AVX-512命令は、の固有の要素のXNUMXつです。 インテルのx86 CPU アーキテクチャ。 しかし、Intel CPUに実装されているため、これらの命令は何ですか? これらの命令が存在する理由、それが持つバリアント、およびによって使用されない理由を理解するために読み続けてください AMD そのCPUで。
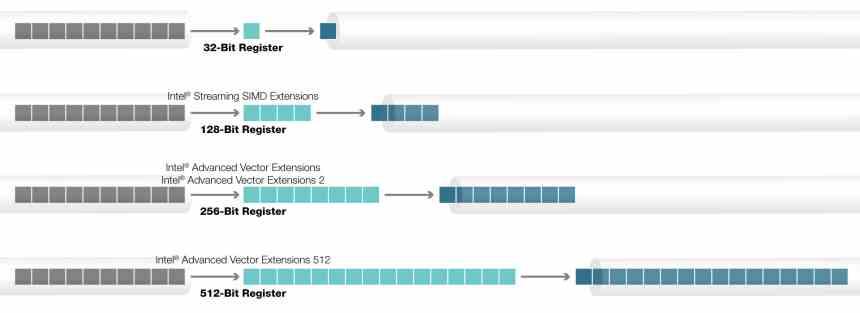
AVX命令は、最初にIntel CPUに実装され、古いSSE命令に取って代わりました。 それ以来、それらは、86ビットと128ビットの256つのバリアントでx512 CPUの標準SIMD命令になり、AMDでも採用されています。 一方、AVX-XNUMX命令について話すと、状況は異なり、IntelCPUでのみ使用されます。

SIMDユニットとは何ですか?
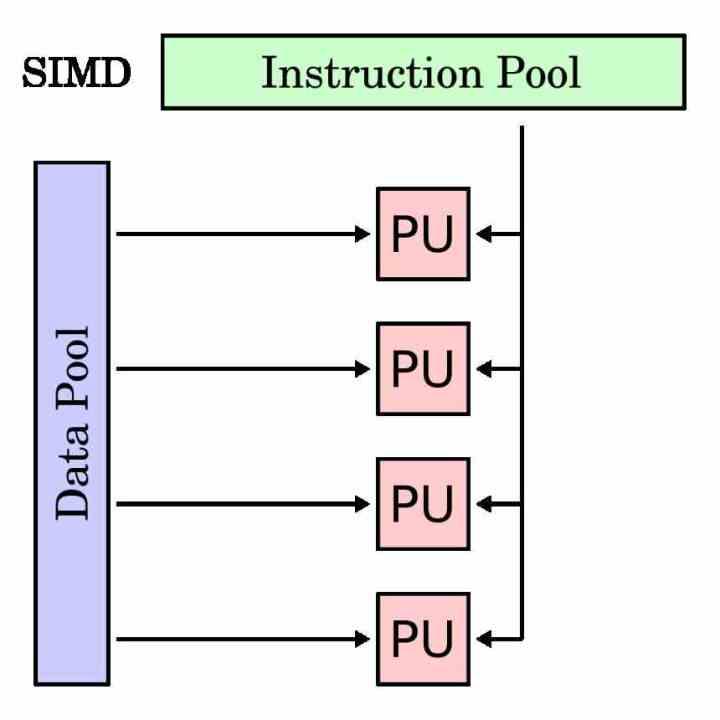
SIMDユニットは、複数のデータに対して同じ命令を同時に実行することを目的とした実行ユニットの一種です。 したがって、そのアキュムレータレジスタは、同じ命令で動作する必要があるさまざまなデータをグループ化する必要があるため、従来の命令よりも長くなります。
SIMDユニットは、同じ命令の下でさまざまなデータを操作する必要がある、いわゆるマルチメディアプロセスを高速化するために伝統的に使用されてきました。 SIMDユニットを使用すると、これらの部分でプログラムの実行を並列化し、実行時間を短縮できます。
すべてのプロセッサで、SIMD実行ユニットを従来の実行ユニットから分離するために、通常はスカラー命令のミラーであるか、単一のオペランドを持つ独自の命令のサブセットがあります。 スカラーユニットでは不可能で、SIMDユニット専用の場合もありますが。
AVX-512の歴史

