Infinity Cache este cea mai notabilă diferență între recent introduse plăcile grafice din seria RX 6000 (RX 6800, RX 6800 XT și RX 6900) cu Xbox Seria X SoC GPU, bazat și pe RDNA 2. ¿Dar ce este mai exact Infinity Cache, la ce folosește și cum funcționează? Vă vom spune toate secretele sale.
Din săptămânile dinaintea prezentării RX 6000 am știut de existența acestui imens pool de memorie în GPU, imens pentru că vorbim despre cel mai mare cache din istoria GPU-urilor cu aproximativ Capacitate de 128 MB . Dar AMD nu a oferit prea multe informații despre aceasta, ci ne-a spus pur și simplu despre existența sa.

De aceea este necesară o explicație detaliată pentru a înțelege de ce AMD a plasat un cache de o asemenea dimensiune în versiunea RDNA 2 pentru PC.
Localizarea cache-ului Infinity

Primul punct care este necesar pentru a înțelege care este funcția unei piese în hardware este deducerea funcției sale din locația sa în sistem.
Întrucât ADNr 2 este o evoluție a ADNr , în primul rând, trebuie să aruncăm o privire asupra primei generații a arhitecturii grafice AMD actuale, dintre care cunoaștem două cipuri care sunt Navi 10 și Navi 14.
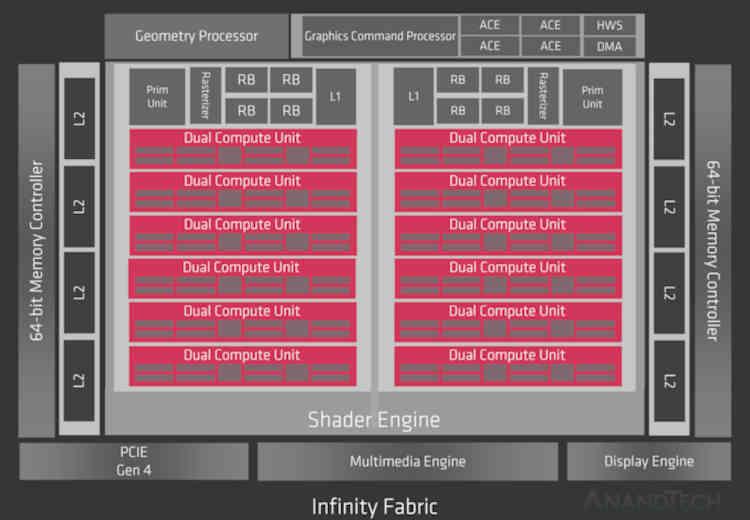
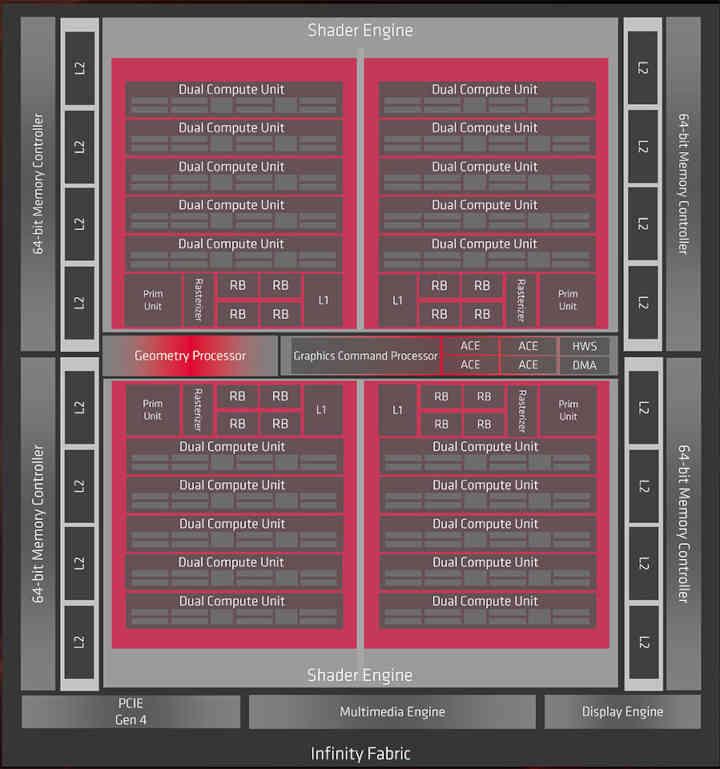
