जब हमारे पास सर्वर होता है Linux या एक NAS सर्वर (जिसमें एक लिनक्स-आधारित ऑपरेटिंग सिस्टम भी है) ऑपरेटिंग सिस्टम और व्यक्तिगत या कार्य फ़ाइलों और फ़ोल्डरों दोनों के अंदर बहुत सारी जानकारी के साथ, यह नियंत्रित करना आवश्यक है कि हार्ड ड्राइव और एसएसडी ड्राइव अच्छे स्वास्थ्य में हैं और बिना किसी चेतावनी के जल्द ही टूटने वाले नहीं हैं। इस कारण से, हमारे सर्वर की हार्ड ड्राइव या एसएसडी की लगातार निगरानी करना बहुत महत्वपूर्ण है, ताकि डेटा के टूटने से होने वाली हानि से बचा जा सके। आज इस लेख में हम आपको वह सब कुछ दिखाने जा रहे हैं जो आपको अपने डिस्क के स्वास्थ्य की जांच करने के लिए अपने लिनक्स सर्वर पर जांचना चाहिए।

डिस्क का स्मार्ट क्या है
सभी हार्ड ड्राइव और SSD ड्राइव में SMART नामक एक तकनीक होती है, या SMART के रूप में भी जानी जाती है, जिसका अर्थ है "सेल्फ मॉनिटरिंग एनालिसिस एंड रिपोर्टिंग टेक्नोलॉजी"। हार्ड ड्राइव और एसएसडी के फर्मवेयर में शामिल इस तकनीक में हार्ड ड्राइव में संभावित विफलताओं का पता लगाना शामिल है, जिसका उद्देश्य हार्ड ड्राइव में भौतिक त्रुटियों या आंतरिक फ्लैश मेमोरी में लिखने के कारण एसएसडी ड्राइव में अप्रत्याशित विफलताओं का अनुमान लगाना है। . स्मार्ट का लक्ष्य उपयोगकर्ताओं को सचेत करना है ताकि वे बिना किसी डेटा हानि के ड्राइव का बैकअप ले सकें और उसे बदल सकें। यदि हम स्मार्ट को अनदेखा करते हैं, तो एक समय आएगा जब हार्ड ड्राइव टूट जाएगी और हम डेटा खो देंगे, इसलिए डिस्क के स्मार्ट डेटा पर हमेशा ध्यान देना आवश्यक है।
स्मार्ट का उपयोग करने के लिए, यह नितांत आवश्यक है कि सर्वर का BIOS या UEFI इस तकनीक के अनुकूल हो और यह सक्रिय हो, इसके अलावा, यह भी नितांत आवश्यक है कि डिस्क इसे शामिल करे। आज सभी सर्वर, ऑपरेटिंग सिस्टम और डिस्क हार्ड डिस्क में समस्याओं का पता लगाने के लिए इस तकनीक का उपयोग करते हैं, हम कह सकते हैं कि यह "सार्वभौमिक" है और इसका हमेशा उपयोग किया जाता है।
यह तकनीक हार्ड डिस्क के विभिन्न मापदंडों की निगरानी के लिए जिम्मेदार है, जैसे कि डिस्क प्लेटर्स की गति, खराब सेक्टर, कैलिब्रेशन त्रुटियां, चक्रीय अतिरेक जांच (सामान्य सीआरसी त्रुटियां), डिस्क तापमान, डेटा पढ़ने की गति, समय शुरू करना (स्पिन- अप), वास्तविक क्षेत्र काउंटर, खोज गति (समय की तलाश) और अन्य बहुत उन्नत पैरामीटर जो आपको यह जानने की अनुमति देते हैं कि क्या महत्वपूर्ण है: यदि हार्ड ड्राइव जल्द ही विफल होने वाली है।
आंतरिक रूप से स्मार्ट में कई मान होते हैं जिन्हें हम "सामान्य" मान सकते हैं, और जब कोई पैरामीटर इन मानों से बाहर हो जाता है, यानी जब अलार्म बंद हो जाता है, तो BIOS/UEFI इसका पता लगाएगा और ऑपरेटिंग सिस्टम को सूचित करेगा कि कोई विफलता है। प्रणाली में। डिस्क और यह गंभीर हो सकता है। लिनक्स ऑपरेटिंग सिस्टम में हमारे पास यह जांचने के लिए स्मार्ट परीक्षण करने की संभावना है कि क्या डिस्क सही तरीके से काम कर रही है, इसके अलावा, हमारे पास प्रदर्शन पर प्रभाव को कम करने के लिए इन परीक्षणों को प्रोग्रामिंग करने की संभावना है।
डिस्क स्वास्थ्य कैसे देखें
अधिकांश लिनक्स आधारित वितरणों में हमारे पास एक पैकेज होता है जिसे स्मार्टमोंटूल कहा जाता है। कभी-कभी यह पैकेज हमारे वितरण में पूर्व-स्थापित होता है, और कभी-कभी हमें इसे स्वयं स्थापित करना पड़ता है। इस पैकेज में दो अलग-अलग कार्यक्रम हैं:
- स्मार्टसीटी : कमांड लाइन प्रोग्राम है जो हमें मांग पर हार्ड ड्राइव और एसएसडी को सत्यापित करने की अनुमति देता है, या हम ऑपरेटिंग सिस्टम में विशिष्ट क्रॉन के माध्यम से इसके संचालन को प्रोग्राम कर सकते हैं।
- स्मार्टडी : एक डेमॉन या प्रक्रिया है जो सत्यापित करती है कि एक निर्दिष्ट अंतराल में हार्ड ड्राइव या एसएसडी में कोई विफलता नहीं है। यह सर्वर के मुख्य syslog में किसी भी प्रकार की चेतावनी या डिस्क त्रुटि दर्ज करने में सक्षम है, यह व्यवस्थापक को ईमेल द्वारा इन समान चेतावनियों और त्रुटियों को भेजने की भी अनुमति देता है ताकि वह सत्यापित कर सके कि सब कुछ सही है।
