SWAR概念对于许多人来说似乎很陌生,但是如果我们告诉您系统中CPU,GPU的SIMD单元大部分是SWAR类型,那会发生什么? 这些类型的单元不同于传统的SIMD单元,它们起源于90年代后期的多媒体扩展。 它们是什么?它们的用途是什么?
处理器的性能可以通过两种方式来衡量,一方面,它以多快的速度执行串行指令,因此它们不能并行化,因为它们仅影响单位数据。 另一方面,那些可以处理多个数据并且可以并行化的数据。 在CPU和GPU上执行此操作的传统方式? SIMD单元是SWAR单元,其中的一个子类型在CPU和GPU中得到了高度使用。

ALU及其复杂性
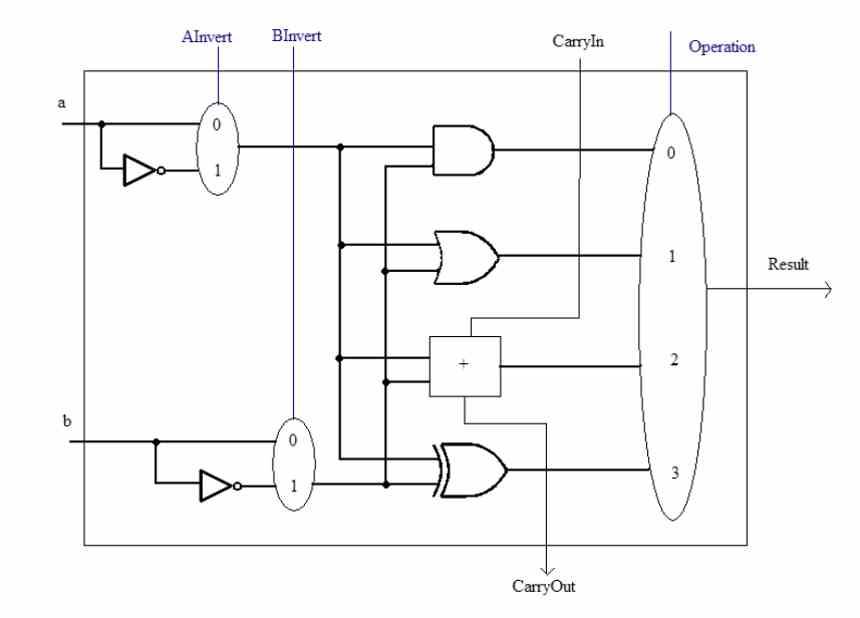
在谈论SWAR概念之前,我们必须牢记ALU是 中央处理器 负责使用不同的数字执行算术和逻辑计算。 它们可以通过两种方式增加复杂性,一种是由于它们必须执行的指令的复杂性。 可以执行例如平方根的计算的ALU内部电路与简单总和的内部电路不同。
另一个是它们工作的精度,即它们每次同时操作的位数。 ALU始终可以处理等于或小于其设计位数的数据。 例如,我们不能使32位数字由16位ALU计算,但是我们可以做相反的事情。
但是,当我们有几个精度较低的数据时会发生什么呢? 通常,它们将以与全精度相同的速度运行,但是有一种方法可以提高它们的速度,这就是过度注册的SIMD。 这也是将晶体管保存在处理器中的一种方法。
什么是SWAR概念?
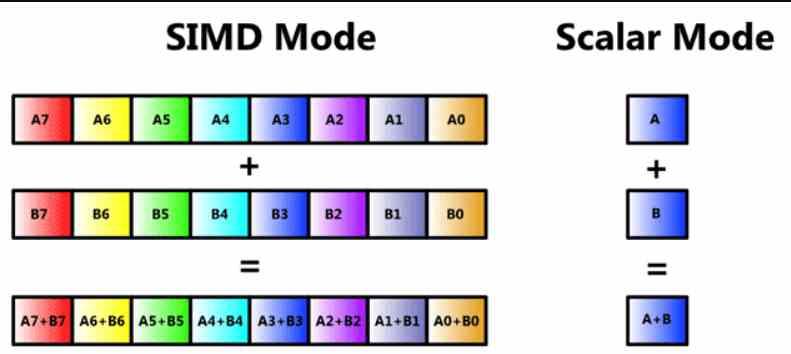
到现在为止,许多读者都知道这是一个SIMD单元,但是我们将对其进行复查,以便没有人从一开始就迷失本文的主题。 SIMD单元是一种ALU,其中通过一条指令同时处理多个数据,因此,有几个ALU共享指令本身及其解码的捕获部分,但每一个中的不同之处一条信息被处理。
SIMD单元通常由几个ALU组成,但是在某些情况下,ALU可以细分为简单的ALU,还有一些将临时存储数据以进行计算的累加寄存器。 这在注册表中称为SIMD或英文SWAR的首字母缩写,这表示寄存器内的SIMD或注册表上的SIMD。
这种类型的SIMD单元使用率很高,并且允许精确的n位ALU执行相同的指令,但使用的数据精度较低。 通常具有一半或四分之一的精度。 例如,通过并行执行所述指令或四个64位指令,可以使32位ALU充当两个16位ALU。
深入了解SWAR概念?
