Dnešní společnost potřebuje hojnou výměnu informací pro rozvoj většiny činností nebo pracovních míst. Například společnosti, zejména nadnárodní, distribuují své projekty mezi mnoho ústředí po celém světě; To znamená, že pro správný rozvoj jejich projektů musí existovat komunikace a výměna informací mezi různými místy. Dalším příkladem jsou univerzity, které potřebují systém pro výměnu informací se studenty, pro poskytování poznámek, zkoušek atd.
Proto se kolem roku 1996 objevila první P2P aplikace z rukou Adama Hinkleye, Hotline Connect, která měla být nástrojem pro distribuci souborů pro univerzity a společnosti. Tato aplikace používala decentralizovanou strukturu a její zastarávání netrvalo dlouho (protože záviselo na jediném serveru); a protože byl navržen pro Mac OS, nevyvolával velký zájem uživatelů.

Právě v Napsteru v roce 1999, kdy používání sítí P2P vzbudilo u uživatelů zvědavost. Tento systém pro výměnu hudby používal hybridní síťový model P2P, protože kromě komunikace mezi vrstevníky zahrnoval centrální server pro organizaci těchto párů. Jejich hlavním problémem bylo, že server zavedl zarážky a vysokou možnost úzkých míst.
Proto vznikají nové topologie jako decentralizované, jejichž hlavní charakteristikou je, že k organizaci sítě nepotřebuje centrální server; příkladem této topologie je Gnutella. Dalším typem jsou strukturované P2P sítě, které se zaměřují spíše na organizaci obsahu než na organizaci uživatelů; jako příklad zdůrazňujeme JXTA. Máme také sítě s tabulkou distribuovaných hashů (DHT), například Chord.
Dále budeme vyvíjet výše uvedené typy P2P sítí.
První systémy P2P: hybridní přístup
První systémy P2P, jako Napster nebo SETI @ home, jako první přesunuly nejtěžší úkoly ze serverů do počítačů uživatelů. S pomocí internetu, který umožňuje kombinovat všechny zdroje, které uživatelé poskytují, se jim podařilo zajistit, aby tyto systémy dosáhly větší úložné kapacity a vyššího výpočetního výkonu než servery. Problém však byl v tom, že bez infrastruktury, která by fungovala jako prostředník mezi peer entitami, by se ze systému stal chaos, protože každý peer by nakonec jednal samostatně.
Řešením problému nepořádku je zavedení centrálního serveru, který bude mít na starosti koordinaci párů (koordinace mezi páry se může u jednotlivých systémů velmi lišit). Tyto typy systémů se nazývají hybridní systémy, protože kombinují model klient-server s modelem sítí P2P. Mnoho lidí si myslí, že tento přístup by neměl být popisován jako skutečný P2P systém, protože zavádí centralizovanou komponentu (server), ale i přes tento přístup byl a stále je velmi úspěšný.
V tomto typu systémů, když se entita připojí k síti (pomocí aplikace P2P), je zaregistrována na serveru, takže server neustále kontroloval počet párů, které jsou na daném serveru registrovány, což jim umožňuje nabídnout služby ostatním kolegům. Komunikace peer-to-peer je obvykle point-to-point, protože peer netvoří žádnou významnou síť.
Hlavním problémem tohoto návrhu je, že zavádí bod zlomu systému a vysokou pravděpodobnost výskytu takzvaného „úzkého místa“ (při přenosu dat, kdy je kapacita zpracování zařízení větší než kapacita, ke které je zařízení připojeno ). Pokud síť roste, roste také zatížení serveru a pokud systém není schopen škálovat síť, síť se zhroutí. A pokud server selže, síť by se nemohla sama reorganizovat.
Navzdory všemu však stále existuje mnoho systémů, které tento model používají. Tento přístup je užitečný pro systémy, které nemohou tolerovat nekonzistence a nevyžadují velké množství zdrojů pro koordinační úkoly. Příkladem je, jak Napster funguje. Napster vznikl koncem roku 1999 rukou Shawna Fanninga a Seana Parkeho s myšlenkou sdílení hudebních souborů mezi uživateli.

Způsob, jakým Napster funguje, je ten, že uživatelé se musí připojit k centrálnímu serveru, který je zodpovědný za udržování seznamu připojených uživatelů a souborů, které jsou těmto uživatelům k dispozici. Když chce uživatel získat soubor, provede vyhledávání na serveru a server mu poskytne seznam všech dvojic, které mají soubor, který hledají. Zainteresovaná strana tedy hledá uživatele, který může nejlépe poskytnout to, co potřebuje (například vybrat ty s nejlepší přenosovou rychlostí), a získá svůj soubor přímo od něj, bez prostředníků. Napster se brzy stal velmi populárním systémem mezi uživateli a v roce 26 dosáhl 2001 milionů uživatelů, což způsobilo nepohodlí u nahrávacích společností a hudebníků.
