在他于2019年的演讲中,他谈到了未来 英特尔 Xe体系结构中的Raja Koduri提到了一种英特尔称之为“ Rambo Cache”的内存,这是Intel Xe的关键部分之一。 但是Rambo缓存到底是什么?它的用途是什么? 我们向您解释。
我们如何使大量 GPU 小芯片彼此之间进行有效的沟通? 我们需要一个内存来完成对讲机的工作,这就是Rambo Cache进入的地方。我们将说明其工作方式以及其功能。

Rambo Cache作为Xe-HP和Xe-HPC之间的区别

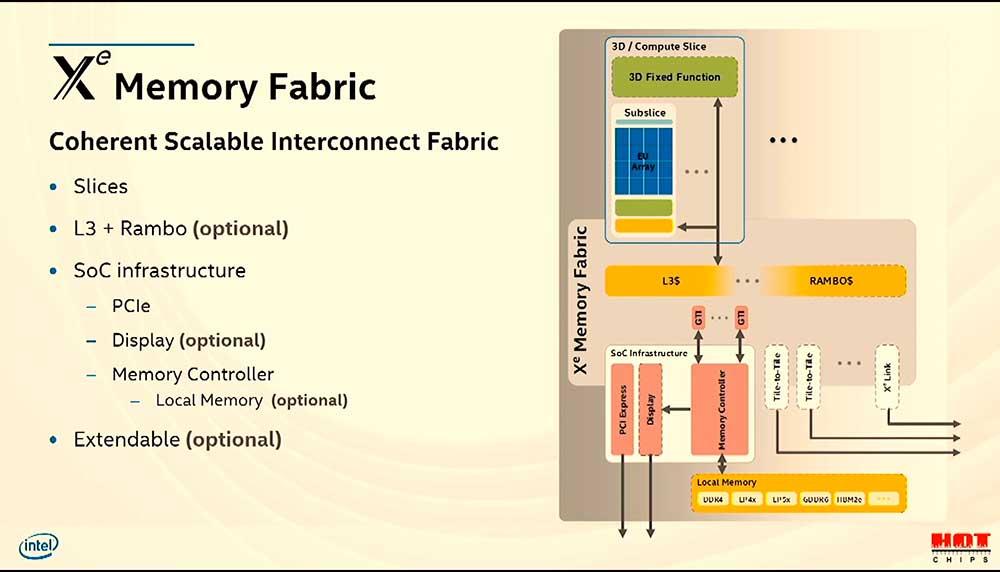
从Intel幻灯片中可以看出,Rambo Cache本身就是一个内部包含内存的芯片,该芯片将专门用于Intel Xe-HPC中不同图块/小芯片之间的通信。 。 尽管Intel Xe-HP最多支持4个不同的磁贴,但是Intel Xe-HPC处理的数据量要高得多,这使得此附加的存储芯片成为进行数据量极其复杂的配置的通信桥所必需。 GPU小芯片或Intel称为它们的图块。

Rambo缓存将放置在多个Intel Xe-HPC Compute Tile之间,以促进它们之间的通信。 Compute Tile只不过是Intel Xe GPU,而是专门用于高性能计算的,因此GPU中的经典固定功能单元将不在Intel Xe-HPC中,因为它们没有用于高性能计算。
但是,Rambo Cache在其余的Intel Xe中将是空前的,尤其是那些不基于Intel Xe-LP和Intel Xe-HPG等几种芯片的缓存。 在Intel Xe-HP的特定情况下,由于Interposer提供了足够的带宽来通信安装在其上的不同小芯片,因此似乎不需要4个小芯片的Rambo Cache。
目标是达到ExaFLOP

我们知道,中介层上的小芯片数量限制为4个GPU,但是从更高的数量来看,是基于EMIB中介层的互连不再提供足够的通信带宽,这使得必须有一个元素来整合访问内存,这就是Rambo缓存的用武之地,因为它可以使Intel制造比其可以使用EMIB最多构建的最多4个小芯片更复杂的GPU。
目的? 能够创建一种组合起来可以达到1 PetaFLOP暴力或1000 TFLOPS暴力的硬件。 性能要比PC中的GPU高得多,但是我们谈论的不是PC的GPU,而是针对超级计算机设计的硬件,目的是达到ExaFLOP的里程碑,即1000 PetaFLOPS,因此达到1百万。 TeraFLOPS。
硬件架构师要实现这一目标的最大关注点是能耗,尤其是在数据传输中,更多的计算更多的数据以及更多的数据移动更多的能量。 这就是为什么保持数据尽可能靠近处理器很重要的原因,这就是Rambo缓存所在的地方。
Rambo缓存作为顶级缓存
当我们有几个核心时,我们是否在谈论一个 中央处理器 或GPU,而我们希望它们所有人都能在寻址和物理级别上很好地访问同一内存,那么就需要最后一级的缓存。 它在GPU中的“地理位置”位置仅在内存控制器之前,但在每个内核的专用缓存之后。
当今的GPU至少具有两级缓存,第一级被剥夺了着色器单元,通常连接到纹理单元。 相反,第二级由GPU的所有元素共享。 在这种情况下,它们是您进行通信,访问最新数据以及所有这些的互连路径,以便不使对VRAM控制器的请求饱和。
但是还有一个附加级别,当我们在同一内存下将几个完整的GPU相互连接时,则需要一个附加级别的缓存来将对所有内存的访问分组。 Intel的Rambo Cache是Intel的解决方案,用于统一对构成Ponte Vecchio的所有GPU的访问。
