SWARの概念は多くの人にとって奇妙に思えますが、CPUのSIMDユニット、システムのGPUはほとんどSWARタイプであると言えばどうなるでしょうか。 これらのタイプのユニットは、従来のSIMDユニットとは異なり、90年代後半のマルチメディア拡張に端を発しています。 それらは何であり、今日それらの用途は何ですか?
プロセッサのパフォーマンスは、XNUMXつの方法で測定できます。XNUMXつは、命令を直列に実行する速度であり、ユニットデータにのみ影響するため、並列化することはできません。 一方、複数のデータを処理し、並列化できるもの。 CPUとGPUでそれを行う従来の方法は? CPUやGPUで頻繁に使用されるサブタイプであるSIMDユニットであるSWARユニット。

ALUとその複雑さ
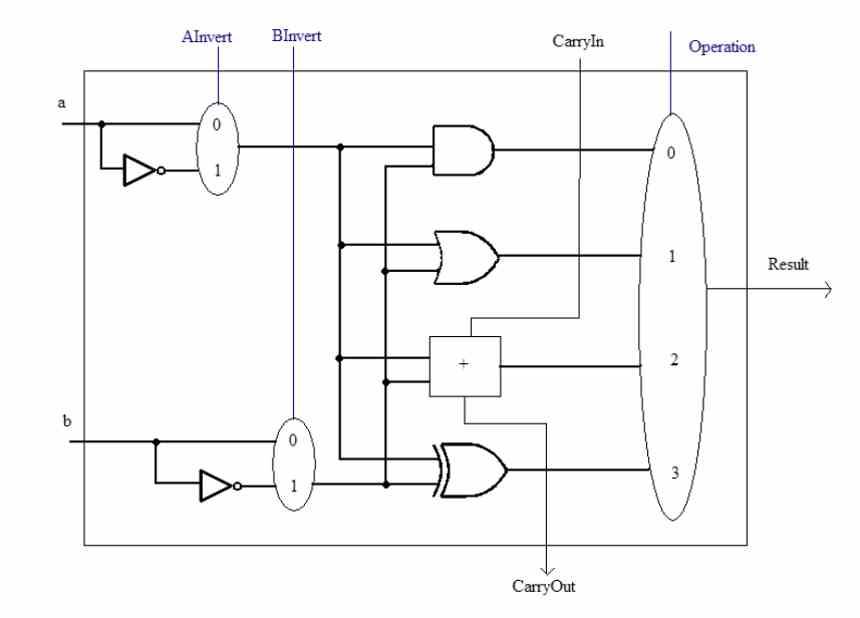
SWARの概念について説明する前に、ALUは CPU 異なる数値で算術計算と論理計算を実行する責任があります。 これらはXNUMXつの方法で複雑さを増す可能性があります。XNUMXつは実行する必要のある命令の複雑さです。 たとえば、平方根の計算を実行できるALUの内部回路は、単純な合計の計算と同じではありません。
もう32つは、それらが機能する精度、つまり、毎回同時に操作するビット数です。 ALUは、設計されているビット数以下のデータを常に処理できます。 たとえば、16ビットの数値をXNUMXビットのALUで計算することはできませんが、その逆は可能です。
しかし、精度の低いデータがいくつかあるとどうなりますか? 通常、それらは完全な精度と同じ速度で実行されますが、それらを高速化する方法があり、それがオーバーレジスタSIMDです。 これは、プロセッサ内のトランジスタを節約する方法でもあります。
SWARの概念は何ですか?
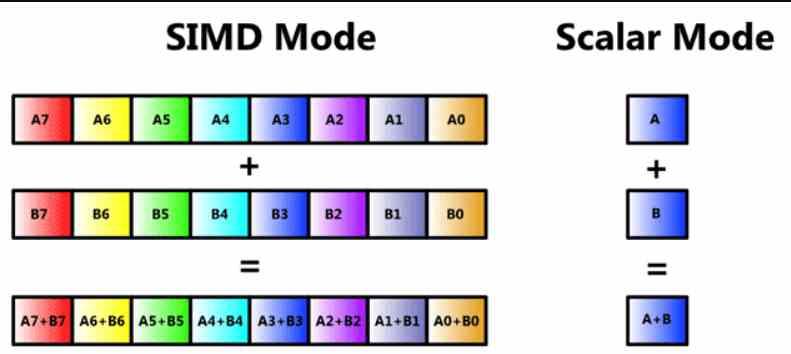
今では多くの読者がSIMDユニットであることを知っているでしょうが、最初からこの記事のスレッドを失うことがないようにレビューします。 SIMDユニットはALUの一種であり、複数のデータがXNUMXつの命令で同時に操作されるため、命令自体とそのデコードの集水域部分を共有するALUがいくつかありますが、それぞれが異なる場所です。情報の一部が扱われます。
SIMDユニットは通常複数のALUで構成されていますが、ALUが単純なものに細分化されている場合や、データを一時的に保存して計算する累積レジスターがある場合もあります。 これは、レジストリ上のSIMDまたは英語のSWARの頭字語で呼ばれます。これは、レジスタ内のSIMDまたはレジストリ上のSIMDを意味します。
このタイプのSIMDユニットは非常に使用されており、高精度のnビットALUで同じ命令を実行できますが、データの使用精度は低くなります。 通常、半分または64分の32の精度で。 たとえば、上記の命令を並列に実行することにより、16ビットALUをXNUMXつのXNUMXビットALUとして機能させることも、XNUMXつのXNUMXビットALUとして機能させることもできます。
SWARの概念を深く掘り下げますか?
