RTX 40の光と影は、すべての人、または少なくともほとんどすべての人を驚かせる可能性があります。 新しいGPUの帯域幅が以前のバージョンの要件を満たしていないときに、ブランドとメーカーがPCIe 5.0を真っ先に立ち上げるのは早すぎると言ったとき、私たちはそれを予想していました。それで。 そしてそれは RTX 40 ニュースが彼らの中にある可能性があるPCIe4.0のみをサポートします 色.
インテルのAlderLakeによるサポート PCIe 5.0 現時点では単なる証言であり、それをサポートする製品は市場に出回っていません。 多くの人が新しいRTX40でこれが変わると考えていましたが、実際には、Huangの計画は大きく異なるため、このバージョンのバスで主導的な役割を果たすのは2023年にすでにSSDになるでしょう。

NVIDIA RTX 40 – PCIe 4.0のみ、ただしPCIeGen5コネクタ付き
インテルが新しいDDR5およびPCIe5.0の意味で最も革新的な企業としての地位を確立するのは、単なる蜃気楼であり、同時にその死を迎えています。 思い出は屋根越しにあり、どちらもそうではないようです AMD また NVIDIA すべての中で最も切望されたバスでそれに追いつくつもりです。
Ryzen7000はこのセクションのCore12に追いつきますが、グラフィックは緑色のものから始めて、より保守的になるようです。
PCIe Gen4
— kopite7kimi(@ kopite7kimi) 2022 年 4 月 24 日
そして、今日の最高のリーカーの40つによると、RTX4.0はPCIe5.0であり、XNUMXではありません。
これは、利用可能な帯域幅が各チャネルで128 GB/sまたは64GB/ sから、この速度の半分になることを意味します。 64 GB/sおよび32GB/s双方向 。 しかし、これは今後の予定を垣間見るだけであり、スロットとPCIe4.0のPCIeXNUMXの不一致にもかかわらず、そのように私たちを驚かせるべきではありません。 最大5ワットのGen600コネクタ 、この場合に言えるスクリプトのニーズ。
RTX40のXNUMXつのNVIDIAパス
最も重要なことは、このリーク自体ではありませんが、AD102チップ(および残りの部分も理解しています)は、FP32のシェーダーの数を増やすほど単純なものとして先入観がなかったと説明されています。
言い換えれば、NVIDIAがその袖に多くの驚きを持っている可能性への扉は開いたままですが、どのような意味で? さて、ここから、XNUMXつの異なるオプションに移行するという最も純粋な憶測が始まり、後で正しいかどうかを確認します。
