
私たちはしばしば関連付けません インテル GPUまたはグラフィックチップを搭載したブランド。これは、Intelがこれまでのところパフォーマンスの低いセグメントにとどまっているためです。 プロセッサ内に統合されたGPUと、高電力を必要としないエントリーレベルのGPUが含まれています。 つまり、多くの人にとって、それはと同じレベルの関心を持っていないということです NVIDIA & AMD GPUですが、Intelのグラフィックアーキテクチャにも興味深い点があります。これについては以下で定義します。
インテルはGPUに関しては常にXNUMX番目の論争でした。結局のところ、インテルは彼らの主な事業ではなく、CPUということ以上のものです。 近年、彼らはリソースを増やし、開始ランプに一連のゲーム用GPUを持っていますが。 ただし、そのアーキテクチャには、競合に関して一連の差別化ポイントがあります。
IntelGPUの基盤である実行ユニット
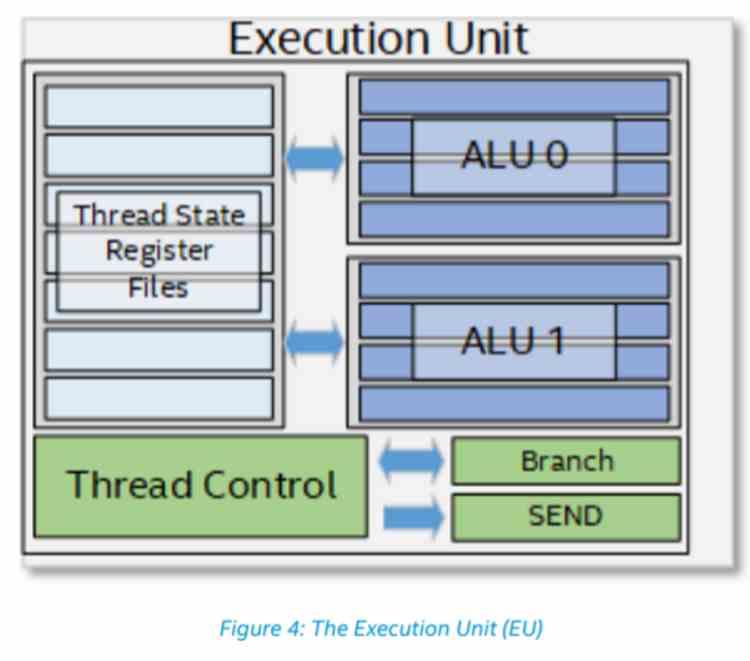
Intel GPUの組織またはアーキテクチャが他のGPUと比較して異なることを理解するには、NVIDIAまたはAMDを使用しているときにそれを理解する必要があります。 GPU シェーダーユニットは最小ユニットであり、Intelの場合は実行ユニットです。 それは正確には何で構成されていますか? 各実行ユニットは、実行スレッドまたは完全なTLPのレベルでの並列処理のために考案されたプロセッサです。 したがって、制御ユニット、レコード、および対応する実行ユニットがあります。 これは、4つの32ビット浮動小数点ALUの4つのSIMDユニットと、切り替えられてSIMDオーバーレジスタをサポートする別のXNUMXつの整数です。
