that both come successively.
SWAR as a patch for AI

Artificial intelligence algorithms have a particularity, they tend to work with very low precision data and today most ALUs operate with 32-bit precision. This means adding precision 16-, 8-, and even 4-bit ALUs to a processor to speed up those algorithms. Which is to complicate the processor, but the engineers did not fall into that error and began to pull the SIMD over register in a particular way, especially on GPUs.
Is it possible to combine a conventional ALU SIMD with a SWAR design? Well yes, and this is what, for example, AMD does in its GPUs where each of the 32-bit ALUs that make up the SIMD units of its RDNA GPUs supports SIMD over register and therefore can be subdivided into two 16-bits, 4 of 8 bits or 8 of 4 bits.
In the case of NVIDIA, they have given the burden of accelerating the algorithms for AI to the Tensor Cores, these are systolic arrays composed of 16-bit floating point ALUs interconnected with each other in a three-axis matrix, hence the unit name. Tensor. They are not SIMD units, but each of their ALUs does support SIMD over register by being able to perform twice as many operations with 8-bit precision and four times with 4-bit precision. In any case, Tensor units are important because they are designed to accelerate matrix-to-matrix operations at a much higher speed than with a SIMD unit.