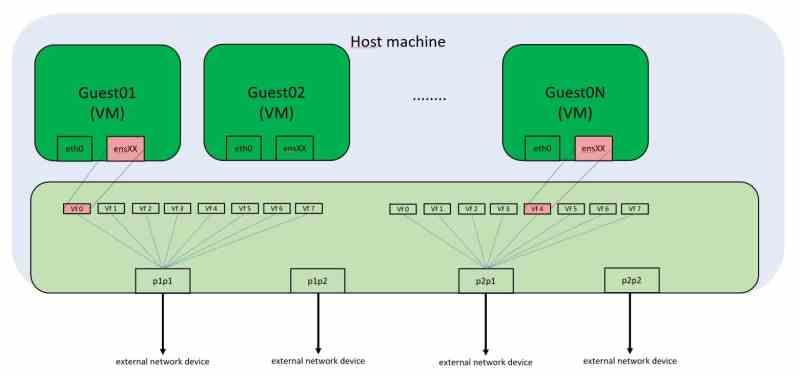
デスクトップおよびラップトップのグラフィックカードの制限のXNUMXつは、複数のオペレーティングシステムまたは仮想マシンを同時に実行できないことです。 一部のGPUが持つこの差別化は仮想化と呼ばれ、この記事では、仮想化とは何か、ハードウェアに必要な変更について説明します。
パソコンが到着する前は、中央のミニコンに接続された端末で作業をしていた。 仮想マシンでさまざまなオペレーティングシステムを実行するクラウドコンピューティングの出現により、仮想化はCPUだけでなくGPUでも必要になります。

GPUで仮想化が必要なのはなぜですか?
仮想化とは、ハードウェアがそれ自体の複数のバージョンを作成して、複数の仮想マシンで使用できるようにする機能です。 たとえば、 CPU 仮想化されたものは、仮想マシンで実行されているオペレーティングシステムによって認識されますが、他の仮想マシンは、CPUの他の部分を単一の別個のCPUとして認識します。 その場合、システム上で実行されている各オペレーティングシステムの仮想バージョンを作成したため、CPUを仮想化しました。
GPUの場合、グラフィックスとコンピューティングのコマンドリストは、特にメモリの特定の部分に書き込まれます。一般に、PCにマウントするGPUは、間に仮想マシンがなくても単一のオペレーティングシステムで動作するように設計されています。 。
これは、オペレーティングシステムの複数の異なるインスタンス、仮想マシンが通常実行されており、各クライアントがにアクセスする必要があるデータセンター用のグラフィックカードには当てはまりません。 GPU。 GPUでの仮想化が必要なのはこの場合です
GPU側からの仮想化

GPUは、仮想化をサポートするためにハードウェアレベルでの変更も必要です。 このため、この容量のグラフィックカードは通常、デスクトップPCから遠く離れた市場にのみ販売されており、デスクトップGPUよりもはるかに高い価格になっています。 今日では、クラウドでGPUのパワーを利用して、特定の科学的作業を加速したり、映画やシリーズのシーンをリモートでレンダリングしたりすることができます。
SR-IOV