この概念はすでに数十年前のものですが、PCに初めて登場したのは、90年代後半で、存在していたさまざまなタイプのプロセッサにSIMDユニットが登場しました。 その場所のベテランはMMXのような概念を覚えているでしょう、 AMD 3D Now!、SSEなどはSWARコンセプトで構築されたSIMDユニットでした。
128ビットのSIMDユニットを構築したいとします
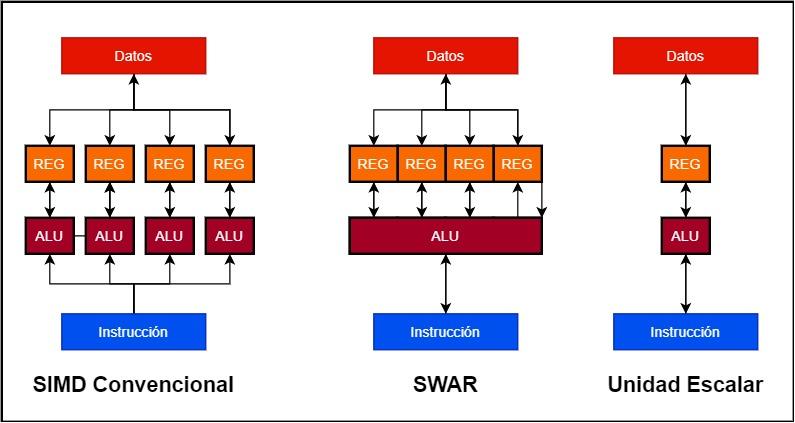
- 従来のSIMDユニットでは、複数のALUが並行して動作し、それぞれに独自のデータレジスタまたはアキュムレータがあります。 したがって、128ビットSIMDユニットは、4つの32ビットALUと4つの32ビットレジスタで構成できます。
- 代わりに、SWARユニットは、アキュムレータレジスタと同様に非常に高精度で動作できる単一のALUです。 これにより、SWARをサポートする単一の128ビットALUを使用してSIMDユニットを構築できます。
SWARタイプのユニットの実装がスカラーユニットよりも優れている点は簡単に理解できます。ALUに、精度の低いデータでSIMDユニットとして動作できるSWARメカニズムが含まれていない場合、それらは同時に実行されます。速度。 最高精度のデータより。 これは何を意味するのでしょうか? SWARをサポートしない32ビットユニットは、16ビットデータに対して同じ命令を操作する必要がある場合、32ビットユニットと同じ速度で操作します。 一方、ALUがSWARをサポートしている場合、両方が連続して発生した場合、同じサイクルで16つのXNUMXビット命令を実行できます。
AIのパッチとしてのSWAR

人工知能アルゴリズムには特殊性があり、非常に低精度のデータで動作する傾向があり、今日、ほとんどのALUは32ビット精度で動作します。 これは、これらのアルゴリズムを高速化するために、プロセッサに高精度の16ビット、8ビット、さらには4ビットのALUを追加することを意味します。 これはプロセッサを複雑にすることですが、エンジニアはそのエラーに陥らず、特にGPUで、特定の方法でSIMDオーバーレジスタをプルし始めました。
従来のALUSIMDとSWAR設計を組み合わせることは可能ですか? そうですね。これは、たとえば、AMDがGPUで行っていることです。RDNAGPUのSIMDユニットを構成する32ビットALUはそれぞれSIMDオーバーレジスタをサポートしているため、16つの4ビットに分割できます8。 8ビットの4またはXNUMXビットのXNUMX。
の場合には NVIDIA、彼らはAIのアルゴリズムをTensor Coreに加速する負担を与えました。これらは、16軸マトリックスで相互接続された8ビット浮動小数点ALUで構成されるシストリックアレイであるため、ユニット名になります。 テンソル。 これらはSIMDユニットではありませんが、各ALUは、4ビット精度でXNUMX倍、XNUMXビット精度でXNUMX回の操作を実行できるため、SIMDオーバーレジスタをサポートしています。 いずれにせよ、テンソルユニットは、SIMDユニットよりもはるかに高速で行列間演算を加速するように設計されているため、重要です。