Ei bine, dacă memoria Infinity Cache ar fi fost implementată în RDNA, ar fi în partea care spune Infinity Fabric din diagramă, așa că la nivelul organizării cache am trece de la aceasta:
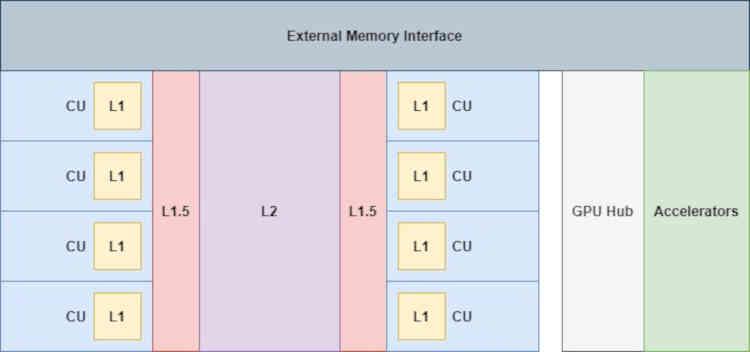
Acolo unde acceleratoarele conectate la hub-ul GPU (codecul video, controlerul de afișare, unitățile DMA etc.) nu au acces direct la cache-uri, nici măcar cache-ul L2.
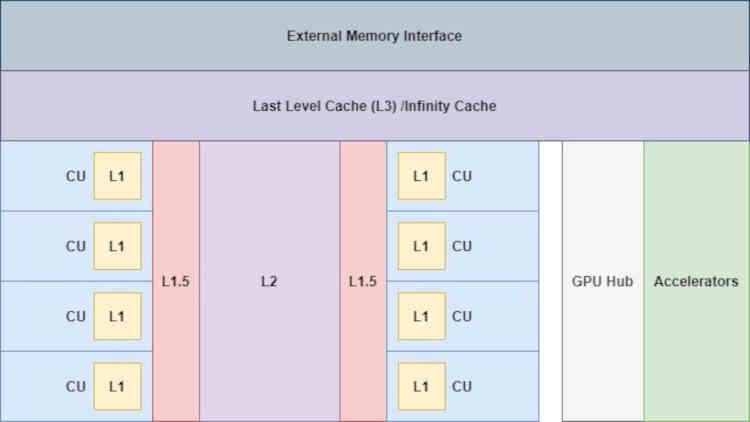
Odată cu adăugarea Infinity Cache, lucrurile se schimbă deja „puțin”, deoarece acum acceleratorii au acces la această memorie,
Acest lucru este foarte important, în special pentru Display Core Next, care este responsabil pentru citirea bufferului de imagine final și transmiterea acestuia către portul de afișare corespunzător sau interfața HDMI, astfel încât imaginea să fie afișată pe ecran, acest lucru este important pentru a reduce accesele către VRAM de către aceste unități.
Amintindu-ne de sistemul de cache RDNA

În RDNA, cache-urile sunt conectate între ele în felul următor:

Cache-ul L2 este conectat la exterior la 16 canale de câte 32 de octeți / ciclu, dacă ne uităm la diagrama Navi 10 atunci veți vedea cum are acest GPU 16 partiții L2 Cache și o magistrală GDDR256 pe 6 de biți de care sunt conectate.
Țineți cont de faptul că GDDR6 utilizează 2 canale pe cip care funcționează în paralel, fiecare cu 16 biți.