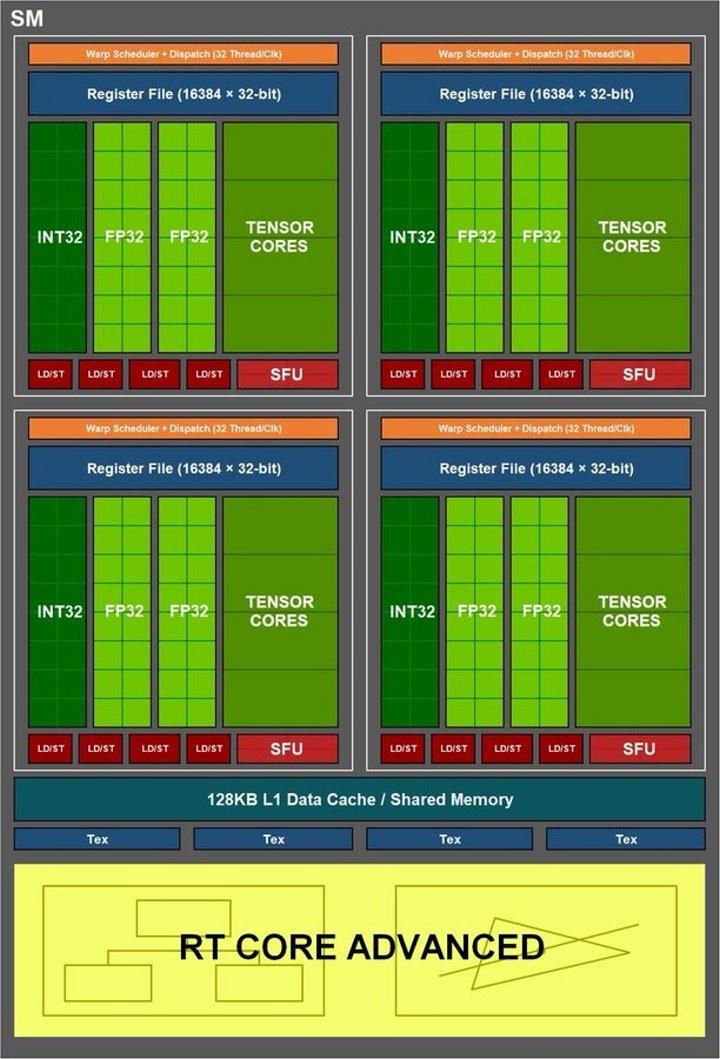
32つ目は、SMの世代交代、RTコアやテンソルコアなどの32つ以上の下位ユニットの変更を示す可能性のある実質的な変更として定義できます。 XNUMXつ目は、FPXNUMXエンジンを完全に変更することで、おそらくFPXNUMXの数を増やし、それによってシェーダーの総数を変更する可能性があります。
最後に、XNUMX番目のエンジンに次のような変更を加えます。 FP32およびINT32 。 これを説明すると、NVIDIAが最も興味深いので、どこに行くことができるかがわかります。 Ampere SMが発表されたとき、NVIDIAはそれをXNUMXつのメインエンジンとRTコアにグラフィカルにバイアスしました。これらはレンダリング内で独立していますが、実際にはレイトレーシング作業パイプラインでピクセルとFPSの結果を完全に表示することはできません。レイトレーシングと 混合BVHツリー 個人ではありません。
注意、私はSMの詳細について決して話しませんでした。
AD102には単純な18432-FP32があると先入観しないでください。— kopite7kimi(@ kopite7kimi) 2022 年 4 月 22 日
ここに、さまざまな方法で焦点を当てた4つの引数を入力します。 SMの新しいグラフィックには、XNUMXつの独立したエンジンが表示されていませんが、XNUMXつが表示されています。 A FP32およびINT32の統合エンジン 別 純粋なFP32 と テンソルコア AIの場合は、さらに分離します RTコア これまで説明したように、これは個別に機能します。
SMの再統一
NVIDIAがSMを再構築した場合はどうなりますか? つまり、FP32と整数を統合して、噂の総数を増やすことができます。 18,432シェーダー (現在、非常に空中にあります)そして、キャッシュの想定される変更を考慮して、より近いエンジンとしてRTコアおよびTensorコアでそれを使用することで統合が残す理論的なスペース。
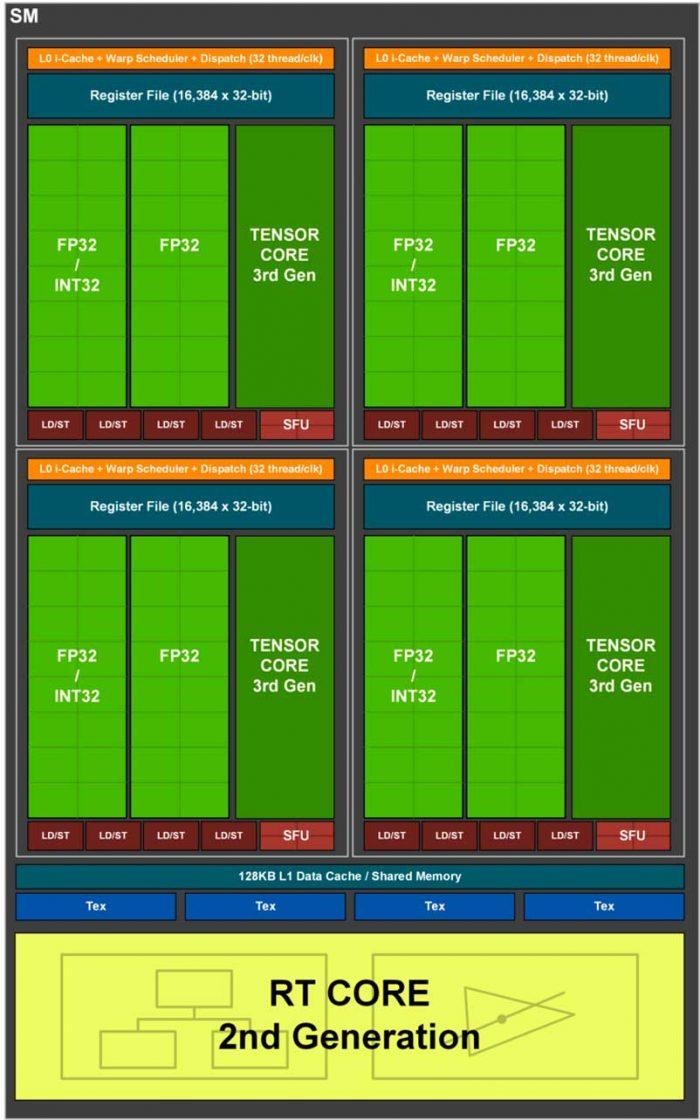
これは、レイトレーシングの驚くべき改善を意味し、求められている純粋なレンダリングに近づきますが、同時に、TMUおよび場合によってはROPに実際に影響を与えるSMの非常に重大な変更を意味します。数はそれほど多くありません。 、しかし構造、階層、そしてもちろんそのパフォーマンス。 NVIDIAがどのように密閉されているかを考えると、このトピックに焦点を合わせているかどうかを確認するには、プレゼンテーションまでほぼ待つ必要があります。