RTX 3000 kom ut for noen måneder siden og erstattet RTX 2000, men hvordan sammenligner begge arkitekturer seg og hva er endringene fra generasjon til generasjon, er det et så spektakulært sprang som NVIDIA selger eller er de ganske små endringer? Vi forklarer forskjellene mellom Turing- og Ampere-arkitekturen.
Er det verdt å bytte en RTX 2000 mot en tilsvarende i RTX 3000? Fra vårt synspunkt, hvis du vil ha maksimal ytelse, ja, men samtidig mener vi at det er viktig å avmystifisere begge generasjoner av GPUer, så vi kommer til å sammenligne dem.

Hvordan er Turing og Ampere det samme i arkitektur?

Det er en rekke elementer der det ikke har vært noen endringer fra en generasjon til den neste, så det har ikke vært noen interne endringer, og de fungerer fortsatt det samme i Ampere sammenlignet med Turing.
Listen over elementer som ikke er endret åpnes av kommandoprosessorene midt i begge GPUene. Som er den delen som har ansvaret for å lese kommandolistene fra hovedtemaet RAM og organisere resten av GPU elementer. Etterfulgt av de faste funksjonsenhetene for gjengivelse via rasterisering: rasterenheter, tessellation, teksturer og ROPS.
Den interne minnestrukturen har heller ikke endret seg, det vil si cachehierarkiet som forblir det samme i Ampere og ikke har endret seg med hensyn til Turing, siden det forblir det samme i begge arkitekturer, det eneste elementet i minnehierarkiet er GDDR6X-minnet grensesnitt som brukes av GPUer basert på NVIDIA GA102-brikken, for eksempel RTX 3080.
I hvilke elementer er Turing og Ampere forskjellige

Vi må gå inn i SM-enhetene for å se endringer i Ampere-baserte RTX 3000 sammenlignet med Turing-baserte RTX 2000, og de er endringer som er gjort på tre forskjellige fronter:
- Flytende punkter i FP32
- Tensor kjerner.
- RT-kjernene.
Utenfor disse elementene og utenfor antall SM-enheter, som er høyere i GeForce Ampere enn i GeForce Turing, er det ingen endring, så NVIDIA har resirkulert en god del av maskinvaren fra forrige generasjon for å lage den nye. . Og før du trekker konklusjonen om at dette er noe negativt, la meg fortelle deg hvor vanlig innen maskinvaredesign.
Endringer i flytpunkt på GeForce Ampere SM

På alle GeForces opp til Pascal ble alle flytende punkt enheter kalt CUDA-kjerner av NVIDIA. Så uten videre, uten å avklare hva det betydde utover flytende beregninger. De antydet at de var 32-biters presisjons flytende punkt enheter.
Egentlig var CUDA-kjernene faktisk logikoaritmetiske enheter for 32-biters flytpunktsberegning, men også enheter av samme type for 32-biters heltall. Spesialiteten? De opererte byttet, på en slik måte at begge typer ikke kunne fungere samtidig.

Da Turing forandret seg ting og det som kalles samtidig kjøring dukket opp, er årsaken at GPU-tråden lister opp kombinerte tråder med heltall og flytende punkt og ikke nådde den maksimale spor okkupasjonen av SIMT-enheten med hver underolje, så NVIDIA bestemte seg for Turing å bruke samtidig kjøring. I hvilken en bølge av 32 utførelsestråder kan utføres på en kombinert måte mellom heltall og flytende ALU-er samtidig, så lenge disse er tilgjengelige.
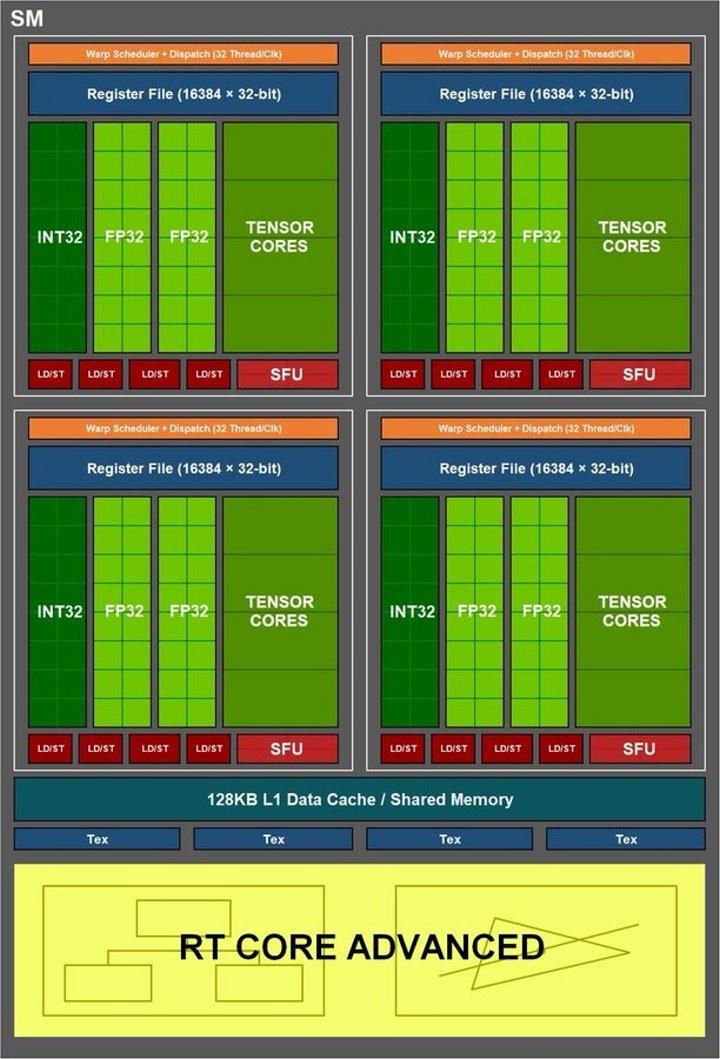
Dette betyr at 32-bølgedrådfordelingen, som er standardstørrelsen for NVIDIA GPUer, kan fordeles på opptil 16 heltallstråder og 16 flytende tråder. Men noen hos NVIDIA kom med å foreslå en endring for Ampere, som er at settet med heltall ALU er byttet med et andre sett med flytende punkt ALUer, som ikke krever endring av resten av SM.
Derfor blir beregningshastigheten, målt i TFLOPS, doblet på bestemte tidspunkter og når tilstanden at en 32-tråds flytpunktsbølge kommer inn. Selv om bare når de er oppfylt under disse forholdene, og hvis vi hadde en enhet for å måle TFLOPS-hastigheten, ville vi se at det ikke er den som NVIDIA sier, som gir maksimal topp i spesifikasjonene, men at den vil ha svingninger.
Tensorkerner på GeForce Ampere