各PCIExpressペリフェラルには、各PCのメモリマップ上に一意のメモリアドレスがあります。 つまり、仮想化環境を使用している場合、グラフィックカードなどのこれらのポートに接続されているハードウェアに何度もアクセスすることはできません。 通常、デスクトップPCで実行する仮想マシンには、ゲストオペレーティングシステムのみがアクセスできるグラフィックカードを使用する機能がありません。
これに対するソリューションはSR-IOVです。これは、PCI Expressポートを仮想化し、複数の仮想マシンがこれらのメモリアドレスに同時にアクセスできるようにします。 PCでは、周辺機器の通信は特定のメモリアドレスへの呼び出しを介して行われます。 現在、これらの呼び出しは物理メモリアドレスではなく仮想メモリアドレスに対応していますが、データの内容に関して競合が発生するため、メモリアドレスの内容をXNUMXつのクライアントが同時に操作することはできないという不可侵のルールがあります。
SR-IOVが機能するには、リソースへのアクセスが必要なさまざまな仮想マシンからの要求を受信するグラフィックカードを処理する場合、PCIExpressデバイスに統合されたネットワークコントローラーが必要です。
GPU仮想化のためのDMAドライブへの変更
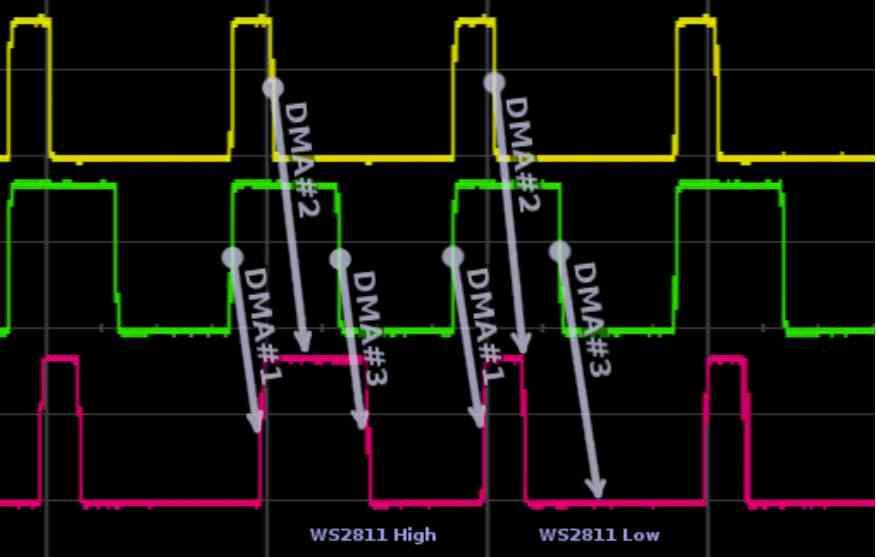
最初の変更はDMAユニットで発生します。これらのユニットは通常、PCで使用するGPUでペアになっており、 RAM 代替チャネルを介して、VRAMと混同しないようにシステムの各フレームで、GPUはRAMの一部の画面リストを読み取るためにアクセスする必要があります。または、後でデータが必要になった場合に備えて、RAMからVRAMにデータをコピーする必要があります。 これは、各方向にXNUMXつのDMAユニットを使用します。 仮想化を備えたGPUの場合? 複数のDMAユニットを並列に使用するか、XNUMXつのDMAユニットと複数の同時アクセスチャネルを使用します .
仮想GPUによるさまざまなチャネルの使用は、統合ネットワークコントローラーによって管理されます。統合ネットワークコントローラーは、物理的に、またはPCIExpressポートに接続されている別の周辺機器への要求を管理します。 したがって、異なる仮想GPUがアクセスする必要がある場合、たとえば、 SSD ディスク、彼らはDMAユニットを介してそうします。
GPUコマンドプロセッサの変更
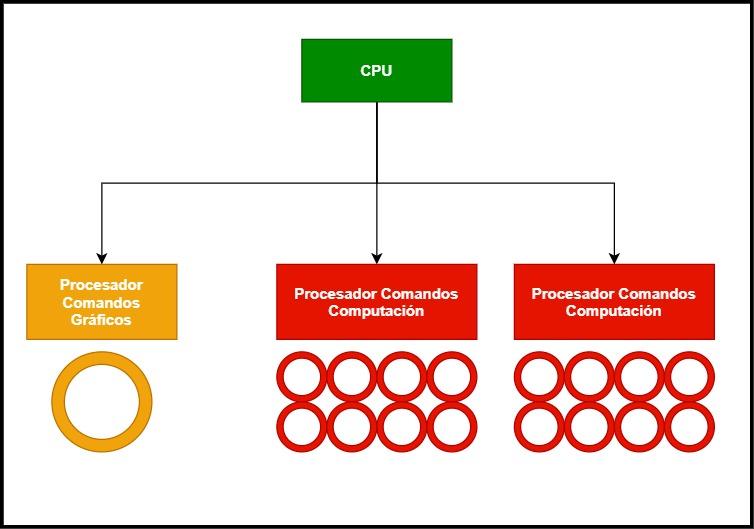
