AMDArhitecturile grafice Radeon au cunoscut puține schimbări în ultimii ani în comparație cu concurența, deoarece de la GCN lansat în 2012 ne-am mutat în RDNA în 2019, care a avut o revizuire recentă cu RDNA. Dar care a fost cu adevărat evoluția GPU-urilor AMD? Citiți mai departe pentru a afla despre schimbările de arhitectură de la GCN la RDNA 2.
In timp ce NVIDIA a avut multe diferite GPU în ultimii ani, AMD este în mod tradițional mai conservatoare, menținând aceeași arhitectură GPU cu modificări minore de ani de zile. Am văzut-o cu GCN, care a fost arhitectura AMD GPU pentru câteva generații și o vedem cu RDNA, unde foile de parcurs indică deja existența unui viitor RDNA 3 cu mai puține modificări decât cele pe care le vom vedea în NVIDIA Lovelace. și Hopper.


Dar nu vom privi spre viitor ca Prometeu, ci să fim mai mult Epimetheus și să privim atât în trecut, cât și în prezent și o vom face în cazul AMD pentru a cunoaște cu adevărat cum diferitele arhitecturi ale AMD au evoluat. Prin urmare, comparația nu se face la nivelul generațiilor, nici între plăcile grafice între ele, ci pentru a înțelege cum a evoluat evoluția de la GCN la RDNA 2.
Evoluția de la GCN la RDNA
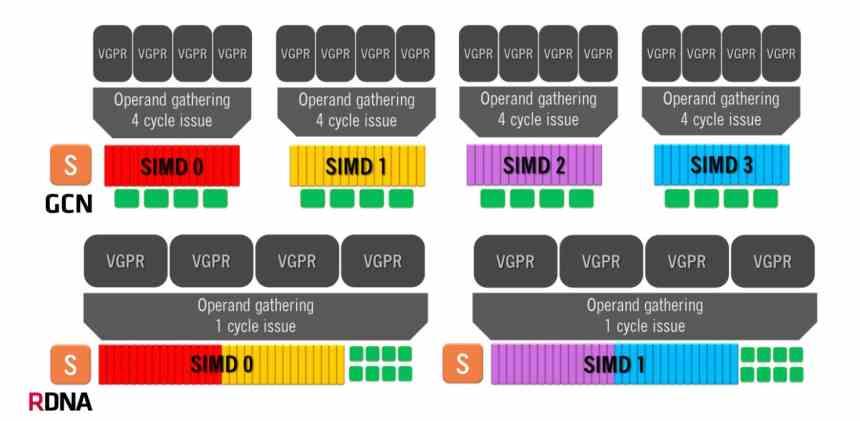
Arhitectura Graphics Compute Next folosește o unitate de calcul compusă din 4 grupuri SIMD de câte 16 ALU, care gestionează unde de 64 de elemente. Aceasta înseamnă că, în cel mai bun caz, în care o instrucțiune este rezolvată pe ciclu, arhitectura GCN va lua 4 cicluri de ceas pe fiecare undă de 64 de elemente.
Pe de altă parte, arhitecturile RDNA au o operațiune diferită, deoarece avem două grupuri de 32 ALU și dimensiunea undelor a trecut de la 64 de elemente la 32 de elemente. Aceeași dimensiune pe care NVIDIA o folosește în GPU-urile sale, așa că acum timpul minim pe undă este de 1 ciclu unic, deoarece avem toate cele 32 de unități de execuție care rulează în paralel. Deși numărul mediu de instrucțiuni rezolvate este încă 64, este o organizație mult mai eficientă.
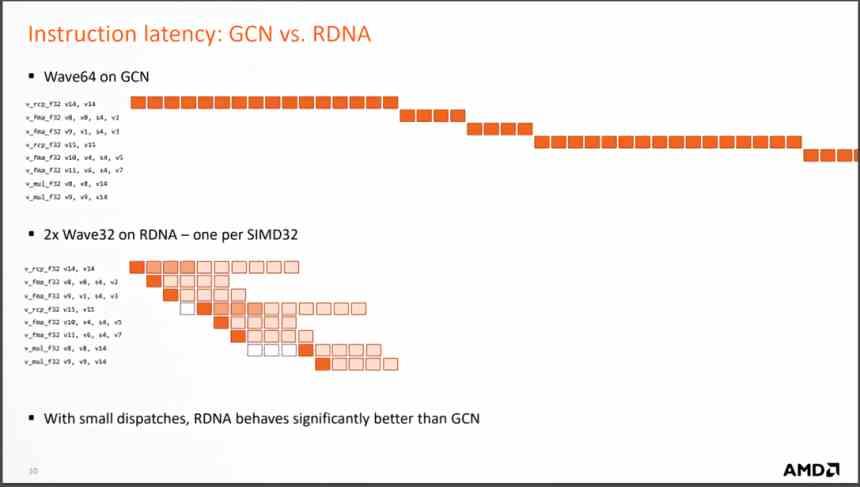
Dar cea mai importantă schimbare este schimbarea la executarea instrucțiunilor care sosesc din fiecare undă, deoarece RDNA le rezolvă în mult mai puține cicluri, ceea ce înseamnă că numărul mediu de instrucțiuni pe ciclu care sunt rezolvate este mult mai mare. iar odată cu aceasta crește IPC mediu.
La ce se traduce acest lucru? Ei bine, întrucât sunt necesare mai puține unități de calcul pentru a obține aceeași performanță, mai puține unități de calcul înseamnă un GPU mai mic pentru a obține aceeași performanță. De fapt, AMD a început să facă designul RDNA de îndată ce a văzut un GTX 1080 cu „doar” 40 SM măturând podeaua cu unitățile de calcul AMD Vega 64. Acesta a fost punctul în care au văzut cum arhitectura GCN nu dă mai mult de la sine.
Evoluția sistemului cache

