最近話題になっているトピックのXNUMXつは、 AMD RX6000と比較して NVIDIA レイトレーシングの観点から見たRTX3000では、緑色のロゴのある会社は、直接のライバルに対してトレーシングレイを使用する場合にパフォーマンス上の利点があるようです。 しかし、すでに知られている理由以外に別の理由がありますか?
レイトレーシングは、グラフィックスの面で技術革新の2000つになりました。特に、RTX 6000ファミリのNVIDIAがハードウェアを追加して、いわゆるリアルタイムレイトレーシングを高速化したためです。この傾向は、最近AMDにRX3000シリーズで加わりました。そして再びNVIDIAとそのRTXXNUMX。

しかし、レイトレーシングに関しては、NVIDIA RTX3000とAMDRadeon RX 6000の間でさえも同等ではありません。これは、NVIDIA GPUのコアを備えたFP32のALUの数が多いことで説明できますが、それは話の一部にすぎません。
AMD RX 6000のレイトレーシングの問題は何ですか?
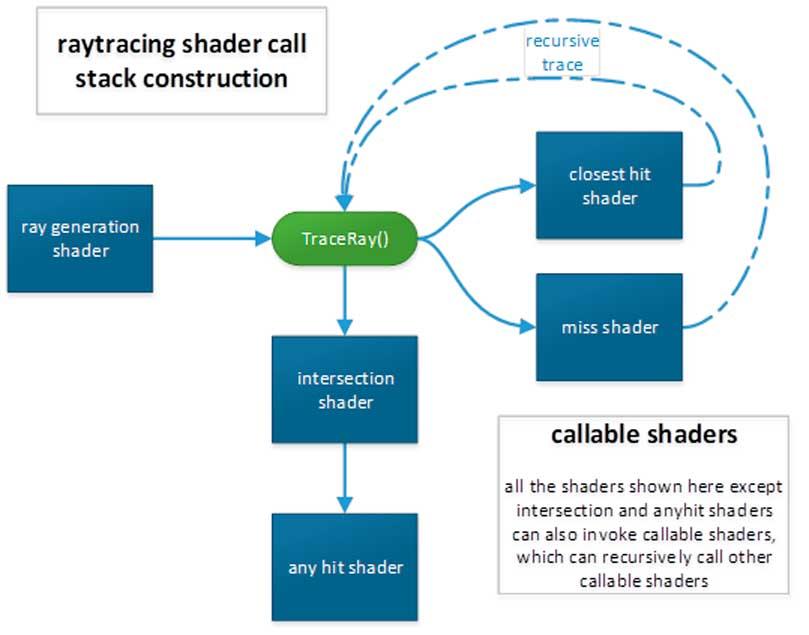
レイトレーシングを加速するための重要なポイントのXNUMXつ 加速度データ構造の使用です 、彼らが行うことは、シーン内のオブジェクトの位置のマップを保存することです。
それらはどれくらい役に立ちますか? シンプルで、レイトレーシングでは、光線が発射されてシーンの何もない部分に向けてテストされるのを防ぐため、時間を大幅に節約できるため、加速構造と呼ばれ、単一のタイプではなく、いくつかの異なるタイプがあります。もの。
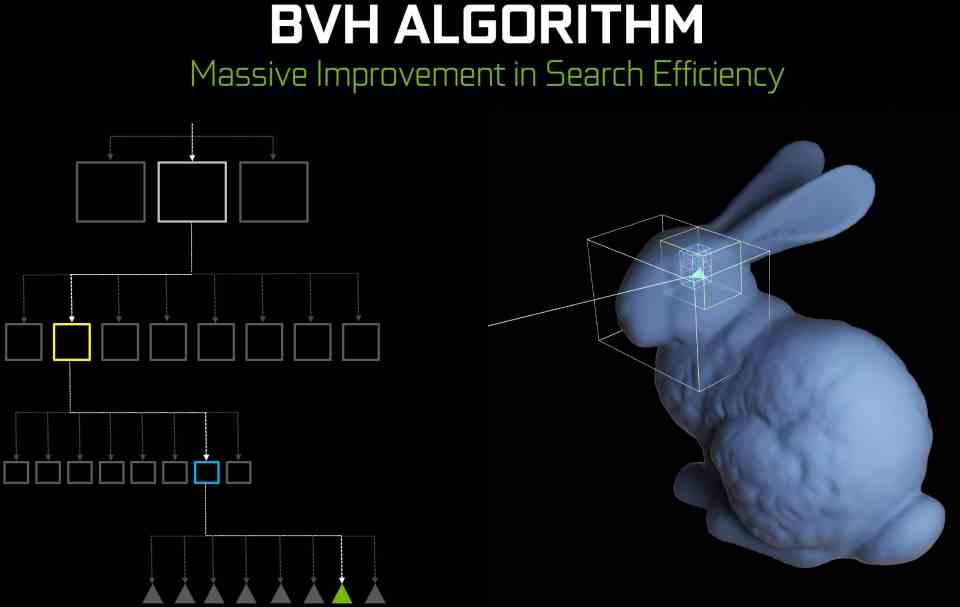
NVIDIAの場合、RTコアに、ある種のデータ構造であるBVHツリーをトラバースできるユニットを追加することにしました。これは、ゲームでレイトレーシングを行うときにこのデータ構造を使用する場合、を呼び出す必要がないことを意味します。ウォークスルーを実行するための計算シェーダープログラム。