レジスタ上のSIMDのおかげで、ALUとそれに関連するレジスタを細分化することにより、ALUは、正確に細分化されるたびに、クロックサイクルごとに16倍のオペランド数で動作できます。 したがって、32ビットの8倍のXNUMXビット浮動小数点演算を実行できますが、XNUMXビットの場合はXNUMX倍多く実行できます。 実行ユニットの機能に関しては、シェーダープログラムの実行を担当します。結局、IntelおよびAMD GPUのSIMDユニットと同等であるため、タスクは同じです。

Intel Xeでは、XNUMXつの実行ユニットが同じコントロールユニットを共有するようになったため、RajaKoduriチームがコントロールユニットに重要な変更を加えました。 XNUMXつのコンピューティングユニットがXNUMXつのワークグループにグループ化されているRDNAアーキテクチャでAMDが行った変更を非常に彷彿とさせる変更。 AMDからIntelへの頭脳流出によって私たちを驚かせるべきではない何か。 この変更は、コントロールユニットが更新されたことを意味します。これは、IntelGPUの内部ISAが完全に変更されてはるかに効率的なものになったことを意味します。
サブスライス、シェーダーユニット
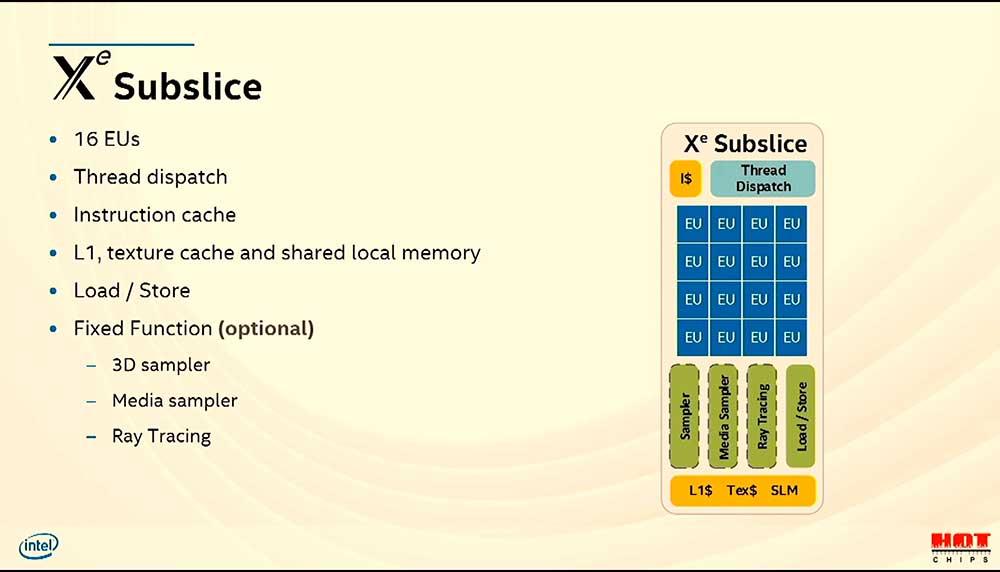
NVIDIAおよびAMDGPUが持つシェーダーユニットと同等であり、実行ユニットではなく、サブスライスであることはすでに見てきました。 それらの中に、グループ化された実行ユニットがあります。 各実行ユニットはサブスライスのサブセットであり、スライスはサブスライスのスーパーセットであるため、後者については後で説明します。 各サブスライスには16個の実行ユニットが内蔵されており、合計で64個のFP32ALUと64個の整数ALUに変換されます。 これらのユニットを、AMDの同等のコンピューティングユニットと生のコンピューティングパワーで同等にする図。
