Si vous avez observé les différents schémas d'architectures différentes, alors vous aurez vu comment dans chacun d'eux le cache le plus proche du processeur, généralement appelé cache de premier niveau ou L1, est divisé en deux types de mémoire différents appelés cache de données et instruction. cache. Quelle est la raison pour ça? Continuez à lire et vous comprendrez pourquoi c'est une pratique courante dans toutes les conceptions
Le premier cache à être implémenté a été le cache de premier niveau, qui depuis sa création a toujours été divisé en deux puits, si vous vous êtes déjà demandé pourquoi, continuez à lire et vous le comprendrez sans problème.

Qu'est-ce que le cache L1 ou de niveau supérieur?
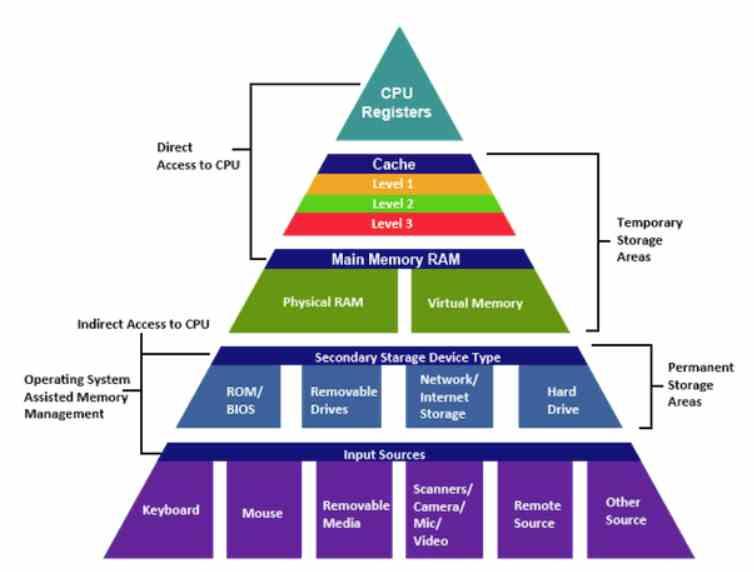
Le cache L1 ou le cache de premier niveau est le plus proche du Processeur ainsi que GPU cœurs, ce qui en fait le type de cache avec la bande passante la plus élevée et la latence la plus faible de toute la hiérarchie de cache. C'est le premier dans lequel, lors de la recherche de données dans n'importe quel type de processeur, le système de hiérarchie de la mémoire cherchera à trouver les données.
Il ne faut pas oublier que le cache ne fonctionne pas dans le cadre du RAM mais copie les données de la RAM près de ce qu'est le processeur à ce moment-là. Un processeur parcourt la mémoire de manière séquentielle à travers les différentes adresses mémoire, donc pour augmenter les performances lors de la capture de données, une mémoire cache est utilisée.
Le cache L1 est toujours séparé
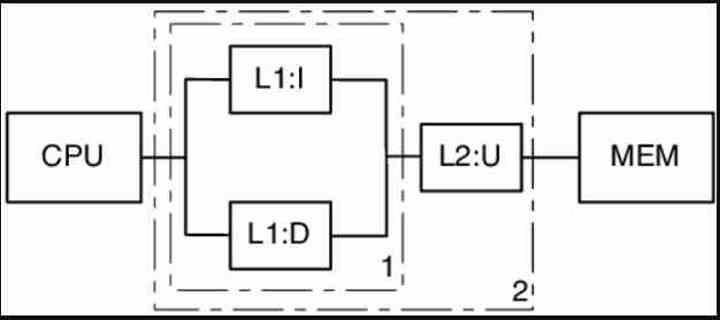
Le cache L1 de tous les processeurs est divisé en deux puits différents, un cache de données et un cache d'instructions. Qu'est-ce que ça veut dire? C'est simple, nous devons d'abord comprendre que tous les processeurs et GPU utilisent un architrave Von Neumann où les instructions qui sont ce que le processeur doit faire, et les données que l'instruction doit manipuler, se trouvent dans la même mémoire. .
Cela signifie que les instructions ont une forme dans laquelle x bits du code qui forment une instruction, les premiers bits correspondent à l'opcode qui indiquent l'action à effectuer par le processeur, les bits qui viennent ensuite correspondent à la façon de le faire l'instruction et ces derniers renvoient aux données. Soit où les données sont ou sont en elles-mêmes, bien qu'il y ait des instructions qui manquent de bits de données et que d'autres n'ont pas de bits de mode.
Les données vont de la RAM aux différents niveaux de cache, où les données et les instructions sont conservées ensemble jusqu'au cache L2, à partir duquel il existe un mécanisme qui copie la première partie de l'instruction, l'opcode et le mode, dans le cache de instructions et l'autre partie dans le registre d'accès mémoire, dans lequel sont placés les bits qui pointent vers l'adresse mémoire. Aujourd'hui, cette dernière partie est un peu plus complexe, mais pour des raisons didactiques, nous allons en rester là.
Quelle est la raison de la séparation du cache?

La raison en est qu'en interne, les informations de l'opcode de l'instruction sont traitées différemment des autres. L'opcode est traité par le décodeur d'instructions du processeur. En fait, dans tous les processeurs, la première partie de l'instruction est traitée en premier et la raison en est très simple. Il existe des instructions qui ne pointent pas vers une adresse mémoire mais incluent plutôt les données à opérer et il n'est donc pas nécessaire que les données soient copiées dans le registre d'accès mémoire, mais plutôt copiées dans un registre spécial.
Lorsque vous devez rechercher des données dans la RAM dans un système avec un cache de premier niveau, une fois que le processeur a vérifié que l'opcode correspond à une instruction qui pointe vers une donnée dans une partie de la mémoire, cette adresse est copiée dans le MAR , la RAM renverra les données dans le registre MDR, le registre de données de mémoire, et les mécanismes correspondants copieront les données dans le registre correspondant, normalement le registre d'accumulateur, qui est celui utilisé pour les opérations arithmétiques.
L'ensemble du processus de décodage des instructions et de recherche de données se déroule en parallèle, avec plusieurs accès au cache L1 qui, s'ils étaient effectués sous la même mémoire, finiraient par créer un énorme conflit lors de l'accès. En d'autres termes, le cache L1 était essentiel pour augmenter les performances des processeurs, le 80486 étant le premier processeur PC à l'implémenter. Dans les GPU, les caches de premier niveau ont commencé à être implémentés avec l'arrivée d'unités de shader.