
Many criticisms have been and surely there will be with the increase in performance in the processors with each generational change. With Intel at the helm we have seen how the performance differences have been minimal for many years, until now. Meanwhile, the GPUs have multiplied their performance several times, how is it possible that this happens when for example in the case of AMD they have used the same lithographic process for processors and graphics cards? What are the reasons?
There are many explanations for this curious disparity, but the main one and the basis of everything is precisely the fate of each type of hardware and how the software approaches it. With this in mind, the range of explanations opens and requires a more thorough study, since we go from the lithographic process to the software developers …
GPUs are always far ahead of CPUs – here’s why

The first reason is logically what processors and graphics cards are made for. As we well know, a CPU is an extremely complex component, the heart of the system, but when we talk about workloads to have a performance gain in a thread and therefore in IPC we have to take into account that a limiting factor is precisely the frequency .
And with it comes the limitation of the node on duty. The improvements of an architecture enhance a much more optimized Front-End and Back-End , together with access to caches and registers usually increase performance, but we cannot forget the parallelism that these modern CPUs require.
If we add all of the above, we have a bottleneck that is always given in the first place by the lithographic process. Including more transistors per mm2 is the most optimal if you want to include more cores and thus increase the overall performance, but at the thread level we have to push a thread at the highest possible frequency. We are currently at 5 GHz with Intel, so if, having this limitation, we apply Amdahl’s Law (a workload is difficult to accelerate and more complexity becomes more complicated, even if it is parallelized) we have a difficulty that can be exponential in certain chores.
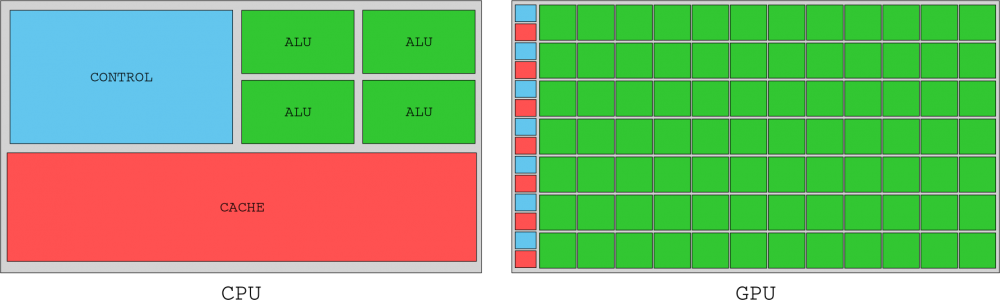
Another point to be discussed is, of course, the executions and instructions that are added to a CPU, where we can optimize and gain performance in a more or less complex way, but they are usually direct improvements in a thread or thread. But of course, a CPU works in parallel with technologies such as speculative or command execution, for example, not to mention the greater number of available cores, caches and access to RAM, or technologies such as HT or SMT.
In the end, all these technologies are trying to do a very simple thing: keep each CPU and thread busy as long as possible and with the most perfect order available for each task, so that there is no delay between data. Why is this the case and how is it different from GPUs?
Super scalarity and parallelization, key in the differences between CPU and GPU
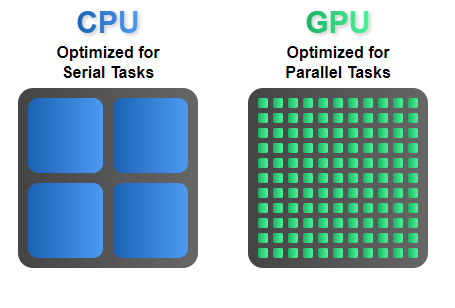
The CPU needs to carry out a large number of different, simple and complex jobs, but it also has to interconnect with any component of the PC, which implies receiving information and transmitting it through different buses and at the highest possible speed. A GPU on the other hand has a different way of working, quite simpler really.
The change of information, in the way of working, is called context change and here the GPU has a lot of gains, since by the nature of these the work they have to do requires very few context changes, since it is extremely parallelizable and the loads are usually homogeneous.
Developers work differently, since a GPU has as many cores as Shaders integrates its silicon, so that parallelizing is tremendously easy because they can integrate up to 6912 real Shaders without too much problem ( NVIDIA A100 ) where each Shader acts as a core almost independent of a CPU.
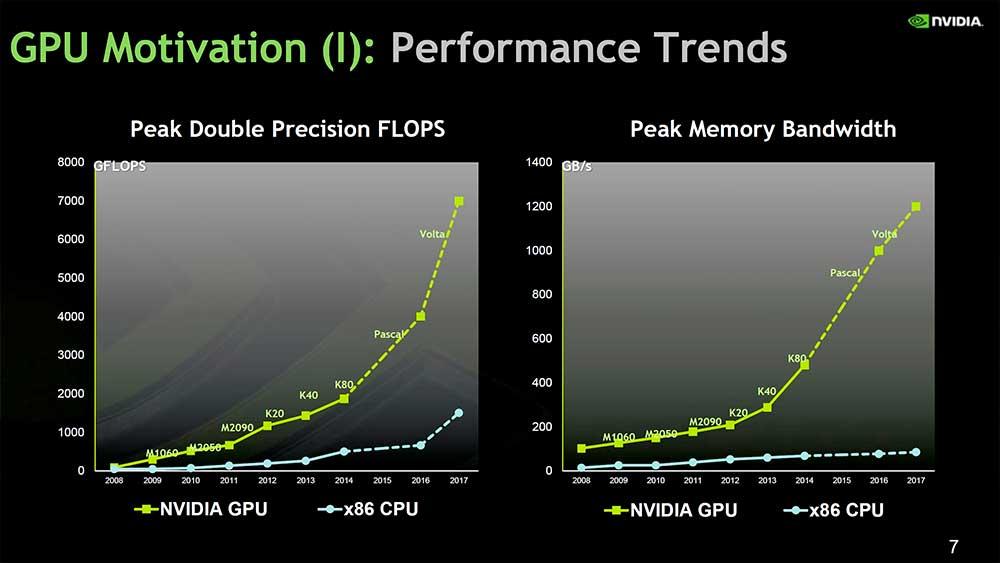
Therefore, we have a large number of cores to work with that are logically limited in performance by the speed of the node for each designed chip and at the same time by the efficiency of the chip. Keep in mind that in GPUs we are talking about huge ten with unthinkable consumption for a CPU.
The trade-off is lower speeds due to the nature of the architecture, but parallelization is unrivaled, so it’s easier to scale performance with it. Finally, we must take into account Dennard’s Law , of which we have already spoken more than once and which precisely takes into account efficiency as the main pillar, where the use of energy is kept in proportion to the area of the chip .
Therefore, if you can parallelize a series of tasks it will be very simple that by adding more cores to a GPU you will be able to scale performance much more, where in addition the number of transistors is much greater and with it the consumption does the same, but it is dissipable. As a GPU does not reach the frequency cap of a node, it is not limited in this aspect, but in efficiency, which, having more margin than a CPU, allows greater gains if we combine everything explained.