If you have observed the different diagrams of different architectures, then you will have seen how in all of them the cache closest to the processor, usually called the first level cache or L1, is divided into two different types of memory called data cache and instruction cache . What is the reason for this? Keep reading and you will understand why it is a common practice in all designs
The first cache to be implemented was the first-level cache, which since its inception has always been divided into two wells, if you have ever wondered why it is, keep reading and you will understand it without any problem.

What is the L1 or top-level cache?
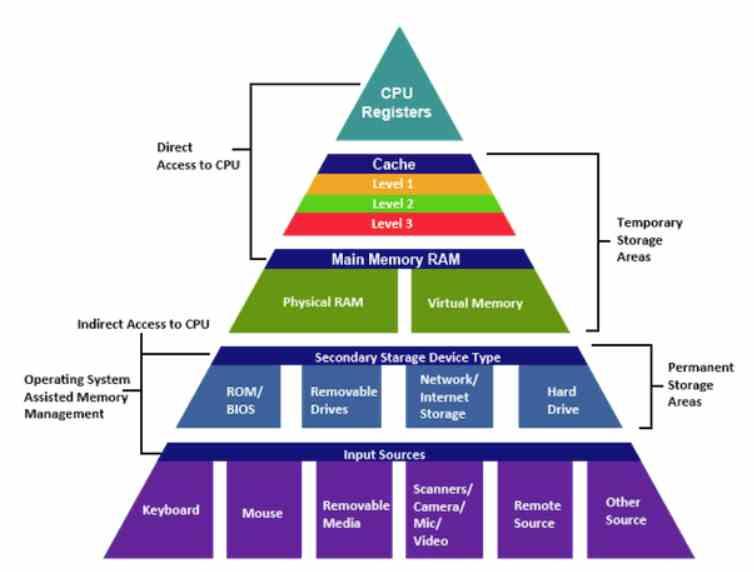
The L1 cache or first-level cache is the closest to the CPU and GPU cores, making it the type of cache with the highest bandwidth and lowest latency of the entire cache hierarchy. It is the first in which when looking for data in any type of processor, the memory hierarchy system will look to find the data.
It must be remembered that the cache does not work as part of the RAM but copies the data from the RAM close to what the processor is at that moment. A CPU runs through the memory sequentially through the different memory addresses, so to increase performance when capturing data, a cache memory is used.
L1 cache is always separate
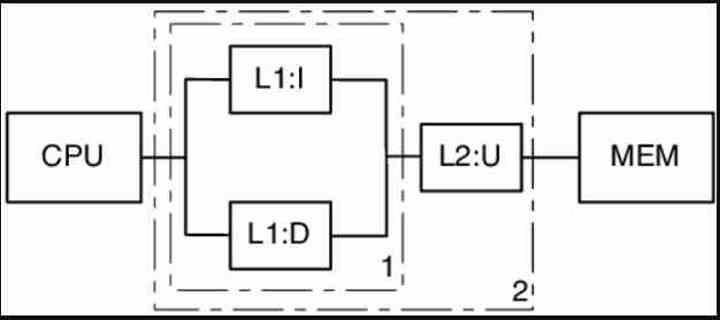
The L1 cache in all processors is divided into two different wells, a data cache and an instruction cache. What does this mean? It is simple, first we have to understand that all CPUs and GPUs use a Von Neumann architrave where the instructions that are what the processor has to do, and the data that is what the instruction has to manipulate, are found in the same memory. .
This means that the instructions have a form in which x bits of the code that form an instruction, the first bits correspond to the opcode that indicate the action to be done by the processor, bits that come next correspond to how to do it the instruction and the latter refer to the data. Either where the data is or is in itself, although there are instructions that lack the data bits and others lack the mode bits.
The data goes from the RAM to the different levels of cache, where data and instructions are kept together until the L2 Cache, from which there is a mechanism that copies the first part of the instruction, the opcode and the mode, in the cache of instructions and the other part in the Memory Access Register, in which the bits that point to the memory address are placed. Today this last part is a bit more complex, but for didactic reasons we are going to leave it at that.
What is the reason for the cache separation?

The reason for this is that internally what is the information of the opcode of the instruction is treated differently from the rest. The opcode is dealt with by the processor’s instruction decoder. In fact, in all processors the first part of the instruction is handled first and the reason for this is very simple. There are instructions that do not point to a memory address but rather include the data to operate and therefore it is not necessary for the data to be copied into the memory access register, but rather to be copied into a special register.
When you need to search for data in RAM in a system with a first-level cache, once the processor has verified that the opcode corresponds to an instruction that points to a data in a part of memory, then that address is copied into the MAR, the RAM will return the data in the MDR register, Memory Data Register, and the corresponding mechanisms will copy the data in the corresponding register, normally the accumulator register, which is the one used for arithmetic operations.
The entire process of decoding the instructions and searching for data occurs in parallel, with several accesses to the L1 cache that, if done under the same memory well, would end up creating a huge contention when accessing. In other words, the L1 cache was key to increasing the performance of the processors, with the 80486 being the first PC processor to implement it. In GPUs, first-level caches began to be implemented with the arrival of shader units in them.