Oma prosessorit tai suorittimet että tekoäly tai tekoäly ovat tehneet lommin viime vuosina, vaikkakin eri nimillä. Olemme nähneet niiden ilmestyvän Googlen Tensor Processor Unit -yksikön tai TPU: n muodossa NVIDIA GPU: t tai eri tuotemerkkien erilaiset hermoprosessoriyksiköt tai NPU: t. Mutta heillä kaikilla on yksi yhteinen piste: ne ovat systolisia ryhmiä. Tässä artikkelissa selitämme miten nämä hyvin erityiset prosessorit työ .
Tekoälyn saapuessa olemme viime vuosina nähneet kuinka erilaiset prosessori valmistajat ja suunnittelijat ovat kertoneet meille erityyppisistä yksiköistä tämän toiminnon suorittamiseksi. Mitä tapahtuisi, jos kerromme sinulle, että kaikki nämä nimet ovat todella erilaisia kaupallisia nimikkeistöjä samantyyppisille yksiköille?

AI: n perussuoritin: Systolinen taulukko
Systoliset taulukot ovat perusta ymmärtämään, kuinka keskusyksiköt toimivat tekoälylle; Ne koostuvat ketjusta tai joukosta käsittelyelementtejä, ja kukin näistä on kytketty suoraan muihin käsittelyelementteihin käyttöliittymän kautta, joka kommunikoi ne järjestäytyneesti toistensa kanssa.
Ketjun ensimmäinen elementti on se, joka vastaanottaa ensimmäisen datan ja jolla on siten yhteys I / O-rajapintaan; mainittu rajapinta voi olla muisti, jonka toinen prosessori systolinen ryhmä on apuprosessori tai toinen systolinen ryhmä. Toisessa ääripäässä matriisin viimeinen elementti on se, joka kommunikoi systolisen matriisin yhdistetyn elementin kanssa ja kirjoittaa takaisin koko yhteisen operaation tuloksen.
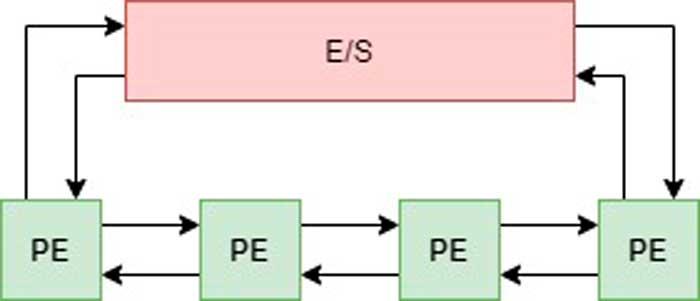
Toisin kuin ei-systolisissa prosessoreissa, joissa tietoja ei siirretä eri elementtien välillä, mutta ne kulkevat aina rekisterien läpi, systolisessa järjestelmässä tiedot välitetään suoraan käsittelyelementistä tai -solusta käsittelyelementteihin tai lähimpiin soluihin.
Kaikkien systolisten järjestelmien etuna on, että käsittelyelementtien välinen tiedonsiirto on nopeampaa kuin tietoliikenteen käsittelyelementti → rekisteri → käsittelyelementti → rekisteri jne.
Niitä kutsutaan systolisiksi johtuen siitä, että jokainen toisiinsa kytketty elementti suorittaa vastaavan toimintansa kellosyklissä ja "pumputtaa" tuloksen naapurisoluihin tai käsittelyelementteihin.
Systoliset matriisit ja tensorit
Samalla tavalla voimme myös yhdistää käsittelyelementit matriisilla ja saada systolisen matriisin, jonka kaavio on alla oleva:
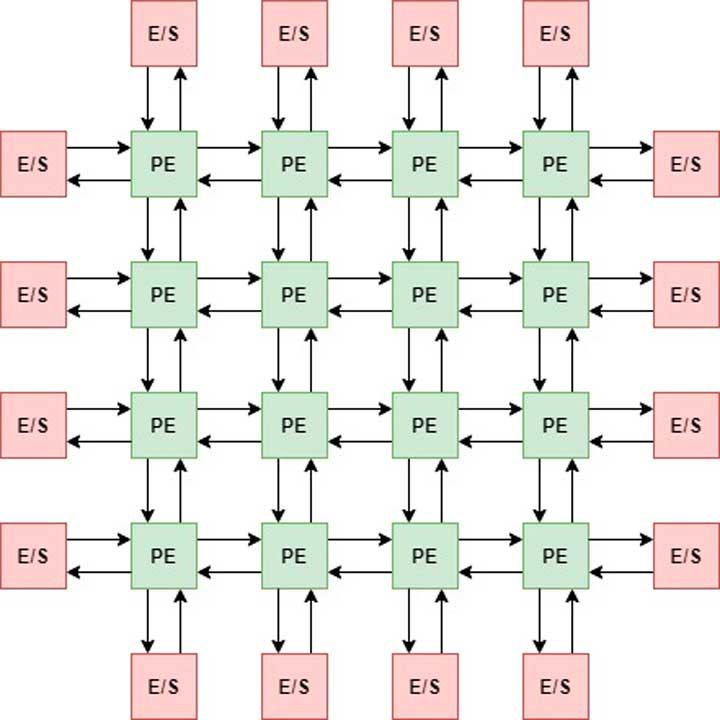
Meillä voi olla jopa kolmiulotteinen kokoonpano, jota kutsumme tensoriksi.