这个概念已经有几十年的历史了,但是它们首次出现在PC上是在90年代后期,当时SIMD单元已经出现在不同类型的处理器中。 这个地方的退伍军人会记住诸如MMX之类的概念, AMD公司 3D Now!,SSE等是在SWAR概念下构建的SIMD单元。
假设我们要构建一个128位SIMD单元
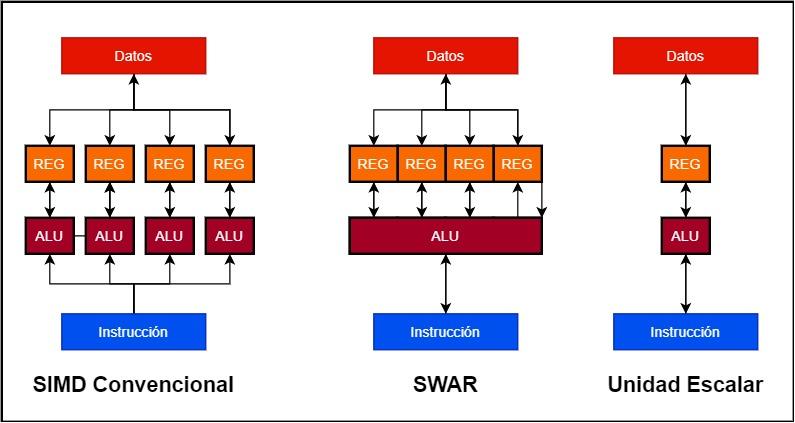
- 在传统的SIMD单元中,我们有几个并行工作的ALU,每个ALU都有自己的数据寄存器或累加器。 因此,一个128位SIMD单元可以由4个32位ALU和4个32位寄存器组成。
- 相反,SWAR单元是单个ALU及其累加器寄存器,可以以很高的精度工作。 这使我们能够使用具有SWAR支持的单个128位ALU来构建SIMD单元。
SWAR类型单元的实现优于标量实现的优点很容易理解,如果ALU不包含SWAR机制,该机制允许它以精度较低的数据作为SIMD单元运行,则它将在同一位置执行它们速度。 比最高精度的数据。 这是什么意思? 如果不支持SWAR,则32位单元必须对16位数据执行相同的指令,其速度将与32位单元相同。 另一方面,如果ALU支持SWAR,则在两个周期相继出现的情况下,它将能够在同一周期内执行两条16位指令。
SWAR作为AI的补丁

人工智能算法具有特殊性,它们往往适用于精度很低的数据,如今大多数ALU都以32位精度运行。 这意味着向处理器添加精确的16位,8位甚至4位ALU,以加快这些算法的速度。 这会使处理器复杂化,但是工程师并没有陷入该错误,而是开始以特定的方式将SIMD移到寄存器上,特别是在GPU上。
是否可以将传统的ALU SIMD与SWAR设计相结合? 是的,这就是AMD所做的,例如,AMD在其RDNA GPU的SIMD单元的每个32位ALU中都支持SIMD over Register,因此可以细分为两个16位,即4 8位或8位中的4位。
在案件 NVIDIA公司,它们给Tensor Core带来了加速AI算法的负担,它们是由在三轴矩阵中相互连接的16位浮点ALU组成的脉动阵列,因此是单位名称。 张量它们不是SIMD单元,但它们的每个ALU均能够以8位精度执行两倍的运算,并以4位精度执行XNUMX倍的运算,因此支持寄存器上的SIMD。 在任何情况下,Tensor单元都很重要,因为它们被设计为以比SIMD单元更高的速度加速矩阵到矩阵的运算。