Pentru a înțelege evoluția de la o arhitectură grafică la alta, este important să cunoașteți sistemul cache și cum a evoluat de la o generație la alta.
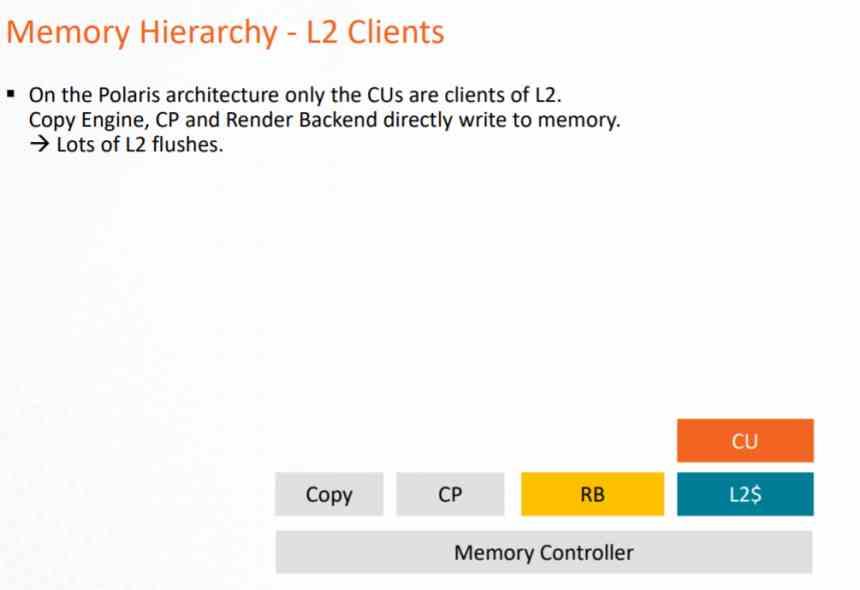
În arhitectura GCN, sistemul cache ar putea fi folosit doar de conducta de calcul, deoarece Pixel Shaders, atunci când este executat, exportă către ROPS și acestea direct pe VRAM, ceea ce presupune o încărcare foarte mare pe VRAM și un consum de energie foarte mare .

Această problemă a fost rezolvată la sfârșitul duratei de viață a acestei arhitecturi cu AMD Vega, unde atât ROPS, cât și unitatea raster comunicau cu cache-ul L2 pentru a reduce sarcina pe magistrala de date către VRAM. Dar mai ales pentru a aplica DSBR sau Tiled Caching, care constă în adoptarea Tile Rendering, dar parțial și pe care NVIDIA îl adoptase deja în Maxwell.

