RTX 3000 вышел несколько месяцев назад, заменив RTX 2000, но как сравнить обе архитектуры и каковы изменения от одного поколения к другому, это такой же впечатляющий скачок, как NVIDIA продается или это мелочь? Мы объясняем различия между архитектурами Тьюринга и Ампера.
Стоит ли обменивать RTX 2000 на аналог в RTX 3000? С нашей точки зрения, если вам нужна максимальная производительность, да, но в то же время мы считаем, что важно демистифицировать оба поколения графических процессоров, поэтому мы собираемся их сравнить.

Чем Тьюринг и Ампер одинаковы в архитектуре?

Есть ряд элементов, в которых не было изменений от одного поколения к другому, поэтому не было никаких внутренних изменений, и они по-прежнему работают одинаково в Ampere по сравнению с Turing.
Список элементов, которые не были изменены, открывается процессорами команд в середине обоих графических процессоров. Какая часть отвечает за чтение списков команд из основного Оперативная память и организация остальной части GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР элементы. Далее следуют фиксированные функциональные блоки для рендеринга посредством растеризации: блоки растра, тесселяция, текстуры и ROPS.
Не изменилась и структура внутренней памяти, то есть иерархия кеш-памяти, которая осталась той же в Ampere и не изменилась по отношению к Turing, поскольку она остается неизменной в обеих архитектурах, единственным элементом иерархии памяти является память GDDR6X. интерфейс, используемый графическими процессорами на базе чипа NVIDIA GA102, такими как RTX 3080.
В каких элементах Тьюринг и Ампер разные

Нам нужно заглянуть внутрь модулей SM, чтобы увидеть изменения в RTX 3000 на основе Ампера по сравнению с RTX 2000 на основе Тьюринга, и это изменения, которые были сделаны по трем различным направлениям:
- Модули с плавающей запятой в FP32
- Тензорные ядра.
- Ядра RT.
Вне этих элементов и количества модулей SM, которое у GeForce Ampere больше, чем у GeForce Turing, изменений нет, поэтому NVIDIA переработала значительную часть оборудования предыдущего поколения для создания нового. . И прежде чем вы сделаете вывод, что это что-то негативное, позвольте мне рассказать, насколько часто встречается в аппаратном проектировании.
Изменения с плавающей запятой на GeForce Ampere SM

На всех GeForces до Pascal все модули с плавающей запятой назывались ядрами CUDA от NVIDIA. Итак, без лишних слов, без разъяснения того, что это означает помимо вычислений с плавающей запятой. Они подразумевали, что это были блоки с плавающей запятой 32-битной точности.
На самом деле ядра CUDA были логикоарифметическими модулями для 32-битных вычислений с плавающей запятой, но также и модулями того же типа для 32-битных целых чисел. Особенность? Они работали переключенными таким образом, что оба типа не могли работать одновременно.

С изменением Тьюринга и появлением того, что называется параллельным выполнением, причина в том, что поток графического процессора перечисляет объединенные потоки целыми числами и с плавающей запятой и не достигает максимальной занятости слота модуля SIMT с каждым суб -ola, поэтому NVIDIA решила использовать Тьюринг. применить параллельное выполнение. В котором волна из 32 потоков выполнения может выполняться комбинированным способом между целочисленными ALU и ALU с плавающей запятой одновременно, если они доступны.
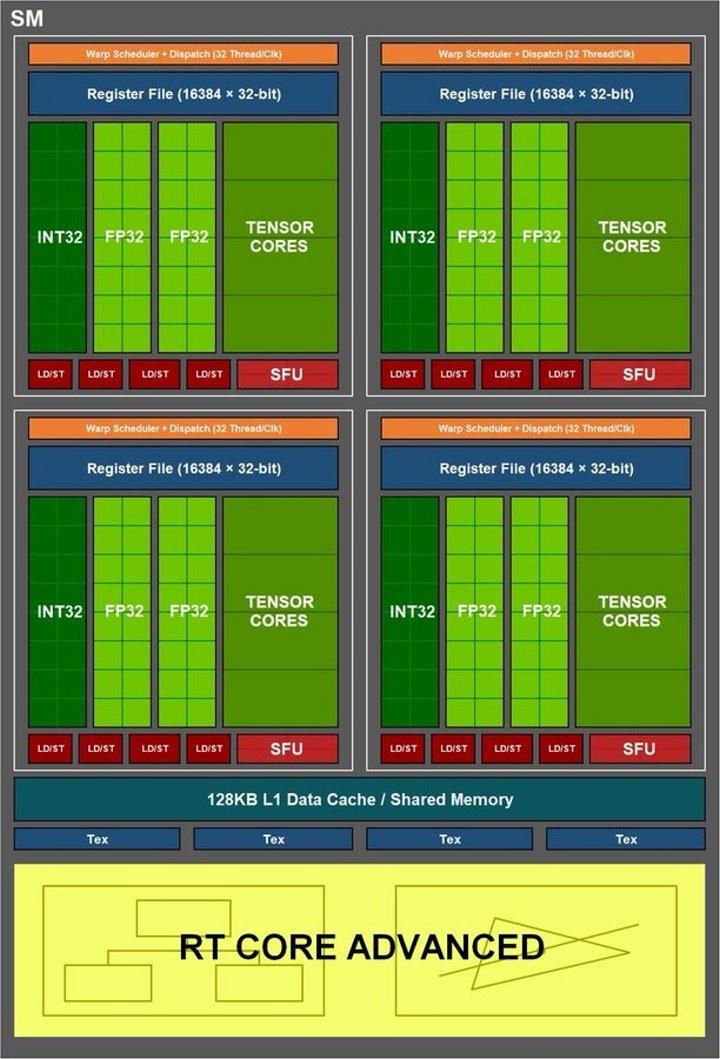
Это означает, что 32-волновое распределение потоков, которое является стандартным размером для графических процессоров NVIDIA, может быть распределено по 16 целочисленным потокам и 16 потокам с плавающей запятой. Но кто-то в NVIDIA предложил изменение для Ampere, которое заключается в том, что набор целочисленных ALU переключается со вторым набором ALU с плавающей запятой, что не требует изменения остальной части SM.
Поэтому в определенные моменты времени и при условии, что входит 32-проводная волна с плавающей запятой, скорость вычислений, измеряемая в TFLOPS, удваивается. Хотя только когда они выполняются в этих условиях и если бы у нас было устройство для измерения скорости TFLOPS, мы бы увидели, что это не тот, который, по словам NVIDIA, дает максимальный пик в своих характеристиках, а что у него будут колебания.
Тензорные ядра на GeForce Ampere