Tensor Cores er systoliske arrays som først ble utgitt på NVIDIA Volta GPUer, og de er systoliske arrays som er den typen utførelsesenhet som brukes til å øke hastigheten på AI-baserte algoritmer. Disse enhetene bruker, i motsetning til RT-kjernene, kontrollenheten til SM og kan ikke brukes samtidig med flytpunktet og heltallsenhetene, så selv om de kan fungere samtidig, gjør de det ved å fjerne strøm fra resten. enheter unntatt RT-kjerner.
Hvis vi legger til ALU-mengden som RT-kjernene danner mellom en generasjon og den andre, vil vi se at det er samme mengde, men med en annen konfigurasjon. I Turing har vi 8 enheter, 2 per underkjerner, på 64 ALUer hver i en Tensor 4 x 4 x 4-konfigurasjon. Mens de er i Ampere har Tensor Cores en konfigurasjon på 4 enheter, 1 per underkjerne, med 128 ALUer. for hver av dem.
RT-kjerner på GeForce Ampere
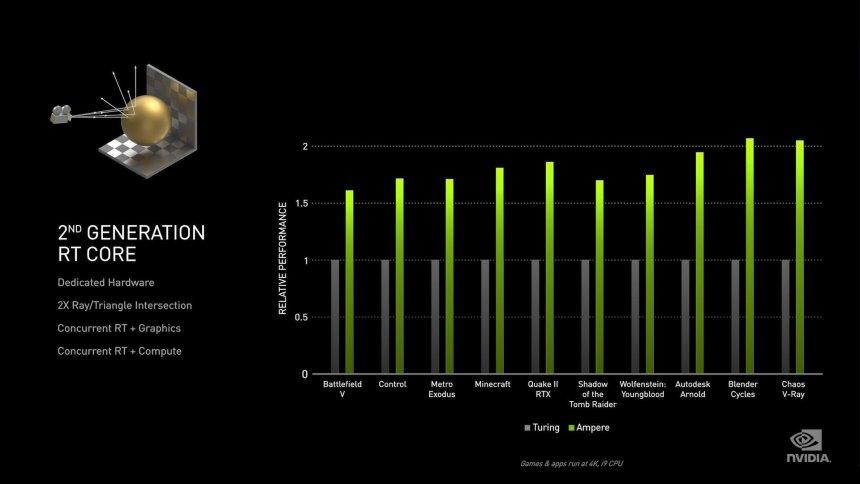
RT-kjernene er den minst kjente delen av alle, siden NVIDIA ikke har gitt noen informasjon om hva deres interne arbeid er. Vi vet hva det gjør, hvordan det fungerer, men vi vet ikke hva elementene er inni og hvilke endringer som har skjedd fra en generasjon til en annen.
Det første som skiller seg ut er omtale av NVIDIA at RT Cores nå kan gjøre dobbelt så mange kryss per trekant, noe som ikke betyr dobbelt så mange kryss per sekund. Årsaken til dette er at når du krysser BVH-treet, er det å gjøre skjæringspunktet mellom boksene som er de forskjellige nodene i treet, og bare det endelige skjæringspunktet til treet er det som er laget med trekanten, som er det mest komplekse å utføre. Enhetene for beregning av skjæringspunktet mellom boksene er mye enklere, i Turing har vi i teorien fire enheter som fungerer parallelt for å gå gjennom de forskjellige nivåene i et tre og en enkelt enhet som utfører skjæringspunktet mellom strålen og trekanten.
Den andre endringen på maskinvarenivå er muligheten til å interpolere trekanten i henhold til dens posisjon i tid, noe som er nøkkelen til implementeringen av Ray Tracing with Motion Blur, en teknikk som fremdeles er uten sidestykke i spill som er kompatible med Ray Tracing. I tilfelle det er andre endringer, har NVIDIA ikke offentlig rapportert dette, og vi kan derfor ikke trekke ytterligere konklusjoner.
