The launch of the RTX 3000 has brought with it some interesting improvements in its architecture, but it has also delighted us with the new GDDR6X memory , a direct evolution of GDDR6 as VRAM. Higher serial frequency, more performance and more overclock, but no one wonders, how do they do it? The answer is given by two new batch algorithms such as the detection and repetition of errors. What are they and how do they work?
Since the days of GDDR5 it has rained a lot, but the truth is that manufacturers achieved a large number of RMAs by users and most of the dead cards had one factor in common: problems with the VRAM.

Therefore, after the new GDDR5X fiasco (with certain palliative we have to say) the new VRAM standard had to include a series of characteristics that could avoid a sudden death of the card when said VRAM was overclocked.
GDDR6, the first step to reduce memory problems under overclocking

The move from GDDR5X to GDDR6, frequencies, block lengths or voltages out, brought with it several improvements in terms of durability and protection under OC, but the small jump from GDDR6 to GDDR6X memory has meant that NVIDIA is fully involved in improving still more this.
The most obvious question is, how do they do it? First of all, we have to take into account that both GDDR6 and GDDR6X memory have two channels of X16 or X8 as I / O, but there are three key differences between them, of which we will explain two that are related to the best overclocking:
- PAM 4 (Pulse-Amplitude Modulation V4)
- EDR (Error Detection and Replay)
- CRC (Cyclic Redundancy Check)
The first (PAM 4) has to do largely with the increase in serial frequency between both types of memory, which we will discuss in a later article and exclusively on how Micron has achieved more speed in its GDDR6X memories.
But leaving this basic feature aside, it has been NVIDIA, as we say, that has taken action on the matter and on what establishes the best memory overclock so far.
Ampere allows to push GDDR6X memory “without blocking”
| Characteristic | GDDR5 | GDDR5X | GDDR6 | GDDR6X |
|---|---|---|---|---|
| Density | 512MB-8GB | 8 GB | 8GB, 16GB | 8GB, 16GB |
| VDD see VDDQ | 1.5V or 1.35V | 1.35V | 1.35V or 1.25V | 1.35V or 1.25V |
| PPV | – | 1.8 V | 1.8 V | 1.8 V |
| Data transfer rates | Up to Gb / s | Up to 12 Gb / s | Up to 16 Gb / s | 19 Gb / s, 21 Gb / s, > 21 Gb / s |
| number of channels | one | one | two | two |
| Access level | 32 bytes | 64 bytes 2x 32 bytes (in pseudo 32B mode) |
2 channels x 32 bytes | 2 channels x 32 bytes |
| Data block length | 8 | 16/8 | sixteen | 8 (PAM4 mode) 16 (RDQS module) |
| Signal | POD15 / POD135 | POD135 | POD135 / POD125 | PAM4 POD135 / POD125 |
| I / O width | x32 / x16 | x32 / x16 | 2 channels x16 / x8 | 2 channels x16 / x8 |
| Signal value | 61 – 40 DQ, DBI, EDC – 15 CA. – 6 CK, WCK |
61 – 40 DQ, DBI, EDC – 15 CA. – 6 CK, WCK |
70 or 74 – 40 DQ, DBI, EDC – 24 CA. – 6 or 10 CK, WCK |
70 or 74 – 40 DQ, DBI, EDC – 24 CA. – 6 or 10 CK, WCK |
| PLL, DCC | PLL | PLL | PLL, DCC | DCC |
| CRC | CRC-8 | CRC-8 | 2x CRC-8 | 2x CRC-8 |
| VREFD | 2 per external or internal byte | Internal per byte | Internal per pin | Internal per pin 3 secondary receivers per pin |
| Balance | – | RX / TX | RX / TX | RX / TX |
| VREFC | External | External or internal | External or internal | External or internal |
| Exploration | THEIR | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) |
NVIDIA has long been aware of the problems of pushing GDDR memory frequencies to the limit or above it in its graphics. Until now, he has always answered that the limit was set by the manufacturer and that it was not necessary to exceed this overclock, but with Ampere he has wanted to end the problems once and for all.
The way to do it has been with EDR or Error Detection and Replay , which is an algorithm introduced in the memory subsystem of the GPU, which can detect when an error occurs in data transmission. When this happens, something very typical when we press the clocks to the GDDR6X memory, sends this verification operation to the CRC (Cyclic Redundancy Check) through any of its two channels, which, when checking and giving validity in said error, said erroneous transmission it is tried again or directly reproduced.
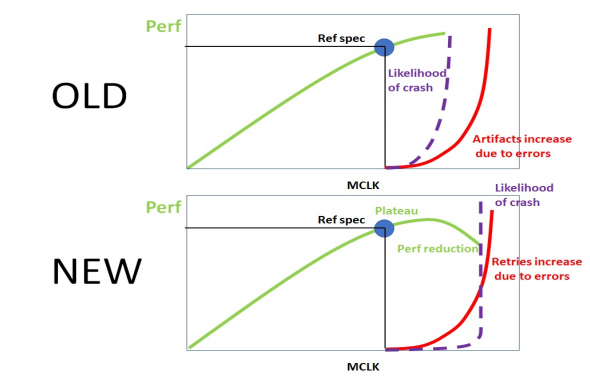
What do you get with this? Wouldn’t it be better to mark the error and leave it default or unused and continue with the rest of the operations? No, it is by no means the most useful as GDDR5 already demonstrated. What these two algorithms do is retry the failed transmission until it succeeds.
NVIDIA recommends not overclocking

Why keep trying an error transmission? To avoid VRAM crash or GPU or system crash. At higher speeds we press the GDDR6X memories, more errors will be produced and with this there will be more retryed transactions, which will consume bandwidth of said GDDR6X memories. This reduces the final performance of the GPU, so we will stop gaining score or FPS, indicating that we have reached the limit of overclocking without a single module dying.
Like everything in this life, nothing is safe. Although we have EDR and CRC, NVIDIA states that we may not even see artifacts on the screen , but that does not mean that in each and every case the modules are not damaged by overclocking, on the contrary, it can happen.
What NVIDIA is trying to tell us is that when performance no longer rises, the limit is exceeded and one or more overclocking sections have to be lowered and therefore we have to stop raising the frequency, because doing so will lead to a time when none algorithms can avoid a system crash.
Even so, they also indicate that although we do not get to this extreme that must be avoided, EDR may not avoid all crashes before performance stabilizes at 100%, so it is not a foolproof technology, as it always usually does. pass.