AVX命令であるAdvancedVector eXtensionsは、何年もの間Intelプロセッサ内にありましたが、AVX-512命令の起源は他の命令とは異なります。 理由? その起源はIntelLarrabeeプロジェクトであり、2000年代後半にIntelが GPU それが最終的にXeonPhiアクセラレータになりました。 Intelが数年前にリリースしたハイパフォーマンスコンピューティング向けの一連のプロセッサ。
Xeon Phi / Larrabeeアーキテクチャには、アキュムレータレジスタのサイズが512ビットの特別なバージョンのAVX命令が含まれていました。これは、最大16個の32ビットデータで動作できることを意味します。 この量の理由は、GPUの一般的なテクセルあたりの操作の比率が通常16:1であるという事実と関係があります。AVX-512命令は失敗したLarrabeeプロジェクトから発信され、そこからXeonPhi。
今日まで、Xeon Phiは存在しません。その理由は、コンピューティング用の従来のGPUを介して同じことができるためです。 これにより、Intelはこれらの命令をCPUのメインラインに転送しました。
AVX-512命令であるジブリッシュ
AVX-512命令は、100%実装された同種のブロックではなく、プロセッサのタイプに応じて追加されているかどうかに応じて、さまざまな拡張機能を備えています。 すべてのCPUはAVX512Fと呼ばれますが、元の命令セットの一部ではなく、Intelが時間の経過とともに追加した追加の命令があります。
AVX512拡張機能は次のとおりです。
- AVX-512-CD: 競合の検出により、ループをベクトル化できるため、ベクトル化できます。 それらはSkylake-XまたはSkylake-SPで最初に追加されました。
- AVX-512-ER: 超越演算の実装用に設計された相互および指数命令。 それらは、KnightsLandingと呼ばれるXeonPhiの範囲に追加されました。
- AVX-512-PF: Knights LandingにもうXNUMXつ含まれています。今回は、指示の予防的または事前技術的な機能を強化します。
- AVX-512-BW: バイトレベル(8ビット)およびワードレベル(16ビット)の命令。 この拡張機能を使用すると、8ビットおよび16ビットのデータを操作できます。
- AVX-512-DQ: 32ビットおよび64ビットデータで新しい命令を追加します。
- AVX-512-VL :AVX命令がXMM(128ビット)およびYMM(256ビット)アキュムレータレジスタで動作できるようにします
- AVX-512-IFMA: 口語的にA *(B + C)命令であり、52ビット整数の精度を持つFused MultiplyAdd。
- AVX-512-VBMI: バイトレベルのベクトル操作命令は、AVX-512-BWの拡張機能です。
- AVX-512-VNNI: ベクトルニューラルネットワーク命令は、人工知能に関連するアプリケーションで使用される、ディープラーニングアルゴリズムを高速化するために追加された一連の命令です。
AMDがまだCPUに実装していないのはなぜですか?

この理由は非常に単純です。AMDは、特定のタイプのアプリケーションを高速化するときに、CPUとGPUを組み合わせて使用することに取り組んでいます。 IntelとAMDの故障したGPUでのAVX-512の起源を忘れないでください。RadeonGPUのおかげで、AVX-512命令を使用する必要がありません。
そのため、AVX-512命令は、完全な排他性ではなく、Intelプロセッサ専用ですが、AMDはGPU、特に新しく発売されたAMD Instinctを販売することを目的としているため、CPUでこのタイプの命令を使用することに関心がないためです。 CDNAアーキテクチャを使用したハイパフォーマンスコンピューティング。
AVX-512命令には将来性がありますか?

まあ、私たちは知りません、それはIntel Xe、特にXe-HPCの成功に依存します。Xe-HPCはIntelにAMDとのレベルでGPUアーキテクチャを提供します NVIDIA。 これは、同じ問題を解決するためのIntelXeとAVX-512の命令間の競合を意味します。
AVX-512の問題は、それを利用するCPUの部分をアクティブ化すると、CPUクロック速度に影響を及ぼし、特定の瞬間にこれらの命令を使用するプログラムで約25%低下することです。 さらに、その命令は、家庭用CPUとは何かにおいて重要ではない高性能コンピューティングおよびAIアプリケーションを対象としており、特殊なユニットの出現により、トランジスタとスペースが無駄になります。
実際には、アクセラレータまたはドメイン固有のプロセッサは、CPUのSIMDユニットを徐々に置き換えています。これは、CPUのSIMDユニットを、より少ないスペースで、比較してわずかな電力消費で同じように実行できるためです。