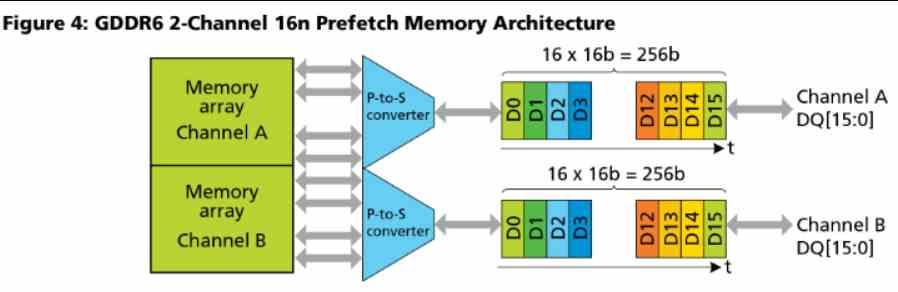
Cu alte cuvinte, numărul de partiții cache L2 în arhitecturile RDNA este egal cu numărul de canale GDDR16 pe 6 biți care sunt conectate la procesorul grafic. În RDNA și RDNA 2 fiecare partiție are 256 KB, acesta este motivul pentru care Xbox Series X care are o magistrală de 320 biți și, prin urmare, 20 de canale GDDR6 are aproximativ 5 MB de cache L2.
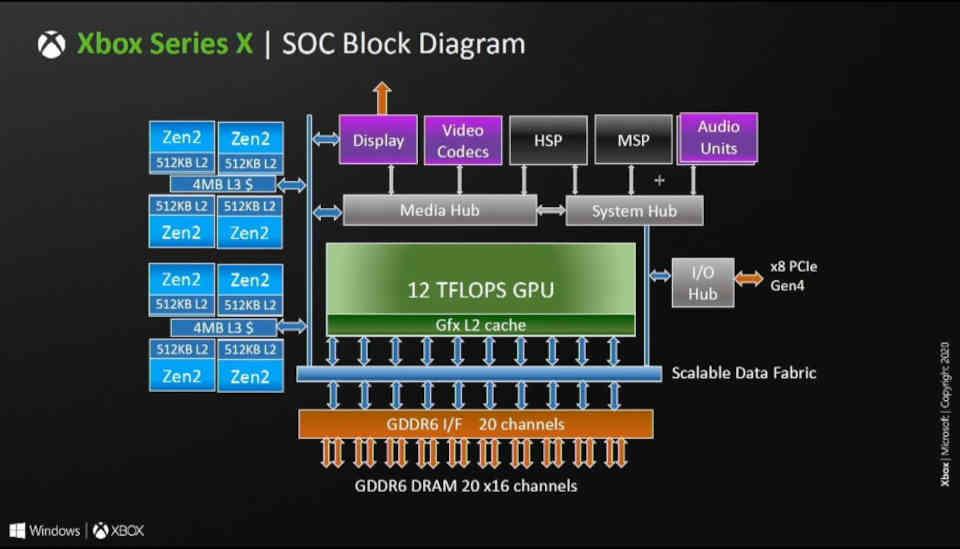
Un nou nivel de cache: cache-ul Infinity

Deoarece este un nivel suplimentar de cache, cache-ul Infinity trebuie conectat direct la cache-ul L2, care este nivelul anterior din ierarhia cache, acest lucru ne este confirmat chiar de AMD într-un subsol:
Măsurătoare calculată de inginerii AMD, pe un card din seria Radeon RX 6000 cu 128MB AMD Infinity Cache și 256-bit GDDR6. Măsurarea ratelor medii de succes AMD Infinity Cache în jocurile de 4k de 58% din titlurile de joc majore, înmulțite cu lățimea de bandă teoretică maximă a 16 canale AMB Infinity Fabric 64B conectarea cache-ului la motorul grafic la o frecvență de impuls de până la 1.94 GHz.
GPU-ul utilizat în RX 6800, RX 6800 XT și RX 6900 este Navi 21 care are o magistrală GDDR256 de 6 biți, ergo are 16 canale și, prin urmare, cele 16 partiții ale Caché L2 fiind conectate fiecare la o partiție a cache-ului Infinity.