În RDNA, principala modificare a fost să facă totul să devină client L2, dar adăugând un cache intermediar care este L1, în acest fel nomenclatura s-a schimbat.
- Memoria cache L1 inclusă în Unitățile de calcul devine memoria cache L0, cu aceeași funcționalitate.
- Se adaugă o memorie cache L1, care este intermediară între memoria cache L0 și memoria cache L2.
- Toate elementele GPU trec acum prin memoria cache L2.
Toate operațiile de scriere sunt efectuate direct pe memoria cache L2, în timp ce memoria cache L1 este doar în citire. Acest lucru se face pentru a evita implementarea unui sistem de coerență mai complex pe GPU care ar ocupa un număr mare de tranzistoare. Deoarece datorită memoriei cache L1 numai în citire, puteți acorda datele mai multor clienți din GPU în același timp.
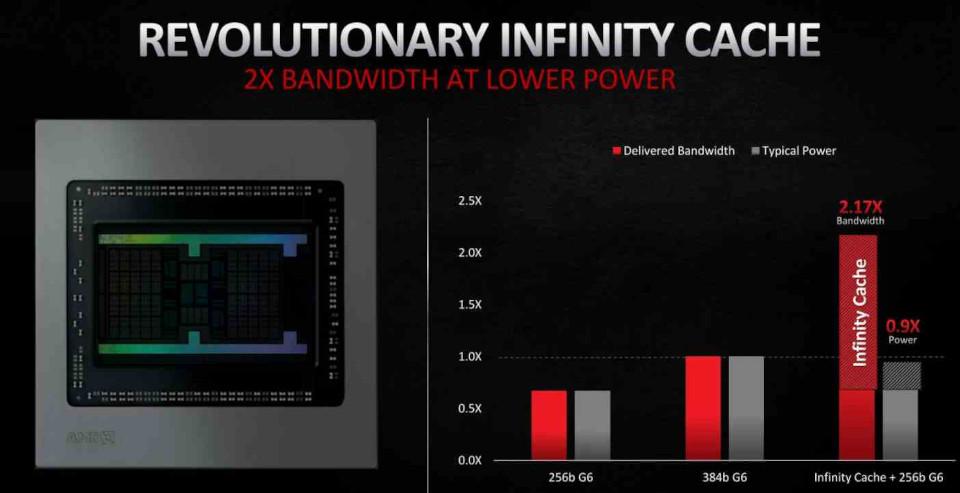
În RDNA 2, cea mai importantă incluziune a fost sub forma Cache infinit, care nu acționează ca o memorie cache L3 convențională ci ca o memorie cache pentru victime, adoptând liniile de cache aruncate de memoria cache L2, în acest fel se evită ca aceste date să cadă în VRAM, ceea ce facilitează recuperarea și, așa cum vom vedea mai târziu , reduce costul energetic al anumitor operațiuni, ceea ce îl face un element cheie pentru îmbunătățiri în RDNA 2.
Localizarea datelor este importantă în ceea ce privește consumul de energie. Deoarece cu cât este mai mare distanța pe care trebuie să o parcurgă o parte din date, cu atât este mai mare consumul de energie. Aici intervine Infinity Cache, care vă permite să operați cu datele cu un consum mult mai mic.
RDNA 2, o evoluție minoră

RDNA 2, pe de altă parte, este o versiune ușor îmbunătățită a RDNA și nu o schimbare mai puțin radicală, astfel încât AMD ar fi revenit la strategia de lansare a îmbunătățirilor continue pe aceeași arhitectură. Se spune că AMD a lansat RDNA în a doua jumătate a anului 2019 ca soluție temporară în timp ce au terminat lustruirea RDNA 2, care este versiunea deja finalizată a arhitecturii și pe deplin compatibilă cu DirectX 12 Ultimate.
Dacă vorbim în termeni de calcul, RDNA 2 nu are niciun avantaj față de RDNA și îmbunătățirile au fost făcute mai degrabă în alte elemente decât partea responsabilă de executarea umbrelor.
- Unitatea de textură a fost îmbunătățită și a fost adăugată o unitate de intersecție a razelor pentru Ray Tracing.
- ROPS și unitățile raster au fost îmbunătățite pentru a suporta umbrirea cu rată variabilă.
- GPU acceptă acum viteze de ceas mai mari.
- Includerea cache-ului Infinity pentru a reduce consumul de energie al anumitor instrucțiuni.
Una dintre cheile pentru a putea obține o viteză de ceas mai mare într-un procesor este super-segmentarea conductei, dar acest lucru nu se poate face în unitatea shader a unui GPU în același mod ca într-un Procesor. Căci ceea ce AMD a făcut intern este să măsoare consumul de energie al fiecărei instrucțiuni pe care unitatea de calcul poate să o efectueze. Deoarece există instrucțiuni care consumă mai puțină energie, acestea pot fi executate la o viteză de ceas mai mare, acest lucru permite atingerea unor viteze de vârf mai mari la momentul executării acestora.