Day after day, when it comes to hardware news, we don’t stop reading and listening to information about CPUs, GPUs and even lately dedicated AI processors. But they are not the only existing processors within new devices, be it a conventional PC or a PostPC device. Rather, they are accompanied by other processors that serve as support, which are commonly known as accelerators. We are going to talk about them in this post.
Our computers continually perform concurrent and repetitive tasks that are not performed by the CPU or the GPU, but by units that often go unnoticed when talking about the different hardware architectures and which we are going to talk about next.

The first accelerator in history
In the 1960s, one of the pioneers of computer graphics, Ivan Sutherland, coined the concept “Wheel of Reincarnation” to explain a phenomenon that has occurred even today in the world of hardware.

The computers of that time showing their rudimentary graphics on the oscilloscope that they used as a screen needed to load the X and Y coordinate values where the electron beam had to be placed and send the trace command. The problem they encountered is that each time the CPU had to take care of drawing the screen apart from executing the program.
The solution by Sutherland and his team was what they called “Display List”, which was a separate piece of hardware that read the screen coordinates written by the processor on a part of the screen. In this way, the processor did not have to waste time controlling the electron beam of the oscilloscope or any other type of screen used, the first accelerator in history was born with it.

The development of the Display List as support hardware served for the creation of the first drawing system, the Sketchpad, and from that experience Sutherland published a paper entitled “On the design of Display Processors” where he came to the conclusion that despite the growing Processor power required building support processors to speed up specific tasks performed continuously and repeatedly.
Basic definition of what an accelerator is

When we talk about acceleration, we are referring to increasing the speed at which we travel a distance in a certain space of time. In the hardware world, we call any type of unit accelerator that performs a specific job faster and more efficiently than a complex processor: CPU, GPU, etc. In parallel to this.
Every accelerator meets the following two conditions:
- It occupies a space in the hardware that is several orders of magnitude smaller in area compared to a complex processor.
- Its energy consumption , when performing this task, is miniscule compared to a CPU.
That is, the accelerators win by a landslide in the power / area and power / consumption ratio of any general-purpose processor. Hence, they are used in all types of processors.
Examples of accelerators

We have several examples of accelerators in our computer systems:
- When you take a photo with your mobile and it becomes a file in its storage, the process of converting the image captured by the camera’s CCD is made by an accelerator designed for it.
- When you are playing a movie in a specific video format, the one that decrypts the file to convert it into that succession of images is an accelerator.
- In the world of GPUs, units such as those in charge of filtering textures, rasterizing scene geometry and even intersection units in Ray Tracing are accelerators.
As you can see, they are used for all kinds of applications, types of computer and processors.
Fixed function versus specific purpose accelerators
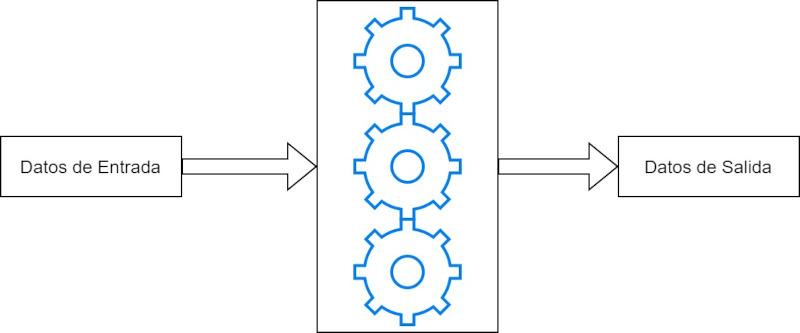
A fixed function unit has its micro-wired instructions, this means that it does not follow a program in a conventional way, but what it does is that, from some input data, it processes them in that only determined way and produces a result.
Although fixed function units have historically been used to accelerate certain tares, these are now in disuse while specific purpose accelerators are increasingly used,
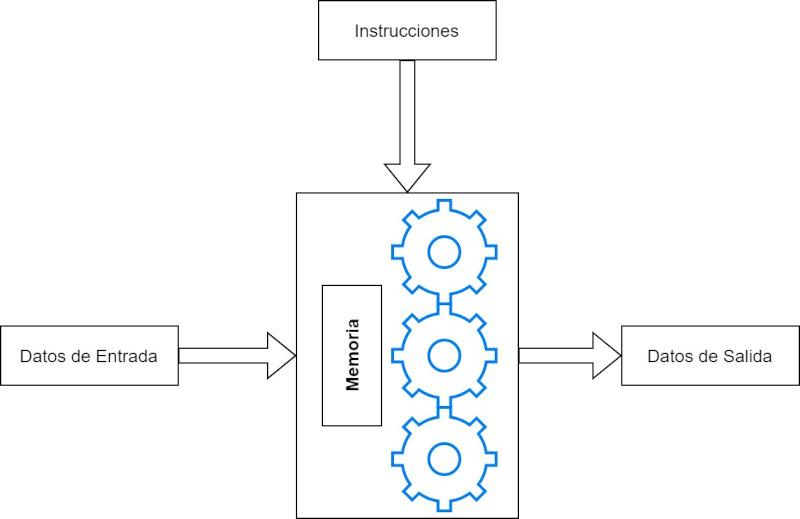
Specific Purpose Accelerators are different in that they do run a program , but they are designed to run that program as efficiently as possible and have been designed exclusively to perform that particular type of task. So they have a control unit and an ALU like every processor and they execute a program in memory.
The advantage that specific-purpose accelerators have over the fixed function is that the list of instructions that they execute to perform said task can be updated, while in the fixed function it cannot and it would be necessary to create a processor from scratch to add improvements in the algorithm they execute.
General Architecture of Specific Purpose Accelerators
We are not going to talk about them one by one, but we are going to talk about how all of them are designed in general and why they are so efficient when doing the tasks for which they have been designed, for this we are going to explain one by one of the different pillars that define this type of unit, regardless of the purpose they serve and for what they have been designed.
First pillar: specialization