În ceea ce privește problema „ratelor de accesare” de 58%, este mai complicată și este ceea ce vom încerca să explicăm mai jos.
Tile Caching pe GPU-uri NVIDIA

Înainte de a continua cu Infinity Cache, trebuie să înțelegem motivele existenței sale și pentru aceasta trebuie să ne uităm la evoluția GPU-urilor în ultimii ani.
Începând cu NVIDIA Maxwell, seria GeForce 900, NVIDIA a făcut o schimbare majoră în GPU-urile lor pe care le-au numit Tile Caching, a căror schimbare a implicat conectarea ROPS și a unității raster la cache-ul L2.
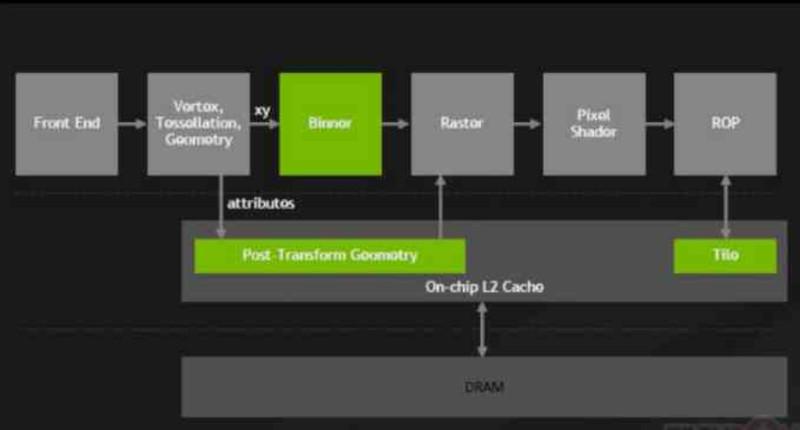
Odată cu această schimbare, ROPS a încetat să scrie în VRAM direct, ROPS-urile sunt comune în toate GPU-urile și sunt responsabile pentru crearea bufferelor de imagine în memorie.
Datorită acestei schimbări, NVIDIA a reușit să reducă impactul energetic asupra magistralei de memorie prin reducerea cantității de transferuri care au fost efectuate către și de la VRAM și, prin aceasta, NVIDIA a reușit să câștige eficiență energetică de la AMD cu arhitecturile Maxwell și Pascal.
DSBR, Tile Caching pe AMD GPU-uri
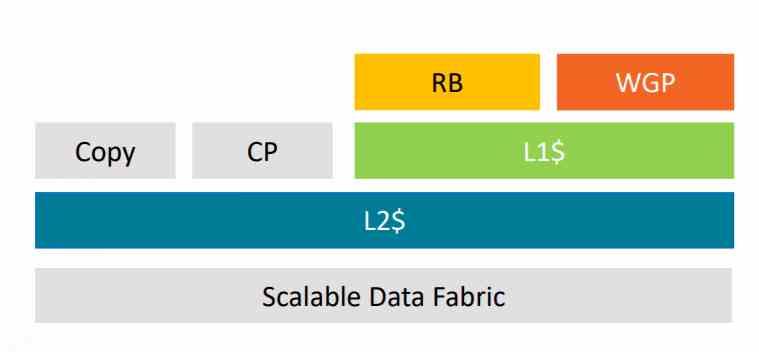
AMD, pe de altă parte, în toate generațiile de arhitectură GCN anterioare Vega, a conectat Render Backends (RB) direct la controlerul de memorie.

Dar începând cu AMD Vega, a făcut două modificări în arhitectură pentru a adăuga Tile Caching la GPU-urile sale, prima dintre ele a fost reînnoirea unității raster, pe care a redenumit-o DSBR, Draw Stream Binning Rasterizer.

A doua modificare a fost că au conectat unitatea raster și ROPS la memoria cache L2, o schimbare care există încă în RDNA și RDNA 2.