स्मार्टमॉन्टूल पैकेज हार्ड ड्राइव और एसएसडी ड्राइव की निगरानी के लिए जिम्मेदार है, भले ही वे सैटा, एससीएसआई, एसएएस या एनवीएमई इंटरफेस का उपयोग करते हों, यह किसी भी प्रकार के डेटा इंटरफेस का समर्थन करता है। बेशक, यह कार्यक्रम पूरी तरह से मुफ्त है।
स्थापना
इस प्रोग्राम की स्थापना, यदि यह आपके लिनक्स वितरण पर डिफ़ॉल्ट रूप से स्थापित नहीं है, तो आपके वितरण के पैकेज प्रबंधक का उपयोग कर रहा है। उदाहरण के लिए, डेबियन ऑपरेटिंग सिस्टम पर उपयुक्त के साथ यह इस प्रकार होगा:
sudo apt install smartmontools
आपके वितरण के पैकेज मैनेजर के आधार पर, आपको एक कमांड या किसी अन्य का उपयोग करना होगा, महत्वपूर्ण बात यह है कि यह पैकेज सभी यूनिक्स-आधारित वितरणों और लिनक्स के लिए भी उपलब्ध है, इसलिए आप इसे बिना किसी समस्या के फ्रीबीएसडी पर भी स्थापित कर सकते हैं।
Smartctl . का उपयोग करना
इस प्रोग्राम का उपयोग करने और अपनी हार्ड ड्राइव के स्वास्थ्य की जांच करने के लिए, सबसे पहले हमें यह जानना होगा कि हमारे पास कितनी हार्ड ड्राइव हैं, और उन हार्ड ड्राइव या एसएसडी की जांच करने का मार्ग क्या है। यह जानने के लिए कि डिस्क कहाँ हैं, हमें निम्नलिखित कमांड निष्पादित करनी चाहिए:
df -h
हम अपने सर्वर पर मौजूद डिस्क की सूची प्राप्त करने के लिए fdisk का भी उपयोग कर सकते हैं:
sudo fdisk -l
ये कमांड हमें इकाइयों और विभाजनों की सूची भी दिखाएंगे। हमें इस प्रोग्राम का उपयोग हार्ड डिस्क या एसएसडी स्तर पर करना है, विभाजन स्तर पर नहीं। आम तौर पर लिनक्स सिस्टम में हम डिस्क को /dev/sdX पथ में पाएंगे।
एक बार जब हम जानते हैं कि स्मार्ट के माध्यम से हम किस ड्राइव का विश्लेषण करने जा रहे हैं, तो हमें पता होना चाहिए कि कुल दो अलग-अलग परीक्षण हैं जो हम कर सकते हैं:
- लघु परीक्षण - इस परीक्षण का उपयोग अक्सर डिस्क समस्याओं का पता लगाने के लिए किया जाता है। इस परीक्षण को करते समय, यह हमें सबसे महत्वपूर्ण त्रुटियों और चेतावनियों को दिखाएगा, बिना पूरी डिस्क का विस्तार से विश्लेषण करने की आवश्यकता के। हम क्रोन के माध्यम से इस लघु परीक्षण को साप्ताहिक रूप से निर्धारित कर सकते हैं, इस तरह, सप्ताह में एक बार यह विश्लेषण करेगा और हमें सूचित करेगा कि क्या इसमें कोई त्रुटि है। यह परीक्षण ऐसे समय में करने की सलाह दी जाती है जब बहुत कम या कोई उपयोग नहीं होता है, इसे काम के घंटों के दौरान करने की अनुशंसा नहीं की जाती है, सुबह में बेहतर होता है।
- लंबा परीक्षण - ड्राइव और उसकी क्षमता के आधार पर इस परीक्षण में काफी लंबा समय लग सकता है। इस व्यापक परीक्षण को करने से, यह हमें पूरी डिस्क पर मिलने वाली सभी चेतावनियों या त्रुटियों को दिखाएगा। हम क्रोन के साथ मासिक रूप से किए जाने वाले इस लंबे परीक्षण को शेड्यूल कर सकते हैं, यानी हर महीने एक बार हम डिस्क के स्वास्थ्य की जांच के लिए यह परीक्षण करेंगे। यह परीक्षण ऐसे समय में करने की सलाह दी जाती है जब डिस्क का बहुत कम उपयोग होता है, उदाहरण के लिए, भोर में, क्योंकि अन्यथा पढ़ने और लिखने के प्रदर्शन के साथ-साथ डेटा एक्सेस विलंबता में काफी वृद्धि होगी।
एक बार जब हम उन दो प्रकार के परीक्षणों को जान लेते हैं जिनका हम उपयोग कर सकते हैं, तो सबसे पहले हमें यह जानना होगा कि क्या हार्ड ड्राइव या एसएसडी में स्मार्ट सक्षम है:
sudo smartctl -i /dev/sda
इस घटना में कि डिस्क स्मार्ट का समर्थन करती है, लेकिन सक्रिय नहीं है, हम निम्नलिखित कमांड को निष्पादित करके इसे सक्रिय कर सकते हैं:
sudo smartctl -s on /dev/sda
डिस्क के निर्माता की सभी स्मार्ट विशेषताओं को देखने के लिए, हम निम्नलिखित कमांड निष्पादित कर सकते हैं:
sudo smartctl -a /dev/sda
एक छोटा परीक्षण करने के लिए हम निम्नलिखित निष्पादित करते हैं:
sudo smartctl -t short /dev/sda
एक लंबा परीक्षण करने के लिए हम निम्नलिखित निष्पादित करते हैं:
sudo smartctl -t long /dev/sda
एक बार जब हम छोटा या लंबा परीक्षण कर लेते हैं, तो हम सभी परिणाम देखने के लिए निम्न आदेश निष्पादित कर सकते हैं:
sudo smartctl -H /dev/sda