When designing the execution units of the CPUs, the ALUs, the architects have to make a compromise in the face of the most complex instructions, since due to lack of space on the chip it is simply not possible to wire all the instructions in the ALU. So the commitment that they make in the design is to do is execute the more complex instructions from other simpler ones.
When an instruction is divided into simpler ones, what we are doing is that the capture-decode-execution process is carried out for each of these instructions.
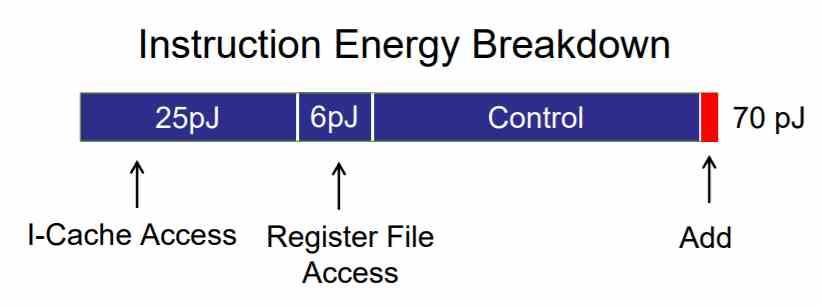
It is precisely the steps of capturing and decoding the instructions that consume the most energy of all, far beyond the simple fact of executing the instruction itself in the ALU.
In accelerators, these complex instructions are integrated into the hardware in such a way that they are executed in the accelerator in far fewer instructions than in a CPU. This reduces the number of accesses made to memory for capturing and subsequent decoding, which implies a much lower energy consumption and eliminates latency between instructions , speeding up the process of executing them.
Second pillar: complexity of the data used
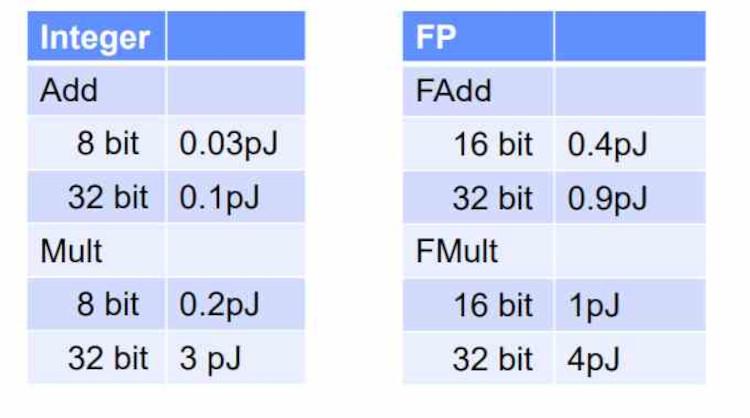
Depending on the type of execution unit used, consumption will be higher or lower, it is not the type of data but the type of ALU that it consumes. What happens if we calculate an 8-bit sum in a 32-bit ALU? Then the power consumption will be that of a 32-bit ALU and not that of an 8-bit ALU.
There are problems that do not require high mathematical precision to be solved, this means that they can be solved using ALUs with simpler precision , which occupy less space and consume less . Therefore, a greater number of ALUs can also be placed to perform these specific tasks, thus increasing the computing power per clock cycle.