To je důvod, proč RIAA (Recording Industry Association of America) a několik nahrávacích společností ve snaze to ukončit podaly na společnost žalobu, která způsobila uzavření jejích serverů. To způsobilo selhání sítě, protože uživatelé nemohli stahovat své hudební soubory. V důsledku toho velká část uživatelů migrovala na jiné výměnné systémy, jako je Gnutella, Kazaa atd.
Později, kolem roku 2008, se Napster stal společností zabývající se prodejem hudby ve formátu MP3 s velkým počtem skladeb ke stažení: free.napster.com.
Nestrukturované P2P sítě
Dalším způsobem sdílení souborů je použití necentralizované sítě, tj. Sítě, kde je vyloučen jakýkoli typ prostředníka mezi uživateli, takže samotná síť má na starosti organizaci komunikace mezi vrstevníky.
V tomto přístupu, pokud je uživatel znám, je mezi nimi vytvořeno „spojení“, aby vytvořilo „síť“, ke které se může připojit více uživatelů. Chcete-li najít soubor, uživatel zadá dotaz, který zaplaví celou síť, aby zjistil maximální počet uživatelů, kteří mají tyto informace.
Například pro provedení vyhledávání v Gnutella vydá zainteresovaný uživatel požadavek na vyhledávání svým sousedům a jejich sousedům. Ale aby se zabránilo zhroucení sítě s malým dotazem, horizont vysílání je omezen na určitou vzdálenost od původního hostitele a také na dobu trvání požadavku, protože pokaždé, když je zpráva předána jinému uživateli, její doba života klesá.
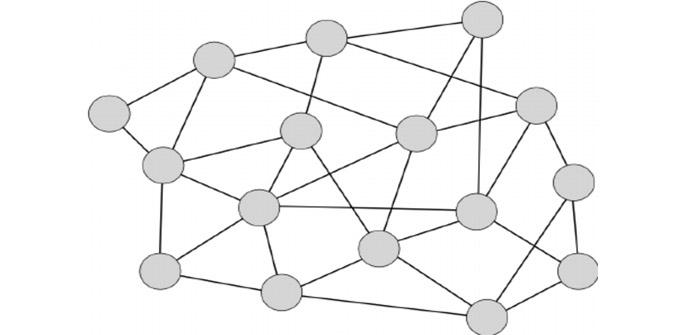
Hlavním problémem tohoto modelu je, že pokud síť poroste, dotazovací zpráva se dostane jen k několika uživatelům. Pokud to, co hledáme, je něco dobře známého, určitě to bude mít jakýkoli hostitel v našem difúzním horizontu, ale na druhou stranu, pokud to, co hledáme, je něco velmi zvláštního, možná to nenajdeme, protože tím, že máme difuzní horizont omezeně, vynecháme hostitele, kteří možná obsahovali informace, které hledáme.
Dodnes byly čisté ne-centralizované P2P sítě nahrazeny novými technologiemi, jako je např Supernody .
SUPERNODOS, hierarchie v nestrukturovaných sítích
Hlavními problémy nestrukturovaných sítí byly difúzní horizont a velikost sítě. Máme dvě možná řešení: buď zvýšíme horizont vysílání, nebo zmenšíme velikost sítě. Pokud se rozhodneme zvětšit horizont vysílání, zvýšíme počet hostitelů, kterým musíme exponenciálně poslat dotazovou zprávu. To by způsobilo, jak jsme již viděli, problémy v síti, například její zhroucení. Naopak, pokud se rozhodneme zmenšit velikost sítě, systémy jsou schopny škálovat mnohem lépe po síti pomocí supernodů.
Hlavní myšlenkou tohoto systému je, že síť je rozdělena mezi četné koncové uzly a malou skupinu dobře připojených supernodů, ke kterým jsou připojeny koncové uzly. Aby bylo možné stát se supernodem, je nutné umět nabídnout dostatek prostředků ostatním uživatelům, zejména šířku pásma. Tato síť supernodů, jejichž součástí se může stát jen několik, je zodpovědná za udržování dostatečně malé velikosti sítě, aby neztratila účinnost při vyhledávání.
Jeho fungování je podobné jako u hybridního modelu, protože koncové uzly jsou připojeny k superuzlům, které přebírají roli serverů, takže uživatelé se připojují pouze k jiným uživatelům, aby prováděli stahování výhradně. Supernodes ukládá informace o tom, co má každý uživatel, aby mohl zkrátit čas hledání a odesílat informace do koncových uzlů, které mají to, co hledáme.