Тензорные ядра - это систолические массивы, которые впервые были выпущены на графических процессорах NVIDIA Volta, и они представляют собой систолические массивы, которые представляют собой тип исполнительного блока, используемого для ускорения алгоритмов на основе ИИ. Эти блоки, в отличие от ядер RT, используют блок управления SM и не могут использоваться одновременно с блоками с плавающей запятой и целыми числами, поэтому, хотя они могут работать одновременно, они делают это, отключая питание от остальных. единиц, кроме RT Cores.
Если мы добавим количество ALU, которое RT-ядра образуют между одним поколением и другим, мы увидим, что есть такое же количество, но с другой конфигурацией. В Turing у нас есть 8 модулей, по 2 на каждое подъядро, по 64 ALU в каждом в конфигурации Tensor 4 x 4 x 4. В то время как в Ampere тензорные ядра имеют конфигурацию из 4 блоков, по одному на каждое суб-ядро, со 1 ALU. для каждого из них.
Ядра RT на GeForce Ampere
Ядра RT - наименее известная часть из всех, поскольку NVIDIA не предоставила никакой информации об их внутренней работе. Мы знаем, что он делает, как работает, но мы не знаем, какие элементы находятся внутри и какие изменения происходили от одного поколения к другому.
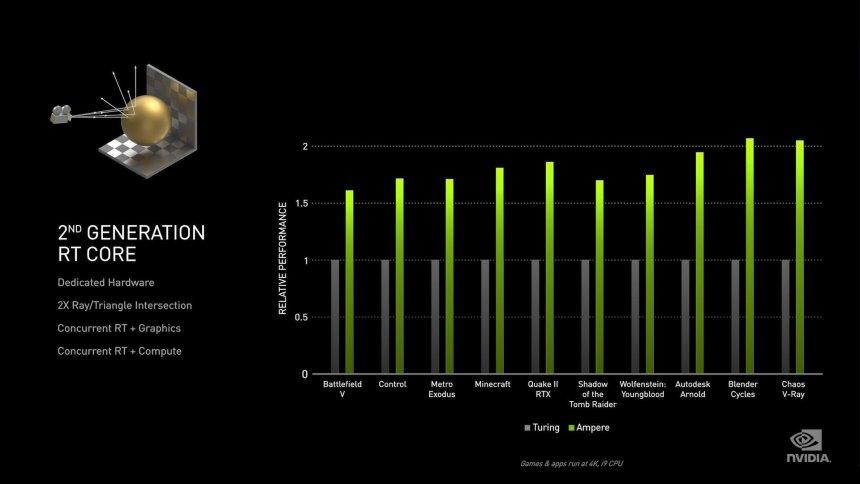
Первое, что бросается в глаза, - это упоминание NVIDIA о том, что ядра RT теперь могут делать вдвое больше пересечений на треугольник, что не означает, что вдвое больше пересечений в секунду. Причина этого в том, что при обходе дерева BVH он делает пересечение прямоугольников, которые являются различными узлами дерева, и только последнее пересечение дерева происходит с треугольником, который самый сложный в исполнении. Модули для вычисления пересечения прямоугольников намного проще: в теории Тьюринга у нас есть четыре модуля, которые работают параллельно, чтобы проходить разные уровни дерева, и один модуль, который выполняет пересечение луча с треугольником.
Второе изменение на аппаратном уровне - это возможность интерполировать треугольник в соответствии с его положением во времени, что является ключом к реализации трассировки лучей с размытием движения, техники, до сих пор не имеющей аналогов в играх, совместимых с трассировкой лучей. В случае, если есть другие изменения, NVIDIA не сообщила об этом публично, и поэтому мы не можем делать дальнейшие выводы.