It must be taken into account that the ALUs of complex processors such as CPUs have to be wide to be able to execute instructions with high precision data as quickly as possible, but this is a counterpart for tasks that require working with less precision that end up consuming a lot more than they should.
Third pillar: Memory
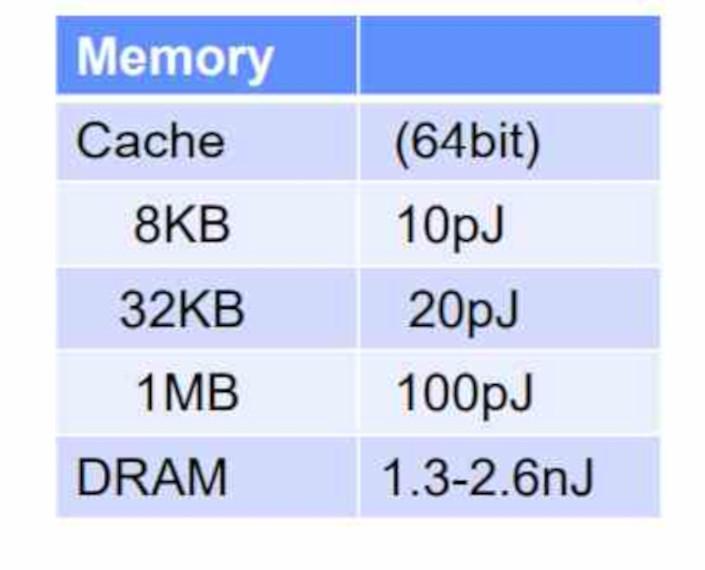
Another reason why they consume so little and can work in parallel is because each accelerator has its own memory , which is not a cache, but a RAM memory inside the accelerator that is exclusive to it.
The accelerator does not have the ability to run anything in the system RAM, does not have access to it, and requires another drive to fetch the data or feed it to you by copying it to your private RAM . It must be taken into account that the energy consumption when accessing a memory the more external it is to the unit in charge of executing the instruction, then the more energy it consumes due to the fact that it travels a greater distance.
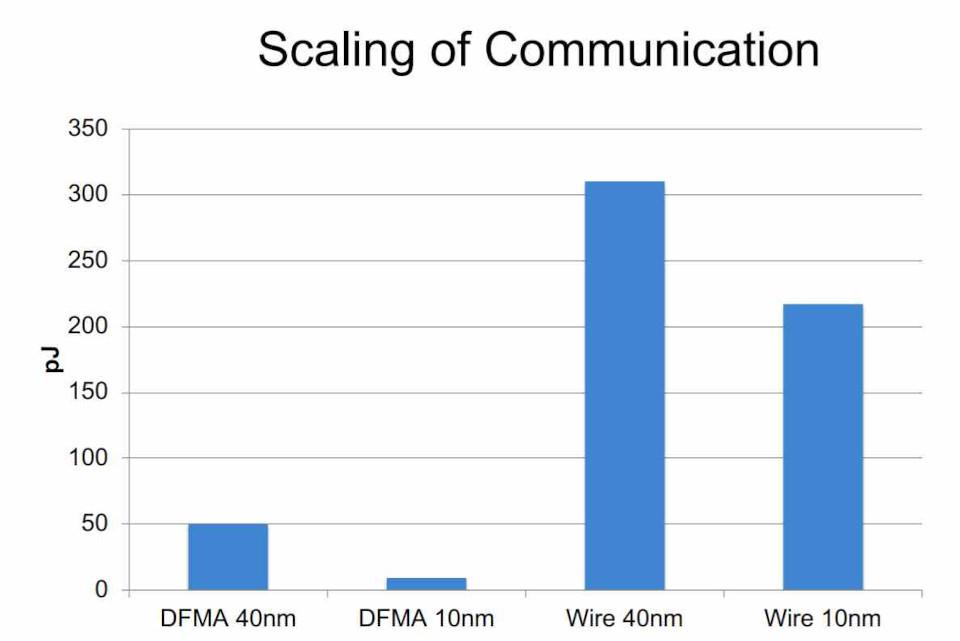
That is why the accelerators are designed so that they do not use the system’s memory but their own exclusively, in addition, the fact of not having to create the data paths so that they access memory continuously greatly simplifies the general design of processors.
The future of accelerators

As Moore’s Law slows down, we find that the old paradigm based on increasing performance with a greater number of cores or with more complex architectures is less and less viable. This forces engineers to think of ways to make processors faster than previous ones, which involves the development of accelerators to speed up specific tasks that run concurrently.
In the future, the performance differences between two architectures that will appear identical on paper will be due exclusively to the action of accelerators. We are even going to see how the processors end up gaining accelerators to execute certain types of instructions that were traditionally executed in the same CPU.