Tento typ struktury je dnes široce používán, hlavně proto, že je velmi užitečný pro výměnu informací o populárním obsahu nebo pro vyhledávání klíčových slov. Vzhledem k tomu, že je síť supernodů omezena, tyto systémy se v síti velmi dobře rozšiřují a nenabízejí zarážky jako hybridní model. Na druhou stranu snižují odolnost proti útokům a výpadkům sítě a ztrácejí přesnost při hledání výsledků kvůli replikaci přes supernody. Pokud selže malý počet supernodů, je síť rozdělena na malé oddíly.
Strukturované P2P sítě
Tento přístup je vyvíjen paralelně s výše popsaným přístupem supernode. Jeho hlavní charakteristikou je, že místo toho, aby se staral o organizaci uzlů, zaměřuje se na organizaci obsahu, seskupování podobného obsahu v síti a vytváření infrastruktury, která mimo jiné umožňuje efektivní vyhledávání.
Partneři mezi sebou organizují novou vrstvu virtuální sítě, „overlay network“, která je umístěna na vrcholu základní P2P sítě. V této překryvné síti je blízkost mezi hostiteli dána jako funkce obsahu, který sdílejí: budou si navzájem bližší, čím více zdrojů společně poskytnou. Tímto způsobem garantujeme, že vyhledávání probíhá efektivně v ne příliš vzdáleném horizontu a bez zmenšení velikosti sítě. Jako příklad lze uvést JXTA, kde partneři jednají ve virtuální síti a mohou se svobodně vytvářet a opouštět skupiny kolegů. Vyhledávací zprávy tedy obvykle zůstávají ve virtuální síti a skupina funguje jako mechanismus seskupování kombinující páry se stejnými nebo podobnými zájmy.
Tento přístup nabízí vysoký výkon a přesné vyhledávání, pokud virtuální síť přesně odráží podobnost mezi uzly s ohledem na vyhledávání. Má však také řadu nevýhod: má vysoké náklady na zřízení a údržbu virtuální sítě v systémech, kde hostitelé vstupují a odcházejí velmi rychle; nejsou příliš vhodné pro vyhledávání zahrnující booleovské operátory, protože by byly potřeba uzly schopné vyhledávat s více než jedním výrazem.
Podtřídou v rámci tohoto typu sítí P2P jsou distribuované hashovací tabulky.
Distribuované hašovací tabulky (DHT)
Hlavní charakteristikou DHT je, že neorganizují síť overlay podle jejího obsahu nebo služeb. Tyto systémy rozdělují celý svůj pracovní prostor pomocí identifikátorů, které jsou přiřazeny kolegům, kteří používají tuto síť, což je činí odpovědnými za malou část celkového pracovního prostoru. Těmito identifikátory mohou být například celá čísla v rozsahu [0, 2n-1], kde n je pevné číslo.
Každá dvojice, která se účastní této sítě, funguje jako malá databáze (sada všech párů by vytvořila distribuovanou databázi). Tato databáze organizuje vaše informace v párech (klíč, hodnota). Abychom ale věděli, který pár má na starosti uložení tohoto páru (klíč, hodnota), potřebujeme, aby klíč byl celé číslo ve stejném rozsahu, se kterým jsou očíslovány zúčastněné páry sítě. Vzhledem k tomu, že klíč nemusí být zastoupen v celých číslech, potřebujeme funkci, která převádí klíče na celá čísla ve stejném rozsahu, s jakým jsou páry očíslovány. Tato funkce je hashovací funkcí. Tato funkce má tu vlastnost, že když je konfrontována s různými vstupy, může poskytnout stejnou výstupní hodnotu, ale s velmi nízkou pravděpodobností. Proto místo mluvení o „distribuované databázi“ hovoříme o tabulce distribuovaných hashů (DHT), protože to, co každá dvojice z páru (klíč, hodnota) ve skutečnosti ukládá, není klíč jako takový, ale hash klíč.