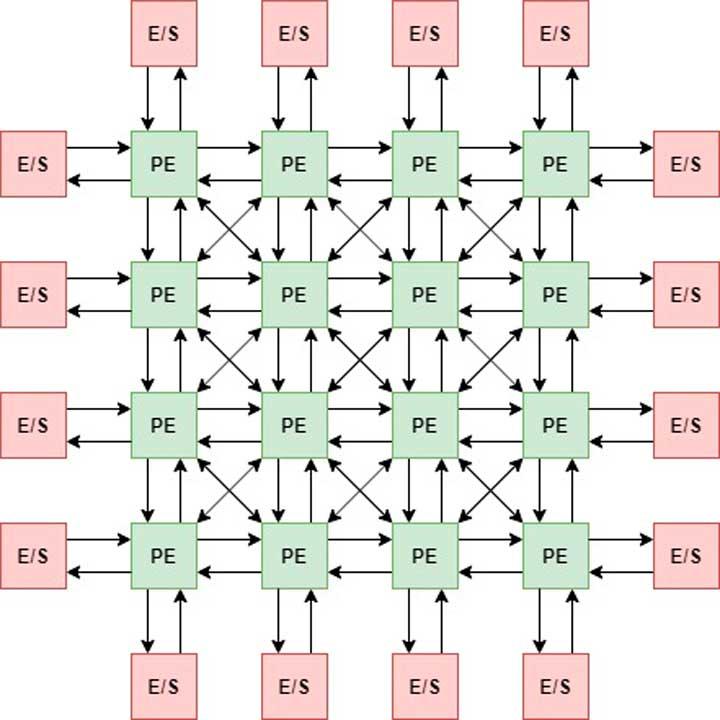
Kaikissa niissä toiminta on sama, ero on siinä, että matriisi- ja tensorijärjestelmissä voimme siirtää dataa paitsi vaaka-, myös pystysuoraan ja jopa vinosti erilaisten operaatioiden suorittamiseksi rinnakkain.
Mistä nimi Tensor tulee?
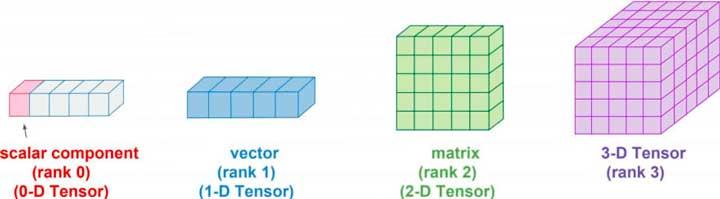
Säännöllisiä kolmiulotteisia matriiseja kutsutaan tensoreiksi, vaikka niitä käytetään kaikentyyppisissä tensoriprosessoreissa, olivatpa ne matriisi- tai tensorityyppisiä.
Käsittelyelementti (PE)
Käsittelyelementit ovat yleensä ALU: ita, joilla on kyky tehdä lisäys ja kertolasku rinnakkain ja samanaikaisesti, mutta voimme käyttää muita elementtejä prosessointielementteinä täyteen ytimeen saakka ja jopa sijoittaa systolisen prosessorin toisen sisälle.
Systolisten järjestelmien hyödyllisyys
Vaikka heistä on tullut kuuluisia tämän tyyppisten prosessorien käytöstä tekoälyn algoritmien nopeuttamiseksi, heillä on muita käyttötarkoituksia, kuten:
- Kuvasuodattimet (interpolointi).
- Etsi malleja.
- Korrelaatio.
- Polynomiarviointi.
- Fourier-muunnokset.
- Matriisikertaus.
- ja niin edelleen
Esimerkiksi grafiikkasuorittimien tekstuuriyksiköt, vaikka ne ovat kiinteitä toimintoyksiköitä, on todella konfiguroitu systoliseksi matriisiksi, kyllä, niitä ei voida ohjelmoida, koska niiden toiminnot ovat mikro-johdotettuja, mutta se on niin, että voit nähdä niiden hyödyllisyyden eikö se tule vain AI: lle.
AI: n osalta sen toteutus johtuu siitä, että matriisikertaus on hyvin hidasta jopa GPU: issa käytetyissä SIMD-yksiköissä tai itse prosessoreissa (AVX, SSE ...), joten mainitun toiminnan suorittamiseen tarvitaan erityinen yksikkö mahdollisimman nopeasti ja siten systolisten matriisien käyttöönotto eri suorittimissa tekoälyn nopeuttamiseksi.