हम स्मार्टक्टल के मैन पेजों को पढ़ने की सलाह देते हैं जहां आपको वे सभी कमांड मिलेंगे जिन्हें हम स्मार्ट की संभावनाओं का उपयोग करने के लिए निष्पादित करने में सक्षम होने जा रहे हैं, हालांकि, मुख्य कमांड वही हैं जिन्हें हमने आपको समझाया है।
मुझे किन मूल्यों को देखना चाहिए?
जब हम एक स्मार्ट परीक्षण करते हैं, तो हमारी हार्ड ड्राइव या एसएसडी की बड़ी संख्या में विशेषताएँ दिखाई देंगी। इनमें से कुछ मूल्य महत्वपूर्ण हैं जिन पर हम पूरा ध्यान देते हैं, क्योंकि वे हमें "संकेत" दे सकते हैं कि डिस्क बहुत जल्द विफल होने वाली है:
- रीयललोकेटेड_सेक्टर_सीटी: उन सेक्टरों की संख्या है जिन्हें डिस्क के अन्य क्षेत्रों में पुन: आवंटित किया गया है क्योंकि पढ़ने में त्रुटियां हैं। यह त्रुटि बहुत विशिष्ट होती है जब डिस्क बहुत पुरानी होती है और इसके उपयोगी जीवन के अंत के करीब होती है।
- स्पिन_रेट्री_काउंट: डिस्क को बूट करने के लिए आवश्यक प्रयासों की संख्या है, यह इंगित करता है कि डिस्क में एक गंभीर हार्डवेयर समस्या है, और यह अगली बार बूट नहीं हो सकता है।
- रीयललोकेटेड_इवेंट_काउंट - सफलतापूर्वक या असफल रूप से किए गए वास्तविक स्थानों की संख्या। संख्या जितनी अधिक होगी, हार्ड ड्राइव का स्वास्थ्य उतना ही खराब होगा।
- Current_Pending_Sector: उन क्षेत्रों की संख्या जो जल्द ही पुनः आवंटित करने के लिए लंबित हैं।
- Offline_Unrectable: डिस्क के विभिन्न सेक्टरों तक पहुँचने, पढ़ने या लिखने में, अचूक त्रुटियों की संख्या।
- Multi_Zone_Error_Rate: किसी सेक्टर के लेखन के दौरान त्रुटियों की कुल संख्या।
निम्न छवि में आप हमारे NAS से XigmaNAS ऑपरेटिंग सिस्टम के साथ WD Red 4TB हार्ड ड्राइव की स्थिति देख सकते हैं:

पिछले स्क्रीनशॉट में आप बहुत सारी जानकारी देख सकते हैं, लेकिन हमें पता होना चाहिए कि क्या यह एक अलग विफलता है या हमारी डिस्क जल्द ही विफल हो सकती है।
QNAP NAS में डिस्क की स्थिति
यदि आपके पास QNAP, Synology या ASUSTOR NAS सर्वर है, तो आप वेब एक्सेस के साथ ऑपरेटिंग सिस्टम के माध्यम से अपनी हार्ड ड्राइव और SSD की स्मार्ट स्थिति भी देख पाएंगे, SSH या टेलनेट के माध्यम से प्रवेश करने और किसी भी कमांड को निष्पादित करने की कोई आवश्यकता नहीं है। . नीचे दिए गए उदाहरण में हमने QNAP NAS सर्वर का उपयोग किया है, लेकिन अन्य निर्माताओं के साथ प्रक्रिया बहुत समान होगी।
पहली चीज जो हमें करनी है वह है " भंडारण और स्नैपशॉट "अनुभाग, एक बार यहाँ," पर क्लिक करें भंडारण / डिस्क " और हम कुछ इस तरह देखेंगे:

अगर हम “पर क्लिक करते हैं डिस्क की स्थिति ”, हमें चुनना होगा कि हम सभी में से किस डिस्क को देखना चाहते हैं। हम HDD हार्ड ड्राइव के साथ-साथ SSD ड्राइव दोनों का चयन कर सकते हैं, चाहे वे किसी भी प्रकार के हों क्योंकि उनके पास यह देखने के लिए आंतरिक SMART जानकारी भी है कि क्या कोई डिस्क त्रुटि है।

"सारांश" मेनू में हम डिस्क की सामान्य स्थिति देख सकते हैं, यदि किसी प्रकार की त्रुटि या गंभीर चेतावनी है, तो हम स्मार्ट के विस्तृत विश्लेषण की आवश्यकता के बिना सामान्य स्वास्थ्य को आसानी से और जल्दी से देख सकते हैं। मूल्य। बेशक, हम डिस्क एक्सेस इतिहास भी देख सकते हैं और यदि कोई समस्या हुई है।

हालाँकि QNAP हमें समझने में बहुत आसान जानकारी प्रदान करता है, अगर हम सभी कच्चे मूल्यों को देखना चाहते हैं, तो हम इसे बिना किसी समस्या के कर पाएंगे। इसके अलावा, हमारे पास एक अतिरिक्त कॉलम होगा जो हमें "स्थिति" बताता है और यह बताता है कि यह अच्छा है या बुरा।
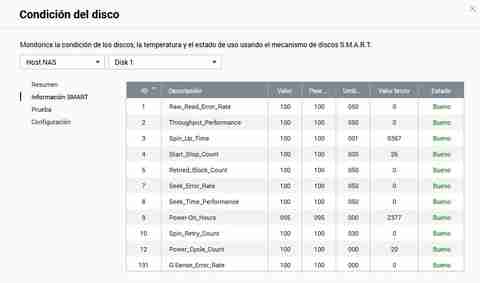
हम यहां के माध्यम से त्वरित या पूर्ण परीक्षण करने में सक्षम होंगे, हमें बस परीक्षण विधि चुननी है और फिर "टेस्ट" बटन पर क्लिक करना है।

अंत में, हम इन परीक्षणों को बहुत आसान तरीके से भी प्रोग्राम कर सकते हैं, हमें बस त्वरित या पूर्ण परीक्षण को सक्रिय करना चुनना है, और आवृत्ति चुनना है: दैनिक, साप्ताहिक या मासिक, इसके अलावा, हम इस परीक्षण के प्रारंभ समय को परिभाषित कर सकते हैं।

जैसा कि आप देख सकते हैं, सर्वर में हार्ड ड्राइव और एसएसडी की स्वास्थ्य स्थिति की जांच करना और सत्यापित करना डेटा हानि से बचने के लिए वास्तव में महत्वपूर्ण है। जब किसी प्रकार की त्रुटि होती है, तो डेटा हानि से बचने के लिए एक नई ड्राइव खरीदना और बैकअप बनाना बहुत महत्वपूर्ण है। इसके अलावा, हमें RAID की स्थिति की भी जांच करनी चाहिए क्योंकि हम पूरे स्टोरेज पूल के नुकसान का कारण बन सकते हैं, खासकर अगर हमने ZFS RAID 0 या स्ट्राइप को कॉन्फ़िगर किया है।