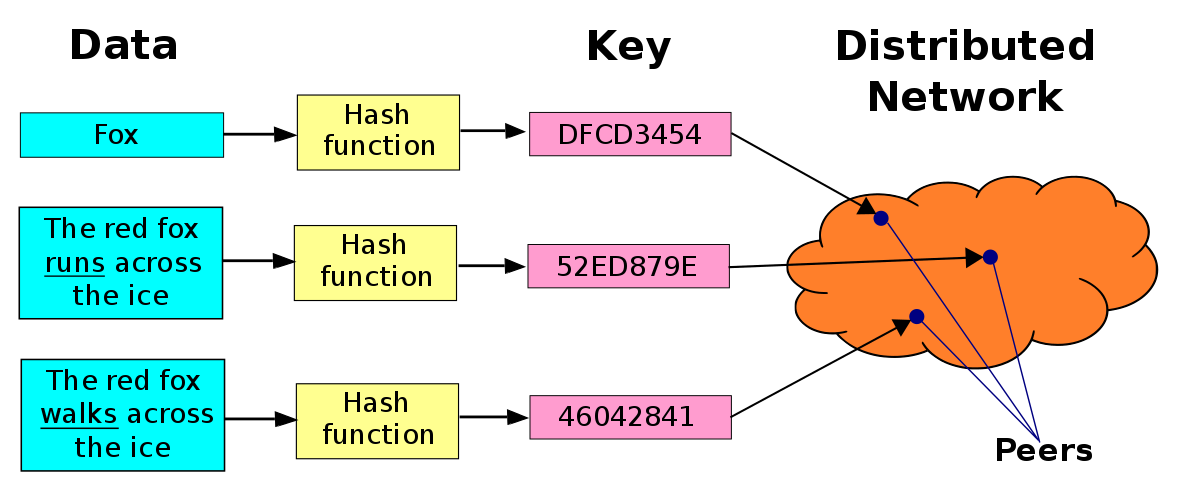
Již jsme diskutovali, že každá dvojice je zodpovědná za část pracovního prostoru v síti. Jak ale namapujete pár (klíč, hodnotu) na správný pár? K tomu se dodržuje pravidlo: jakmile je vypočítán hash klíče, je dvojice (klíč, hodnota) přiřazena dvojici, jejíž identifikátor je nejblíže (okamžitý následník) vypočítané hash. V případě, že vypočítaný hash je větší než identifikátory párů, použije se konvence modulo 2n.
Jakmile jsme si trochu povídali o základním provozu DHT, uvidíme příklad jeho implementace prostřednictvím protokolu CHORD.
Distribuovaný vyhledávací protokol v sítích P2P: CHORD
Chord je jedním z nejpopulárnějších distribuovaných vyhledávacích protokolů v sítích P2P. Tento protokol používá hashovací funkci SHA-1 k přiřazení identifikátoru dvojicím a uloženým informacím. Tyto identifikátory jsou uspořádány do kruhu (přičemž všechny hodnoty jsou modulo 2 m), takže každý uzel ví, kdo je jeho předchůdce a jeho nejbližší bezprostřední následník.
Aby se zachovala škálovatelnost sítě, když uzel opustí síť, všechny jeho klíče předají jeho bezprostřednímu následníkovi, a to takovým způsobem, aby byla síť vždy aktuální, čímž se zabrání tomu, že by vyhledávání mohlo být chybné.
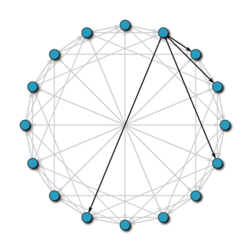
Za účelem nalezení odpovědné osoby, která ukládá klíč, si uzly navzájem posílají zprávy, dokud jej nenajdou. Kvůli kruhovému uspořádání sítě však v nejhorším případě může dotaz pokrýt polovinu uzlů, takže je velmi nákladné jej udržovat. Aby se tomu zabránilo, a tím se snížily náklady, má každý uzel uloženou směrovací tabulku, ve které je uložena adresa uzlů, které jsou v určité vzdálenosti od něj. Tímto způsobem, když chceme vědět, kdo má na starosti klíč k, uzel prohledá svou směrovací tabulku a zjistí, zda má adresu osoby odpovědné za k; pokud ano, pošle vám požadavek přímo; pokud ji nemá, odešle otázku do nejbližšího uzlu k, jehož identifikátor je menší než k.
Díky tomuto vylepšení se nám podařilo snížit náklady na vyhledávání z N / 2 na log N, kde N je číslo síťového uzlu.
Závěry.
Jak jsme viděli, existuje mnoho typů P2P sítí, z nichž každá má své silné a slabé stránky. Žádný nevyniká nad druhým, což umožňuje při programování například aplikace P2P mít několik možností, z nichž každá má své vlastní charakteristiky.
Je třeba mít na paměti jednu věc, jak se vyvíjí způsob sdílení informací. Na konci minulého tisíciletí bylo používání sítí P2P hojné a pro většinu lidí to byl jediný známý způsob sdílení informací. Dnes se trend změnil. Lidé nyní upřednostňují výměnu souborů prostřednictvím velkých serverů, kde v některých případech platí uživatelům za jejich hostování.
Některé otázky, které vám možná přijdou na mysl, jsou: Jaká je budoucnost P2P sítí? K jakým formám organizace informací jsme se vyvinuli?
Jednou z možných evolucí je skok z P2P na p4p. Co je P4P? Jako shrnutí řekneme, že P4P, také známý jako hybridní P2P, je malý vývoj P2P, jehož hlavní charakteristikou je, že poskytovatelé služeb, poskytovatelé internetových služeb, tvoří v síti zásadní roli, protože pokud jde o hledání, hledání nejprve vyhledá mezi zúčastněnými uzly, které patří ke stejnému ISP.