XNUMX番目の変更は、コマンドプロセッサにあります。 途中でグラフィックスなしでコンピューティングするためのすべてのGPUは、同時に複数のコンテキストで動作することに慣れています。これは、それらが非常に小さなコマンドリストであり、短時間で解決されるためです。通常、コマンドの単一のリストが使用されるため、完全に変更されます。
複数のディスプレイを使用する非仮想化GPUはどうですか? これらの場合の画面リストは、各画像の送信に必要なビデオ出力をGPUに示す単一のオペレーティングシステムからのものであるため、仮想マシンで複数のオペレーティングシステムを使用することと同じではありません。
したがって、DMAユニットおよび統合ネットワークコントローラーと連携して機能する特別なグラフィックスコマンドプロセッサを実装して、XNUMXつのGPUとしてではなく、いくつかの異なる仮想GPUとして機能させる必要があります。
GPUリソースは仮想化で分散されます
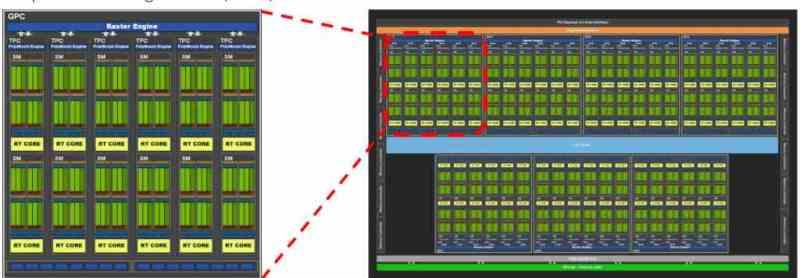
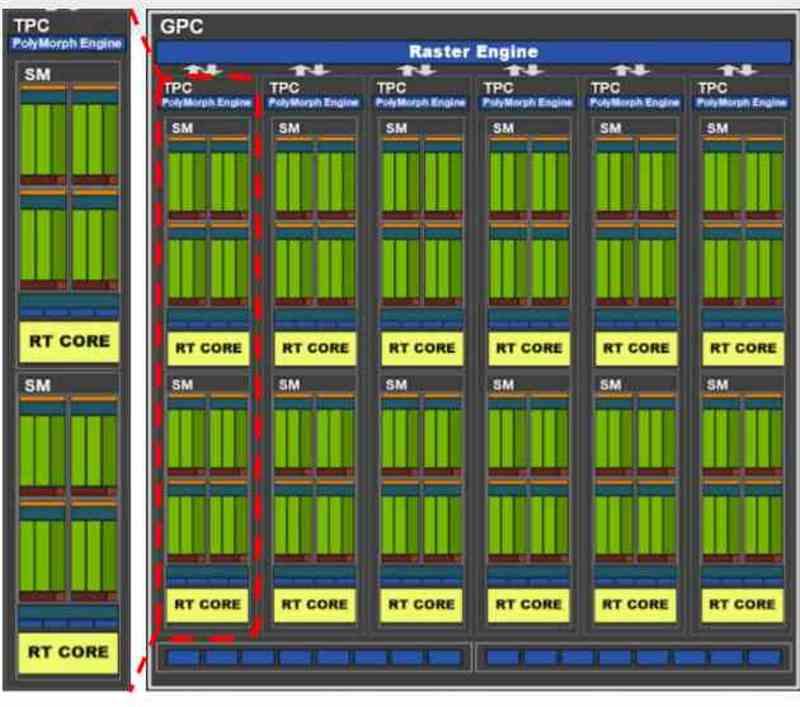
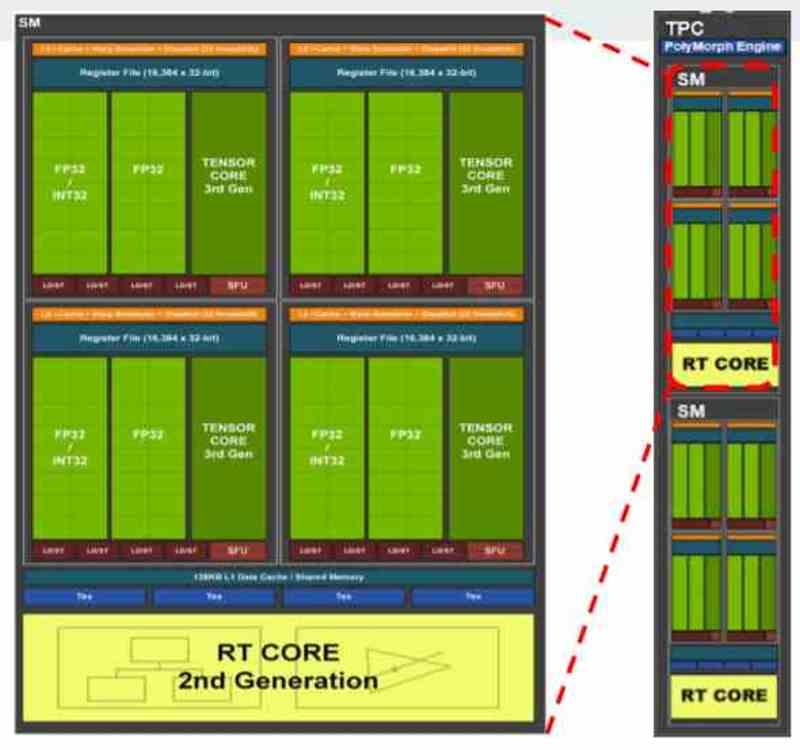
最新のグラフィックカードはすべて、通常、他のブロック内のいくつかのブロックに分割されています。たとえば、GA102を NVIDIA RTX 3080または3090は、最初は複数のGPCで構成されており、その中には複数のTPCがあり、各TPCには2つのSMがあります。
製造元によるリソースの分散の提案方法に応じて、各仮想マシンがGPCに対応する分散を見つけることができるため、GA102の場合、7つの異なるGPUの仮想化について説明します。 TPCレベルでそれを行うことも可能ですが、その場合、最大36台の仮想マシンを作成できますが、私たちが理解しているように、それぞれのパワーは大きく異なります。
GPUでは、NVIDIAで割り当てられるのは完全なGPCであるか、 AMD これらの各パーツには、GPUとして機能するために必要なすべてのコンポーネントが含まれているため、シェーダーエンジンとして知られています。 仮想化GPUがレンダリングではなくコンピューティングに使用される場合、ディストリビューションはTPCレベルまたはAMDRDNAの同等のWGPになります。