しかし、AMDの場合、どのタイプの加速構造も優先しないことを決定しました。つまり、八分木などの古典的なツリーデータ構造を使用する場合は、計算シェーダープログラムによってパスを制御する必要があります。 、BVH、KDツリーなど。
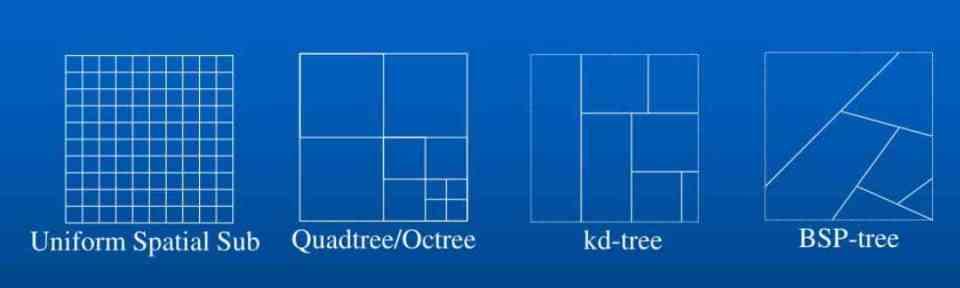
木とは何かの簡単な説明

コンピューティングでは、ツリーは順序付けられてリストされたデータ構造ではなく、階層的です。つまり、ツリーをトラバースする場合、プロセッサは数回の反復を行う必要があります。
- ツリーが始まるノードはルートと呼ばれます。
- その下にXNUMXつ以上のノードがあるノードは、親と呼ばれます。
- 階層内でその上にノードがあるすべてのノードは、子と呼ばれます。
- 階層の最後にあるすべてのノードはリーフと呼ばれます。
ツリーは、条件が発生したときにXNUMX行または別の行にジャンプすることに基づくコード内の条件付きジャンプと混同しないでください。ツリーは、複数のノードがある場合、反復ごとにいくつかの異なる実行スレッドによってフォーカスされることが最善であると想定します。 。
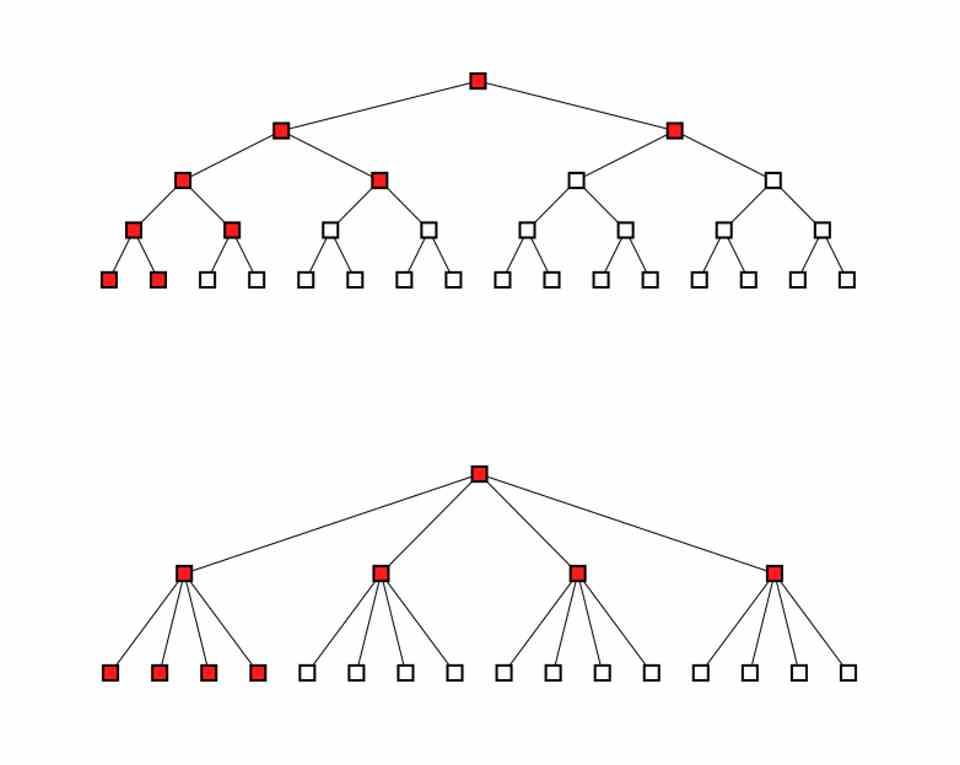
最新のGPUには通常、4つのSIMD ALUで構成されるシェーダーユニットがあり、それぞれが実行スレッドを実行するため、最大4つのノードでツリーを問題なく実行できます。もちろん、ノードの移動を開始すると、さらに多くのノードが実行されます。サブノードが増えるため、実行されるスレッドの数が非常に多くなります。
そのため、NVIDIAはRTコアでBVHツリーのトラバースに特化したハードウェアを追加して、シェーダーユニットを使用する必要がないようにしました。ただし、このユニットはそのタイプのデータ構造でのみ機能しますが、その代わりに、データの構造を非常にトラバースできます。早く。