サブライス内にある残りの要素については、Intelは通常とは異なる命名法を使用していますが、これらはこのタイプのユニットの古典です。 テクスチャを処理およびフィルタリングするための古典的なユニットである、いわゆる3Dサンプラーの場合はどうですか。Intelは、創業以来、すべての3Dグラフィックプロセッサに見られるこの古典的な固定機能のユニットに別の名前を付けました。

ただし、Media Samplerは、Intel GPUに固有であるため、はるかに興味深い部分であり、次の一連の固定機能ユニットで構成されています。
- ビデオモーションエンジンは、ビデオエンコーダの鍵となるピクセルモーション推定を提供します。
- アダプティブビデオスカラーは、画像平滑化フィルターを実行するユニットです。
- De-Noise / De-Interlaceは、インターレースモードのビデオをプログレッシブモードに変換するために、一方では画像のノイズを低減することを担当するユニットです。
Intel Xe以降、Media Samplerはサブスライス内から撤回され、それ自体が独立したユニットになりました。 これは、NVIDIAとAMDの設計に関して引き続き差別化された要素です。
GPUのもうXNUMXつの一般的な部分であるスライス
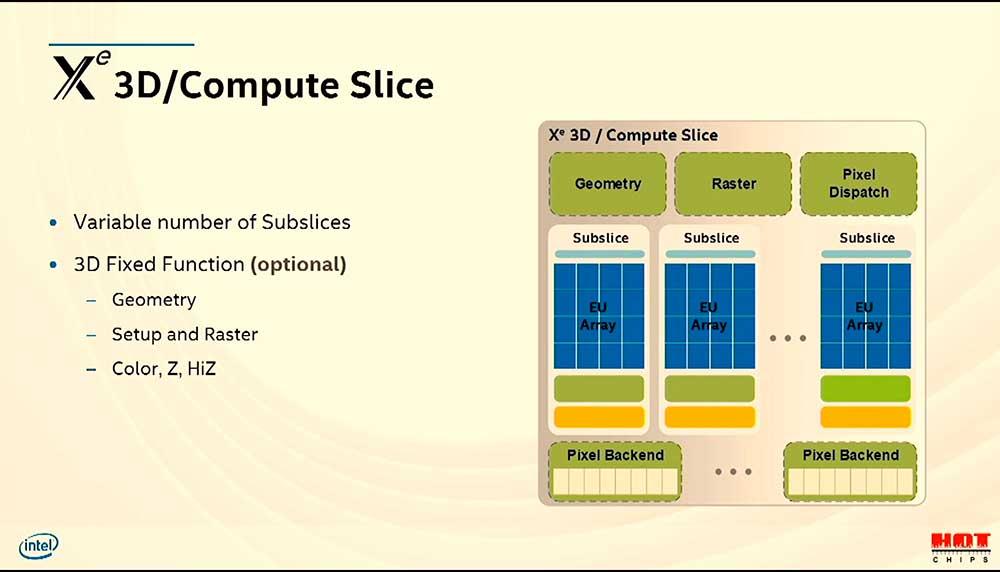
Intel GPUアーキテクチャのスライスは、NVIDIAの場合のシェーダーエンジンまたはGPCと同等です。 ユニットの組織の異なる名前。 内部には、他社のGPUと共通のサブスライスと一連の固定機能ユニットがあります。
繰り返しますが、命名法は混乱する可能性があります。たとえば、残りのアーキテクチャでは、ラスターユニットは通常統一されており、深度バッファーを生成しますが、NVIDIAとAMDの場合、両方の要素は共通ユニットのラスターフェーズで発生しますが、 Intelはそれを個別に行います。
同じことがPixelDispatchとPixelBack-Endにも当てはまります。 ここでXNUMXつの異なる要素によって実行されるROPユニットの機能。 結局のところ、両方の場合に実行されるタスクは同じです。