Utilitatea DSBR sau Tile Caching
Tile Caching sau DSBR este eficient, deoarece comandă geometria scenei în funcție de poziția sa pe ecran înainte de a fi rasterizată, aceasta a fost o schimbare importantă, deoarece GPU-urile înainte de implementarea acestei tehnici a comandat fragmentele deja texturate chiar înainte de a le trimite în memoria tampon.
În Tile Caching / DSBR ceea ce se face este să ordonați poligoanele scenei înainte ca acestea să fie convertite în fragmente de către unitatea de rasterizare.
În Tach Caching, poligoanele sunt ordonate în funcție de poziția ecranului în plăci, unde fiecare placă este un fragment de n * n pixeli.
Unul dintre avantajele acestui fapt este că permite eliminarea în prealabil a pixelilor nevizibili ai fragmentelor care sunt opace atunci când se află în aceeași situație. Ceva ce nu se poate face dacă elementele care alcătuiesc scena sunt ordonate după texturare.
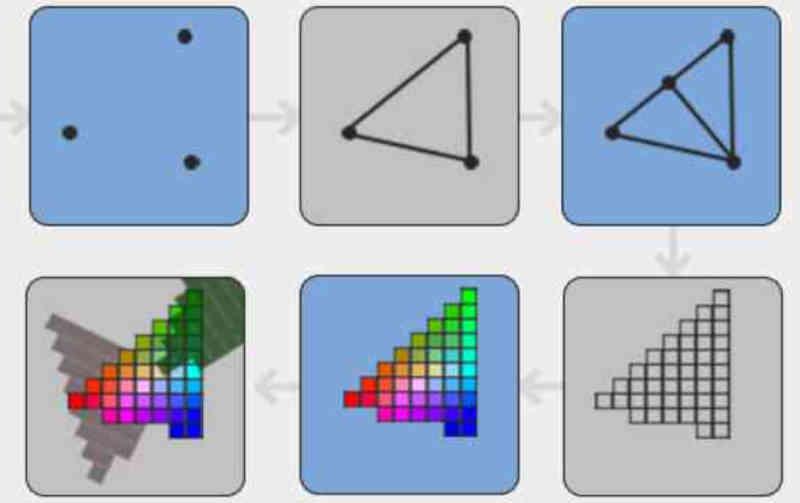
Acest lucru economisește GPU de la pierderea timpului pe pixeli inutili și îmbunătățește eficiența GPU. În cazul în care vi se pare confuz, este la fel de simplu ca să vă amintiți că pe parcursul conductei grafice diferitele primitive care alcătuiesc scena iau forme diferite în timpul diferitelor etape ale acesteia.
Tile Caching sau DSBR nu este echivalent cu Tile Rendering
Deși numele poate fi înșelător, Tile Caching nu este echivalent cu Rendering Tile din următoarele motive:
- Renderele de plăci stochează geometria scenei în memorie, o comandă și creează liste de ecran pentru fiecare placă. Acest proces nu are loc în cazul Tile Caching sau DSBR.
- În Tender Rendering, ROPS-urile sunt conectate la memorii scratchpad în afara ierarhiei cache și nu își golesc conținutul în VRAM până când acea țiglă nu a fost finalizată 100%, deci ratele de accesare sunt 100%.
- În Tile Caching / DSBR, deoarece ROPS / RBs sunt conectate la cache-ul L2, în orice moment liniile cache de la L2 la RAM pot fi eliminate, deci nu există nicio garanție că 100% din date se află în cache-ul L2.
Deoarece există o mare probabilitate ca liniile de cache să ajungă în VRAM, ceea ce AMD a făcut cu cache-ul Infinity este de a adăuga un strat de cache suplimentar care colectează datele aruncate din cache-ul L2 al GPU-ului.
Infinity Cache este o victimă
Victima Caché ideea este o moștenire de procesoare sub arhitecturi Zen care a fost adaptată la RDNA 2.