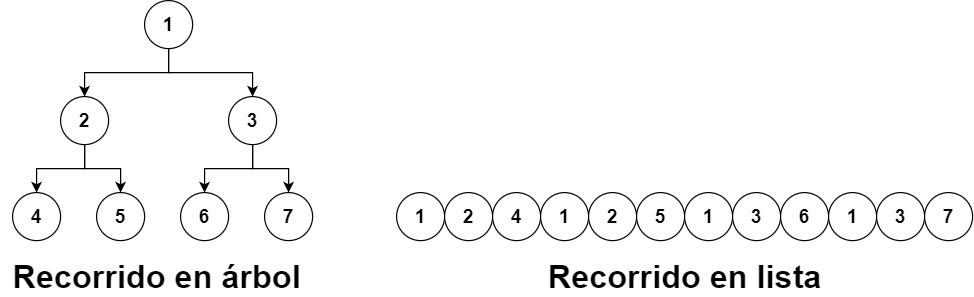
ただし、ノードのデータを表示する方法があり、さまざまなルートを一列に表示する方法があります。これにより、1DテクスチャであるXNUMX次元配列でデータを送信できます。 AMDGPUにデータを送信するための最良の方法。
AMD側の解決策は、開発者が加速構造をテクスチャの形で提示することを忘れることです。もちろん、これは、特定のタイプのツリー構造をトラバースするための特殊なハードウェアを追加しないという決定に基づいています。より高速にするのではなく、より多様性を高めることができます。
つまり、現時点では、開発者はレイトレーシングを実装する際にグラフィックカードのブランドごとに特別な対策を講じる必要があります。
不一致はどこから来るのですか?

AMDがデータ構造をトラバースするためのハードウェアを含めないことを決定した理由を不思議に思う人もいるかもしれません。これは非常に単純で、DirectXレイトレーシングの最小仕様の一部ではありません。
さらに、DXRでは、交差ユニットを交差シェーダーを実行するシェーダーユニットに置き換えることでレイトレーシングを実行できますが、AMDとNVIDIAに含まれている特殊な交差ユニットは、作業を数倍速く実行するため、はるかに効率的です。比較の部分。
私たちが言及しているのは Microsoft APIを作成するとき、ハードウェアがテーブルの下で機能する方法がありませんでした。これにより、AMDは、ツリー内のデータ構造をナビゲートするための専用ハードウェアを省くことができ、グラフィックカードのパフォーマンスに影響を与えました。

AMDレイトレーシングの特許は、4ノードツリーをトラバースできるユニットBVH-4を含めることについて述べていますが、オプションであり、最近公開されたISA RDNA2から取得できる情報のために樹木を横断することを担当するユニットへの言及はなく、交差点の指示のみへの言及。