IntelGPUキャッシュ階層
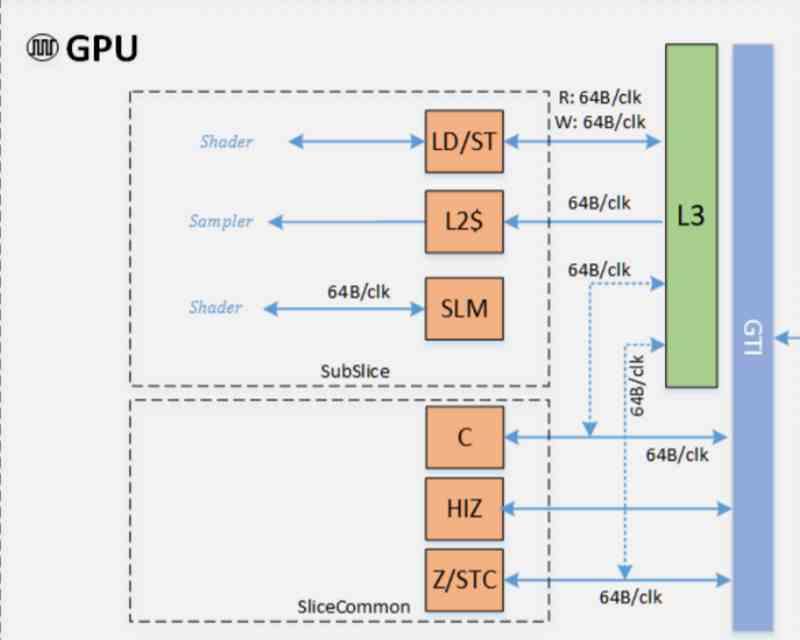
AMDやNVIDIAと比較したIntelGPUの共通アーキテクチャの差別化ポイントの6000つは、まさにキャッシュ階層がどのように編成されているかです。 AMDの場合、新しく組み込まれたものを数えると、RXXNUMXにはXNUMXつのレベルの階層があることがわかります。 インフィニティキャッシュ。 NVIDIAの場合、キャッシュの階層はIntelやAMDの階層とは異なりますが、この記事に焦点を当てたいのはIntelとの競争ではなく、それらに特化していないためです。
このセクションの図は、サブスライスレベルとスライスレベルの両方でのGPU内の内部通信を示しています。 サブスライスの場合、従来のデータキャッシュと共有ローカルメモリがあります。 ただし、NVIDIAやAMD GPUとは異なり、Intelは従来、2Dサンプラーとメディアサンプラーの両方からアクセスできるL3キャッシュを追加してきました。 これにより、GPUのL3キャッシュがトップレベルのGPUキャッシュになります。
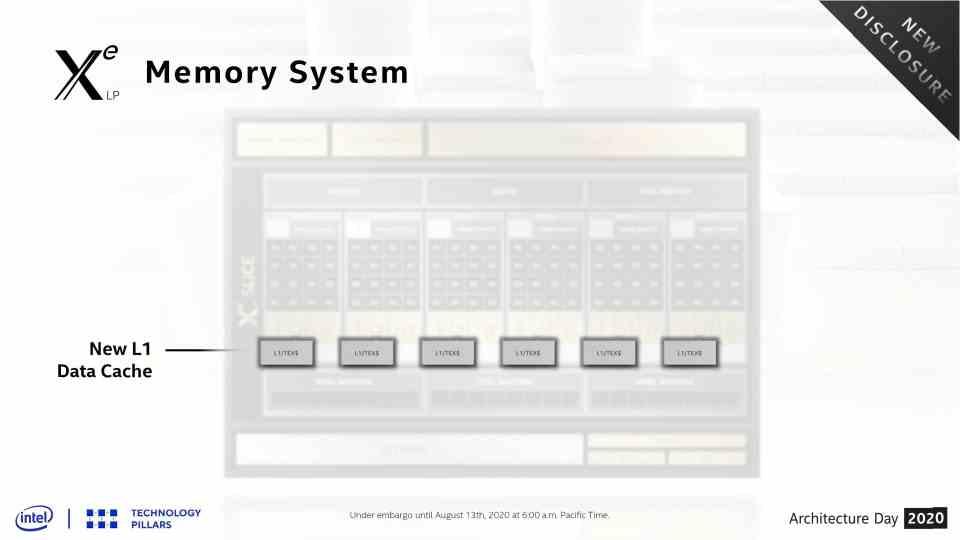
Intel Xeでは、データ用、したがって実行ユニット用のL1キャッシュと、テクスチャ用のL2の違いが変更され、両方がデータとテクスチャの単一のL1キャッシュに統合されました。 そのため、競合するGPUと比較して、完全に標準的な構成になっています。
もう3つの変更は、L3または最終レベルのキャッシュに関するものです。 最新のGPUは、タイルごとにラスタライズする、いわゆるTiled Cachingをサポートしていますが、最後のレベルのキャッシュでそれを行い、データをメモリにドロップして、データを回復するためのエネルギーコストが急上昇する危険性があります。彼らはそれを16MBからXNUMXMBに増やしました。