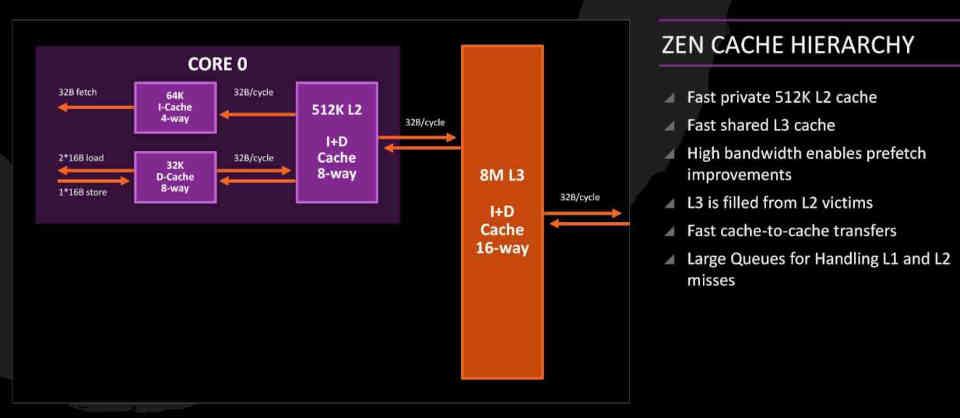

În nucleele Zen, cache-ul L3 este ceea ce numim un Victim Cache, de care sunt responsabili colectarea liniilor cache aruncate de la L2 în loc să facă parte din obișnuit cache ierarhie. Adică, în nucleele Zen datele care provin RAM nu urmează calea RAM → L3 → L2 → L1 sau invers, ci urmează calea RAM → L2 → L1, deoarece memoria cache L3 acționează ca Victim Caché.
În cazul cache-ului Infinity, ideea este să salvează liniile cache-ului L2 al GPU-ului fără a fi nevoie să accesați VRAM , ceea ce permite ca energia consumată pe instrucțiune să fie mult mai mică și, prin urmare, se pot atinge viteze mai mari. ceas.
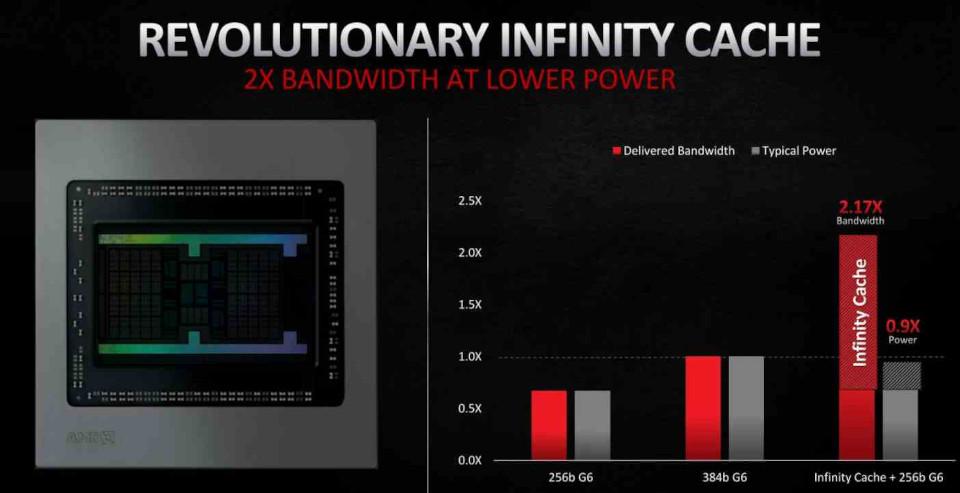
Cu toate acestea, deși capacitatea de 128 MB poate părea foarte mare, nu pare suficientă pentru a evita ca toate liniile aruncate să ajungă în VRAM, deoarece în cele mai bune cazuri reușește să salveze doar 58% . Aceasta înseamnă că în iterațiile viitoare ale arhitecturii sale RDNA este foarte probabil ca. AMD va crește capacitatea acestui cache Infinity .